 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEB-RANSAC: Random Sample Consensus based on Energy-Based Model
Mar 12, 2026Random sample consensus (RANSAC), which is based on a repetitive sampling from a given dataset, is one of the most popular robust estimation methods. In this study, an energy-based model (EBM) for robust estimation that has a similar scheme to RANSAC, energy-based RANSAC (EB-RANSAC), is proposed. EB-RANSAC is applicable to a wide range of estimation problems similar to RANSAC. However, unlike RANSAC, EB-RANSAC does not require a troublesome sampling procedure and has only one hyperparameter. The effectiveness of EB-RANSAC is numerically demonstrated in two applications: a linear regression and maximum likelihood estimation.
Effective Method for Inverse Ising Problem under Missing Observations in Restricted Boltzmann Machines
Apr 09, 2025Restricted Boltzmann machines (RBMs) are energy-based models analogous to the Ising model and are widely applied in statistical machine learning. The standard inverse Ising problem with a complete dataset requires computing both data and model expectations and is computationally challenging because model expectations have a combinatorial explosion. Furthermore, in many applications, the available datasets are partially incomplete, making it difficult to compute even data expectations. In this study, we propose a approximation framework for these expectations in the practical inverse Ising problems that integrates mean-field approximation or persistent contrastive divergence to generate refined initial points and spatial Monte Carlo integration to enhance estimator accuracy. We demonstrate that the proposed method effectively and accurately tunes the model parameters in comparison to the conventional method.
Dataset-Free Weight-Initialization on Restricted Boltzmann Machine
Sep 12, 2024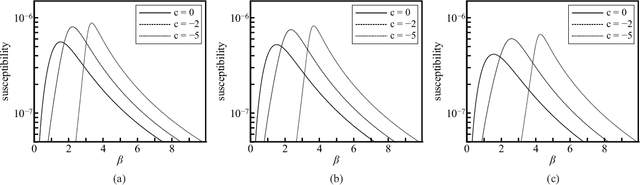
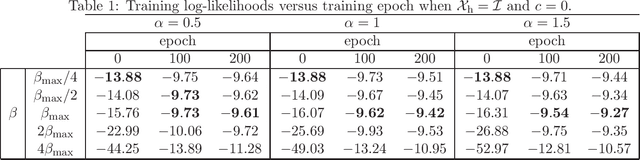
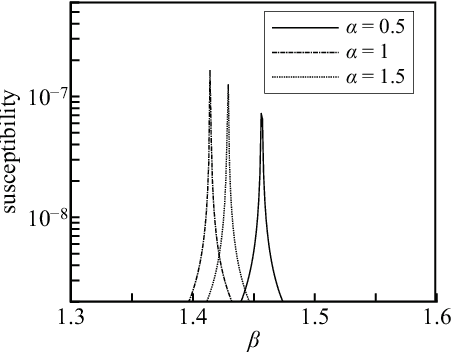
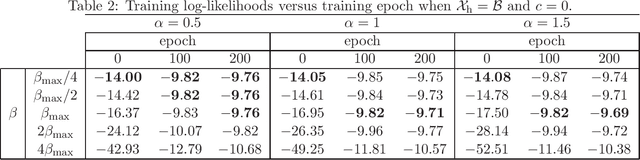
In feed-forward neural networks, dataset-free weight-initialization method such as LeCun, Xavier (or Glorot), and He initializations have been developed. These methods randomly determine the initial values of weight parameters based on specific distributions (e.g., Gaussian or uniform distributions) without using training datasets. To the best of the authors' knowledge, such a dataset-free weight-initialization method is yet to be developed for restricted Boltzmann machines (RBMs), which are probabilistic neural networks consisting of two layers, In this study, we derive a dataset-free weight-initialization method for Bernoulli--Bernoulli RBMs based on a statistical mechanical analysis. In the proposed weight-initialization method, the weight parameters are drawn from a Gaussian distribution with zero mean. The standard deviation of the Gaussian distribution is optimized based on our hypothesis which is that a standard deviation providing a larger layer correlation (LC) between the two layers improves the learning efficiency. The expression of the LC is derived based on a statistical mechanical analysis. The optimal value of the standard deviation corresponds to the maximum point of the LC. The proposed weight-initialization method is identical to Xavier initialization in a specific case (i.e., in the case the sizes of the two layers are the same, the random variables of the layers are $\{-1,1\}$-binary, and all bias parameters are zero).
Improving Interpretability of Scores in Anomaly Detection Based on Gaussian-Bernoulli Restricted Boltzmann Machine
Mar 19, 2024Gaussian-Bernoulli restricted Boltzmann machines (GBRBMs) are often used for semi-supervised anomaly detection, where they are trained using only normal data points. In GBRBM-based anomaly detection, normal and anomalous data are classified based on a score that is identical to an energy function of the marginal GBRBM. However, the classification threshold is difficult to set to an appropriate value, as this score cannot be interpreted. In this study, we propose a measure that improves score's interpretability based on its cumulative distribution, and establish a guideline for setting the threshold using the interpretable measure. The results of numerical experiments show that the guideline is reasonable when setting the threshold solely using normal data points. Moreover, because identifying the measure involves computationally infeasible evaluation of the minimum score value, we also propose an evaluation method for the minimum score based on simulated annealing, which is widely used for optimization problems. The proposed evaluation method was also validated using numerical experiments.
Multi-layered Discriminative Restricted Boltzmann Machine with Untrained Probabilistic Layer
Oct 27, 2022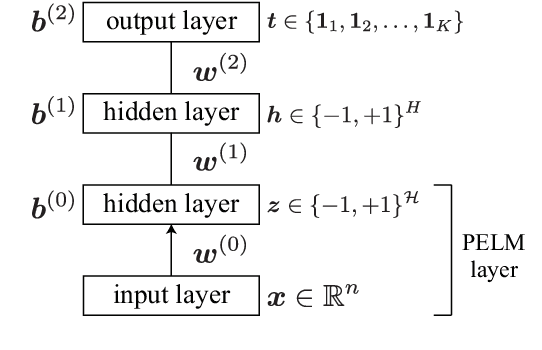
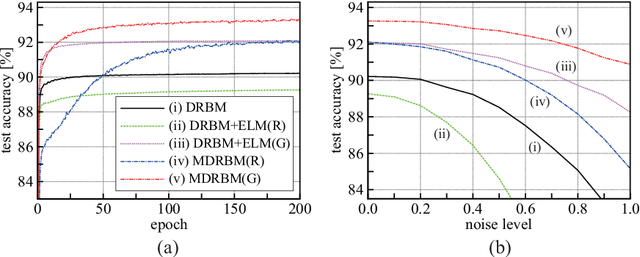
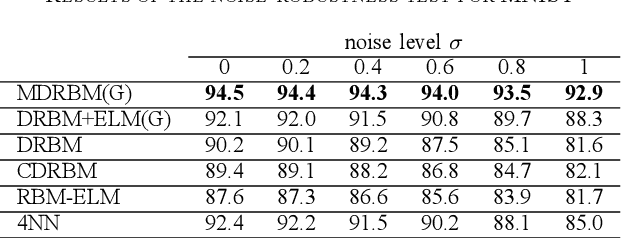
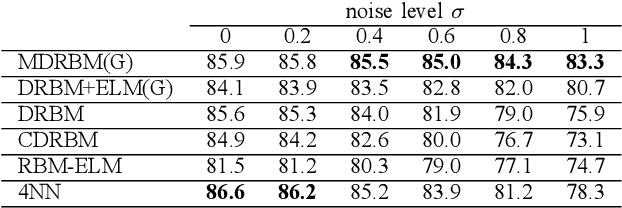
An extreme learning machine (ELM) is a three-layered feed-forward neural network having untrained parameters, which are randomly determined before training. Inspired by the idea of ELM, a probabilistic untrained layer called a probabilistic-ELM (PELM) layer is proposed, and it is combined with a discriminative restricted Boltzmann machine (DRBM), which is a probabilistic three-layered neural network for solving classification problems. The proposed model is obtained by stacking DRBM on the PELM layer. The resultant model (i.e., multi-layered DRBM (MDRBM)) forms a probabilistic four-layered neural network. In MDRBM, the parameters in the PELM layer can be determined using Gaussian-Bernoulli restricted Boltzmann machine. Owing to the PELM layer, MDRBM obtains a strong immunity against noise in inputs, which is one of the most important advantages of MDRBM. Numerical experiments using some benchmark datasets, MNIST, Fashion-MNIST, Urban Land Cover, and CIFAR-10, demonstrate that MDRBM is superior to other existing models, particularly, in terms of the noise-robustness property (or, in other words, the generalization property).
Free Energy Evaluation Using Marginalized Annealed Importance Sampling
Apr 08, 2022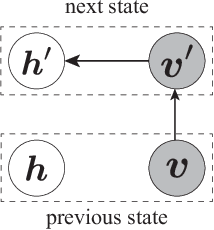

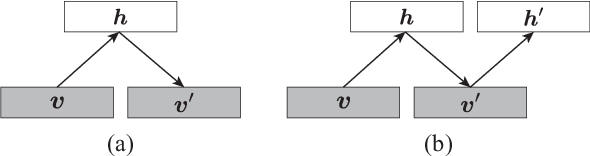
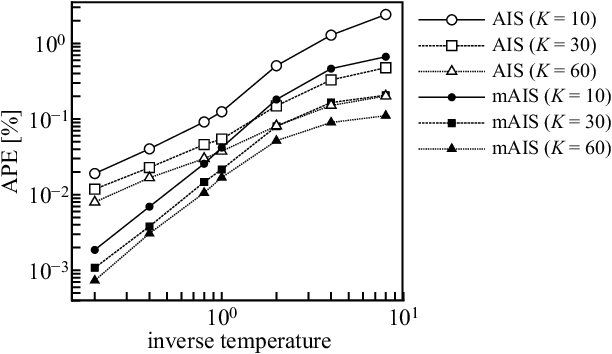
The evaluation of the free energy of a stochastic model is considered to be a significant issue in various fields of physics and machine learning. However, the exact free energy evaluation is computationally infeasible because it includes an intractable partition function. Annealed importance sampling (AIS) is a type of importance sampling based on the Markov chain Monte Carlo method, which is similar to a simulated annealing, and can effectively approximate the free energy. This study proposes a new AIS-based approach, referred to as marginalized AIS (mAIS). The statistical efficiency of mAIS is investigated in detail based on a theoretical and numerical perspectives. Based on the investigation, it has been proved that mAIS is more effective than AIS under a certain condition.
Composite Spatial Monte Carlo Integration Based on Generalized Least Squares
Apr 07, 2022



Although evaluation of the expectations on the Ising model is essential in various applications, this is frequently infeasible because of intractable multiple summations (or integrations). Spatial Monte Carlo integration (SMCI) is a sampling-based approximation, and can provide high-accuracy estimations for such intractable expectations. To evaluate the expectation of a function of variables in a specific region (called target region), SMCI considers a larger region containing the target region (called sum region). In SMCI, the multiple summation for the variables in the sum region is precisely executed, and that in the outer region is evaluated by the sampling approximation such as the standard Monte Carlo integration. It is guaranteed that the accuracy of the SMCI estimator is monotonically improved as the size of the sum region increases. However, a haphazard expansion of the sum region could cause a combinatorial explosion. Therefore, we hope to improve the accuracy without such region expansion. In this study, based on the theory of generalized least squares, a new effective method is proposed by combining multiple SMCI estimators. The validity of the proposed method is demonstrated theoretically and numerically. The results indicate that the proposed method can be effective in the inverse Ising problem (or Boltzmann machine learning).
Spatial Monte Carlo Integration with Annealed Importance Sampling
Dec 21, 2020



Evaluating expectations on a pairwise Boltzmann machine (PBM) (or Ising model) is important for various applications, including the statistical machine learning. However, in general the evaluation is computationally difficult because it involves intractable multiple summations or integrations; therefore, it requires an approximation. Monte Carlo integration (MCI) is a well-known approximation method; a more effective MCI-like approximation method was proposed recently, called spatial Monte Carlo integration (SMCI). However, the estimations obtained from SMCI (and MCI) tend to perform poorly in PBMs with low temperature owing to degradation of the sampling quality. Annealed importance sampling (AIS) is a type of importance sampling based on Markov chain Monte Carlo methods, and it can suppress performance degradation in low temperature regions by the force of importance weights. In this study, a new method is proposed to evaluate the expectations on PBMs combining AIS and SMCI. The proposed method performs efficiently in both high- and low-temperature regions, which is theoretically and numerically demonstrated.
A Generalization of Spatial Monte Carlo Integration
Sep 17, 2020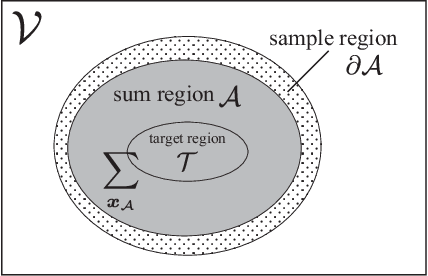
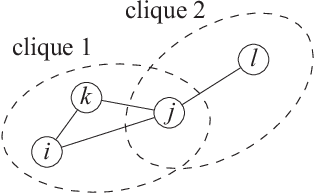

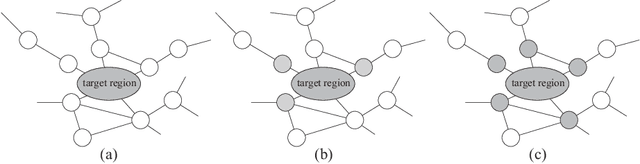
Spatial Monte Carlo integration (SMCI) is an extension of standard Monte Carlo integration and can approximate expectations on Markov random fields with high accuracy. SMCI was applied to pairwise Boltzmann machine (PBM) learning, with superior results to those from some existing methods. The approximation level of SMCI can be changed, and it was proved that a higher-order approximation of SMCI is statistically more accurate than a lower-order approximation. However, SMCI as proposed in the previous studies suffers from a limitation that prevents the application of a higher-order method to dense systems. This study makes two different contributions as follows. A generalization of SMCI (called generalized SMCI (GSMCI)) is proposed, which allows relaxation of the above-mentioned limitation; moreover, a statistical accuracy bound of GSMCI is proved. This is the first contribution of this study. A new PBM learning method based on SMCI is proposed, which is obtained by combining SMCI and the persistent contrastive divergence. The proposed learning method greatly improves the accuracy of learning. This is the second contribution of this study.
Consistent Batch Normalization for Weighted Loss in Imbalanced-Data Environment
Jan 28, 2020



In this study, we consider classification problems based on neural networks in a data-imbalanced environment. Learning from an imbalanced dataset is one of the most important and practical problems in the field of machine learning. A weighted loss function (WLF) based on a cost-sensitive approach is a well-known and effective method for imbalanced datasets. We consider a combination of WLF and batch normalization (BN) in this study. BN is considered as a powerful standard technique in the recent developments in deep learning. A simple combination of both methods leads to a size-inconsistency problem due to a mismatch between the interpretations of the effective size of the dataset in both methods. We propose a simple modification to BN, called weighted batch normalization (WBN), to correct the size-mismatch. The idea of WBN is simple and natural. Using numerical experiments, we demonstrate that our method is effective in a data-imbalanced environment.