 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust, Accountability, and Autonomy in Knowledge Graph-based AI for Self-determination
Oct 31, 2023Knowledge Graphs (KGs) have emerged as fundamental platforms for powering intelligent decision-making and a wide range of Artificial Intelligence (AI) services across major corporations such as Google, Walmart, and AirBnb. KGs complement Machine Learning (ML) algorithms by providing data context and semantics, thereby enabling further inference and question-answering capabilities. The integration of KGs with neuronal learning (e.g., Large Language Models (LLMs)) is currently a topic of active research, commonly named neuro-symbolic AI. Despite the numerous benefits that can be accomplished with KG-based AI, its growing ubiquity within online services may result in the loss of self-determination for citizens as a fundamental societal issue. The more we rely on these technologies, which are often centralised, the less citizens will be able to determine their own destinies. To counter this threat, AI regulation, such as the European Union (EU) AI Act, is being proposed in certain regions. The regulation sets what technologists need to do, leading to questions concerning: How can the output of AI systems be trusted? What is needed to ensure that the data fuelling and the inner workings of these artefacts are transparent? How can AI be made accountable for its decision-making? This paper conceptualises the foundational topics and research pillars to support KG-based AI for self-determination. Drawing upon this conceptual framework, challenges and opportunities for citizen self-determination are illustrated and analysed in a real-world scenario. As a result, we propose a research agenda aimed at accomplishing the recommended objectives.
Intelligent Software Web Agents: A Gap Analysis
Mar 10, 2021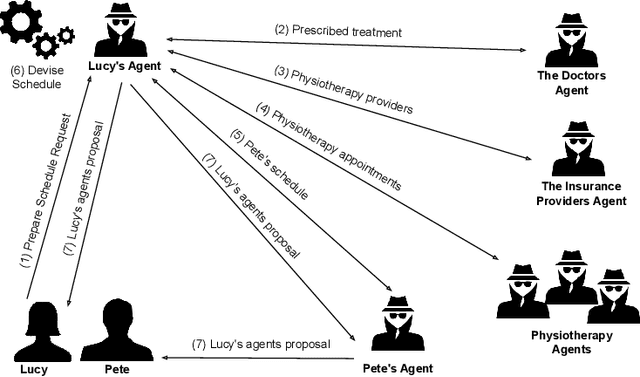
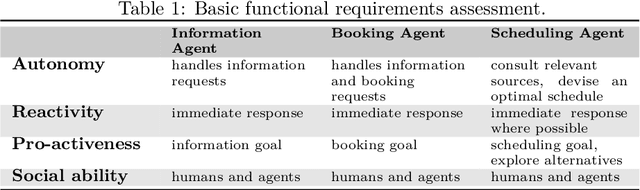
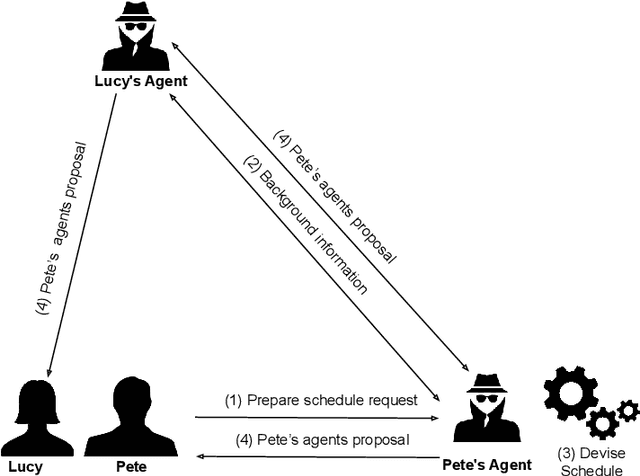
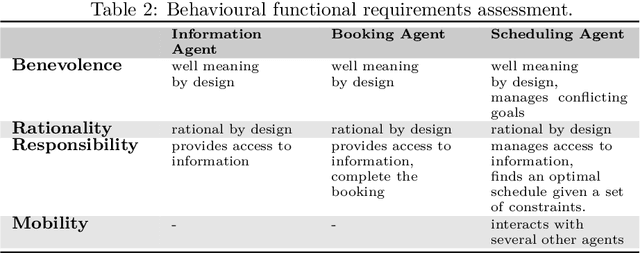
Semantic web technologies have shown their effectiveness, especially when it comes to knowledge representation, reasoning, and data integrations. However, the original semantic web vision, whereby machine readable web data could be automatically actioned upon by intelligent software web agents, has yet to be realised. In order to better understand the existing technological challenges and opportunities, in this paper we examine the status quo in terms of intelligent software web agents, guided by research with respect to requirements and architectural components, coming from that agents community. We start by collating and summarising requirements and core architectural components relating to intelligent software agent. Following on from this, we use the identified requirements to both further elaborate on the semantic web agent motivating use case scenario, and to summarise different perspectives on the requirements when it comes to semantic web agent literature. Finally, we propose a hybrid semantic web agent architecture, discuss the role played by existing semantic web standards, and point to existing work in the broader semantic web community and beyond that could help us to make the semantic web agent vision a reality.
Why model why? Assessing the strengths and limitations of LIME
Nov 30, 2020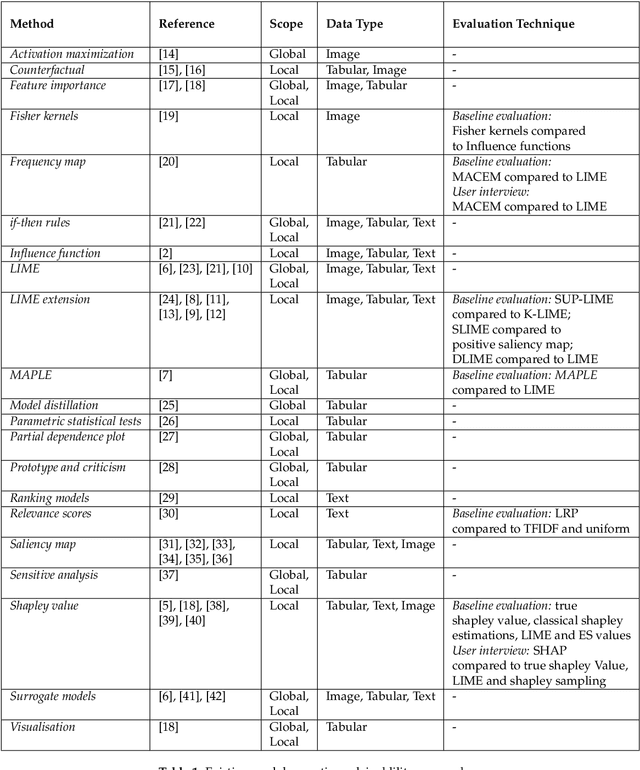
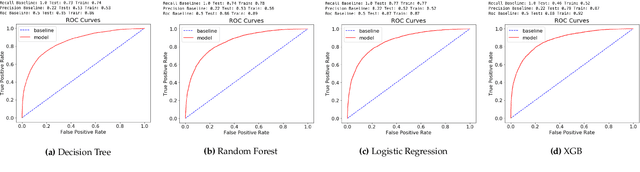
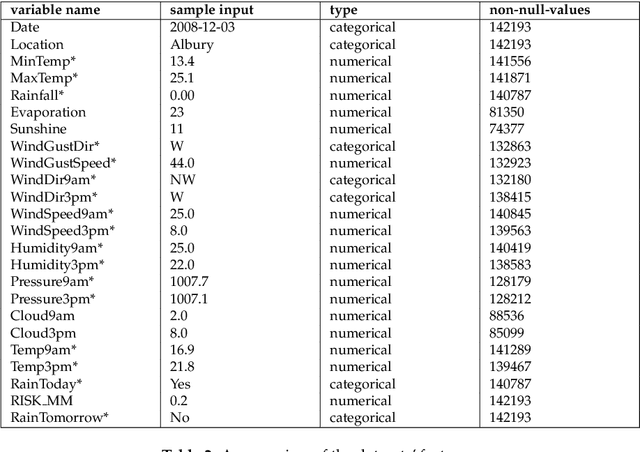
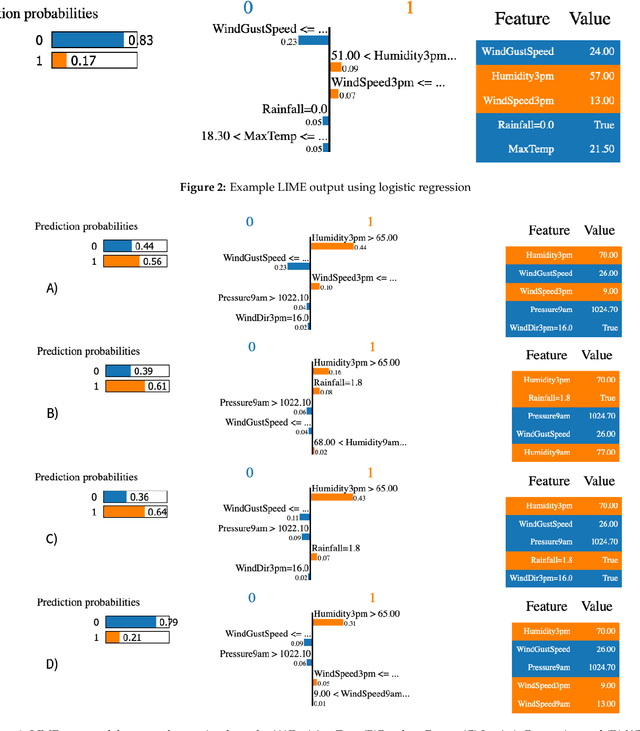
When it comes to complex machine learning models, commonly referred to as black boxes, understanding the underlying decision making process is crucial for domains such as healthcare and financial services, and also when it is used in connection with safety critical systems such as autonomous vehicles. As such interest in explainable artificial intelligence (xAI) tools and techniques has increased in recent years. However, the effectiveness of existing xAI frameworks, especially concerning algorithms that work with data as opposed to images, is still an open research question. In order to address this gap, in this paper we examine the effectiveness of the Local Interpretable Model-Agnostic Explanations (LIME) xAI framework, one of the most popular model agnostic frameworks found in the literature, with a specific focus on its performance in terms of making tabular models more interpretable. In particular, we apply several state of the art machine learning algorithms on a tabular dataset, and demonstrate how LIME can be used to supplement conventional performance assessment methods. In addition, we evaluate the understandability of the output produced by LIME both via a usability study, involving participants who are not familiar with LIME, and its overall usability via an assessment framework, which is derived from the International Organisation for Standardisation 9241-11:1998 standard.
Knowledge Graphs
Mar 28, 2020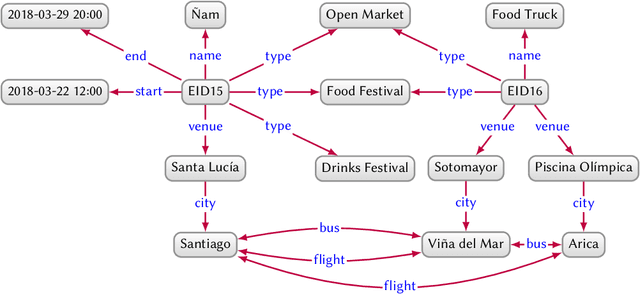
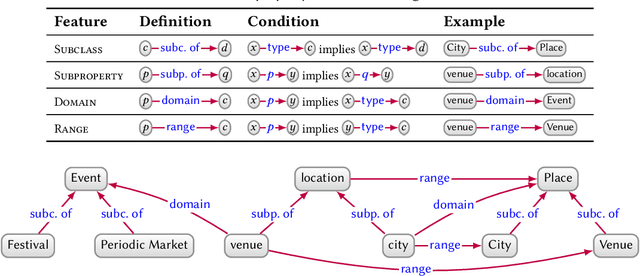
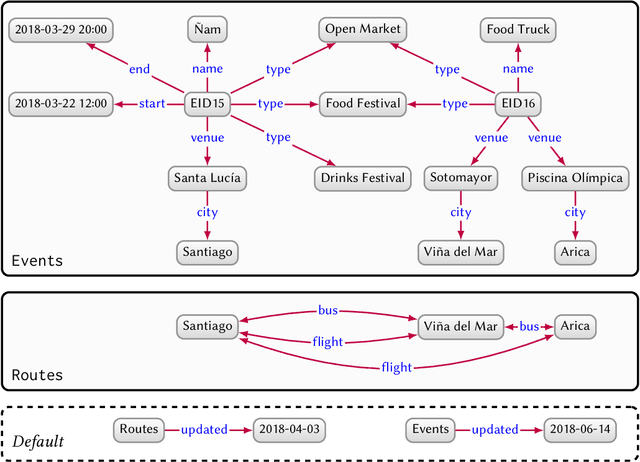
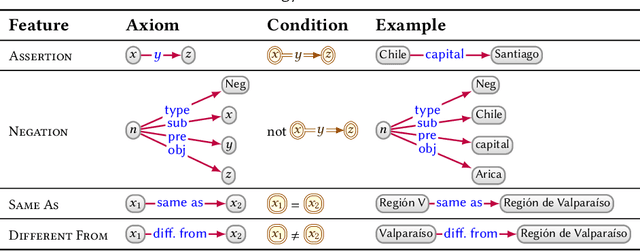
In this paper we provide a comprehensive introduction to knowledge graphs, which have recently garnered significant attention from both industry and academia in scenarios that require exploiting diverse, dynamic, large-scale collections of data. After a general introduction, we motivate and contrast various graph-based data models and query languages that are used for knowledge graphs. We discuss the roles of schema, identity, and context in knowledge graphs. We explain how knowledge can be represented and extracted using a combination of deductive and inductive techniques. We summarise methods for the creation, enrichment, quality assessment, refinement, and publication of knowledge graphs. We provide an overview of prominent open knowledge graphs and enterprise knowledge graphs, their applications, and how they use the aforementioned techniques. We conclude with high-level future research directions for knowledge graphs.
The SPECIAL-K Personal Data Processing Transparency and Compliance Platform
Jan 26, 2020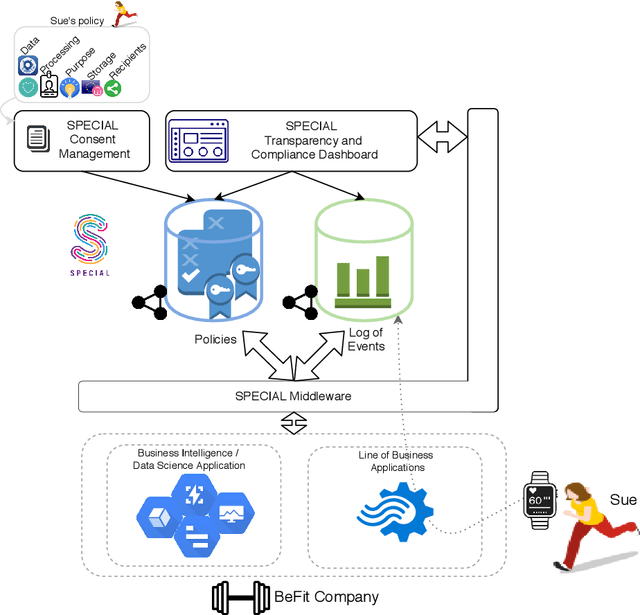
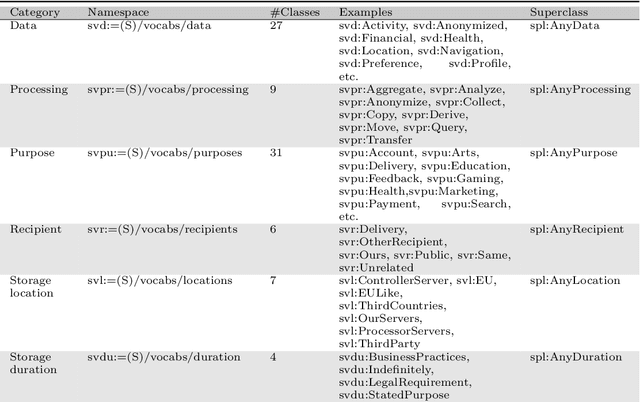
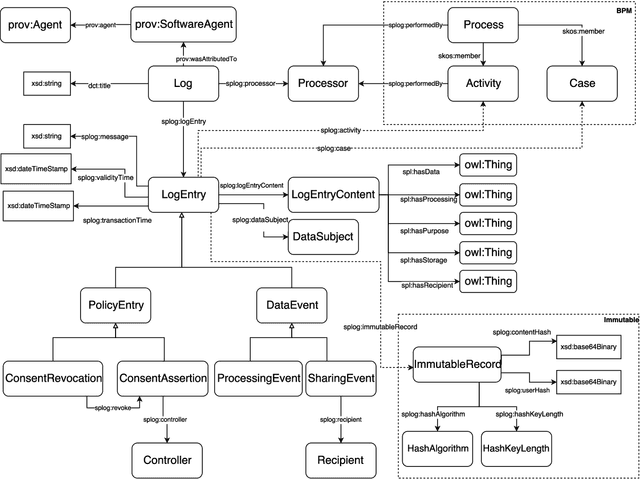

The European General Data Protection Regulation (GDPR) brings new challenges for companies, who must provide transparency with respect to personal data processing and sharing within and between organisations. Additionally companies need to demonstrate that their systems and business processes comply with usage constraints specified by data subjects. This paper first presents the Linked Data ontologies and vocabularies developed within the SPECIAL EU H2020 project, which can be used to represent data usage policies and data processing and sharing events, including the consent provided by the data subject and subsequent changes to or revocation of said consent. Following on from this, we propose a concrete transparency and compliance architecture, referred to as SPECIAL-K, that can automatically verify that data processing and sharing complies with the relevant usage control policies. Our evaluation, based on a new transparency and compliance benchmark, shows the efficiency and scalability of the system with increasing number of events and users, covering a wide range of real-world streaming and batch processing scenarios.
Machine Understandable Policies and GDPR Compliance Checking
Jan 24, 2020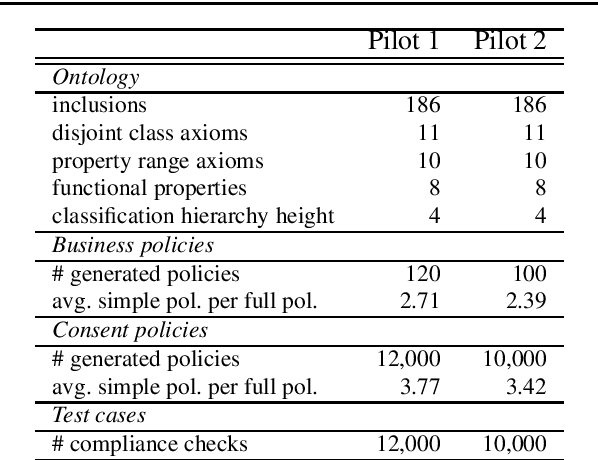

The European General Data Protection Regulation (GDPR) calls for technical and organizational measures to support its implementation. Towards this end, the SPECIAL H2020 project aims to provide a set of tools that can be used by data controllers and processors to automatically check if personal data processing and sharing complies with the obligations set forth in the GDPR. The primary contributions of the project include: (i) a policy language that can be used to express consent, business policies, and regulatory obligations; and (ii) two different approaches to automated compliance checking that can be used to demonstrate that data processing performed by data controllers / processors complies with consent provided by data subjects, and business processes comply with regulatory obligations set forth in the GDPR.