 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Web and Creative AI -- A Technical Report from ISWS 2023
Jan 30, 2025



The International Semantic Web Research School (ISWS) is a week-long intensive program designed to immerse participants in the field. This document reports a collaborative effort performed by ten teams of students, each guided by a senior researcher as their mentor, attending ISWS 2023. Each team provided a different perspective to the topic of creative AI, substantiated by a set of research questions as the main subject of their investigation. The 2023 edition of ISWS focuses on the intersection of Semantic Web technologies and Creative AI. ISWS 2023 explored various intersections between Semantic Web technologies and creative AI. A key area of focus was the potential of LLMs as support tools for knowledge engineering. Participants also delved into the multifaceted applications of LLMs, including legal aspects of creative content production, humans in the loop, decentralised approaches to multimodal generative AI models, nanopublications and AI for personal scientific knowledge graphs, commonsense knowledge in automatic story and narrative completion, generative AI for art critique, prompt engineering, automatic music composition, commonsense prototyping and conceptual blending, and elicitation of tacit knowledge. As Large Language Models and semantic technologies continue to evolve, new exciting prospects are emerging: a future where the boundaries between creative expression and factual knowledge become increasingly permeable and porous, leading to a world of knowledge that is both informative and inspiring.
Large Language Models, Knowledge Graphs and Search Engines: A Crossroads for Answering Users' Questions
Jan 12, 2025Much has been discussed about how Large Language Models, Knowledge Graphs and Search Engines can be combined in a synergistic manner. A dimension largely absent from current academic discourse is the user perspective. In particular, there remain many open questions regarding how best to address the diverse information needs of users, incorporating varying facets and levels of difficulty. This paper introduces a taxonomy of user information needs, which guides us to study the pros, cons and possible synergies of Large Language Models, Knowledge Graphs and Search Engines. From this study, we derive a roadmap for future research.
Question Answering over Knowledge Graphs with Neural Machine Translation and Entity Linking
Jul 06, 2021
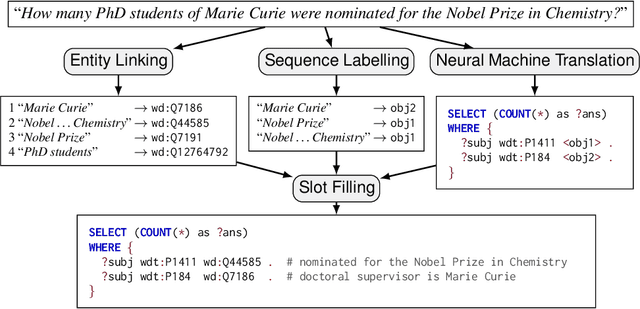


The goal of Question Answering over Knowledge Graphs (KGQA) is to find answers for natural language questions over a knowledge graph. Recent KGQA approaches adopt a neural machine translation (NMT) approach, where the natural language question is translated into a structured query language. However, NMT suffers from the out-of-vocabulary problem, where terms in a question may not have been seen during training, impeding their translation. This issue is particularly problematic for the millions of entities that large knowledge graphs describe. We rather propose a KGQA approach that delegates the processing of entities to entity linking (EL) systems. NMT is then used to create a query template with placeholders that are filled by entities identified in an EL phase. Slot filling is used to decide which entity fills which placeholder. Experiments for QA over Wikidata show that our approach outperforms pure NMT: while there remains a strong dependence on having seen similar query templates during training, errors relating to entities are greatly reduced.
Knowledge Graphs
Mar 28, 2020
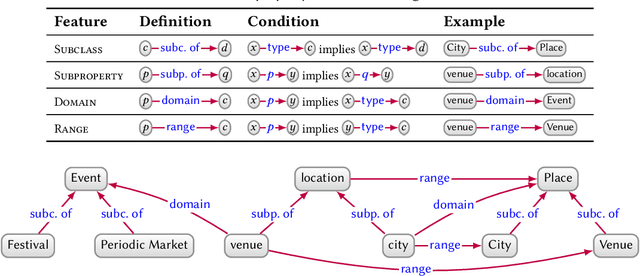
In this paper we provide a comprehensive introduction to knowledge graphs, which have recently garnered significant attention from both industry and academia in scenarios that require exploiting diverse, dynamic, large-scale collections of data. After a general introduction, we motivate and contrast various graph-based data models and query languages that are used for knowledge graphs. We discuss the roles of schema, identity, and context in knowledge graphs. We explain how knowledge can be represented and extracted using a combination of deductive and inductive techniques. We summarise methods for the creation, enrichment, quality assessment, refinement, and publication of knowledge graphs. We provide an overview of prominent open knowledge graphs and enterprise knowledge graphs, their applications, and how they use the aforementioned techniques. We conclude with high-level future research directions for knowledge graphs.
OWL: Yet to arrive on the Web of Data?
Feb 01, 2012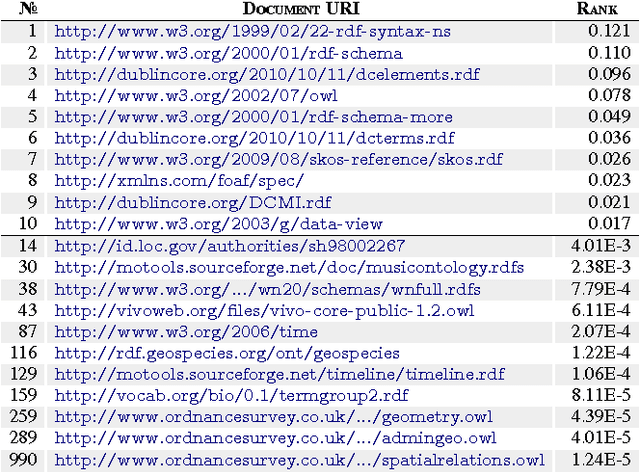
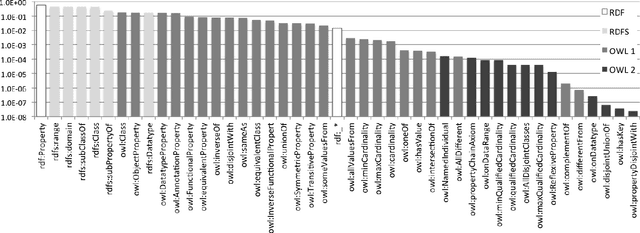
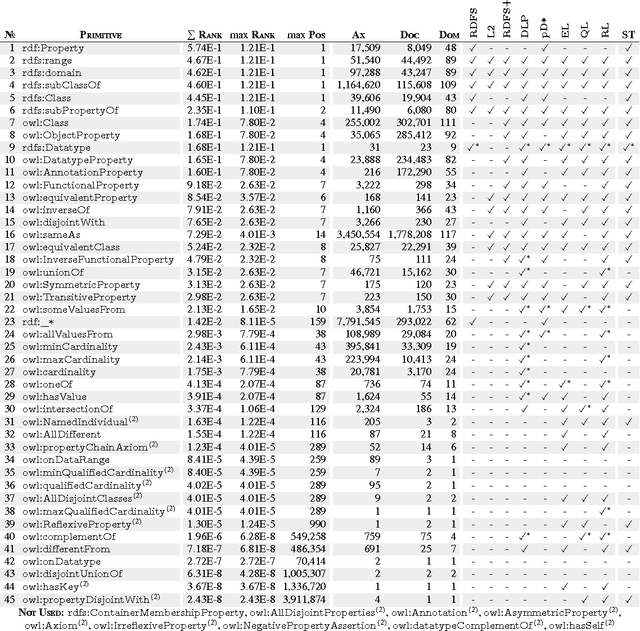
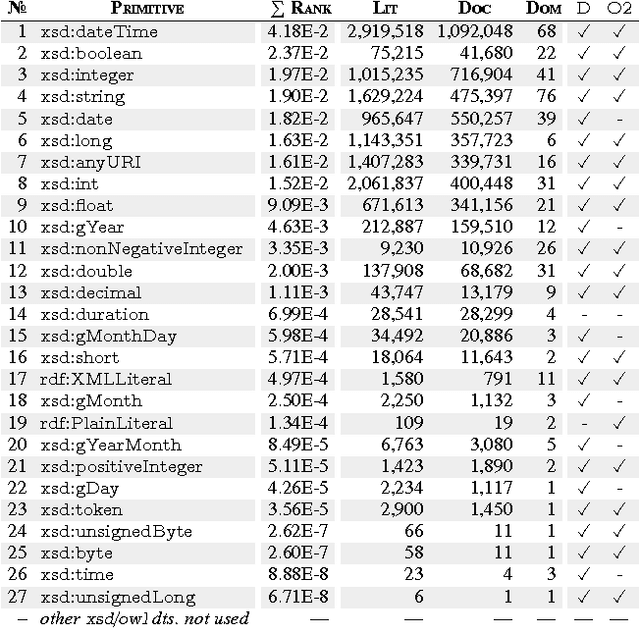
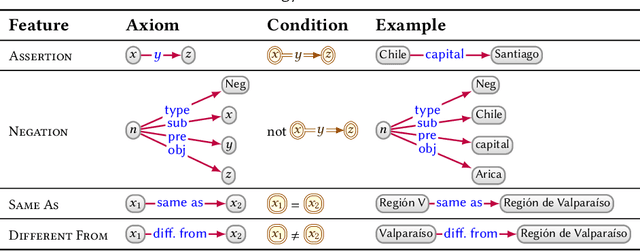
Seven years on from OWL becoming a W3C recommendation, and two years on from the more recent OWL 2 W3C recommendation, OWL has still experienced only patchy uptake on the Web. Although certain OWL features (like owl:sameAs) are very popular, other features of OWL are largely neglected by publishers in the Linked Data world. This may suggest that despite the promise of easy implementations and the proposal of tractable profiles suggested in OWL's second version, there is still no "right" standard fragment for the Linked Data community. In this paper, we (1) analyse uptake of OWL on the Web of Data, (2) gain insights into the OWL fragment that is actually used/usable on the Web, where we arrive at the conclusion that this fragment is likely to be a simplified profile based on OWL RL, (3) propose and discuss such a new fragment, which we call OWL LD (for Linked Data).