 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe ReQAP System for Question Answering over Personal Information
Aug 09, 2025Personal information is abundant on users' devices, from structured data in calendar, shopping records or fitness tools, to unstructured contents in mail and social media posts. This works presents the ReQAP system that supports users with answers for complex questions that involve filters, joins and aggregation over heterogeneous sources. The unique trait of ReQAP is that it recursively decomposes questions and incrementally builds an operator tree for execution. Both the question interpretation and the individual operators make smart use of light-weight language models, with judicious fine-tuning. The demo showcases the rich functionality for advanced user questions, and also offers detailed tracking of how the answers are computed by the operators in the execution tree. Being able to trace answers back to the underlying sources is vital for human comprehensibility and user trust in the system.
Recursive Question Understanding for Complex Question Answering over Heterogeneous Personal Data
May 17, 2025Question answering over mixed sources, like text and tables, has been advanced by verbalizing all contents and encoding it with a language model. A prominent case of such heterogeneous data is personal information: user devices log vast amounts of data every day, such as calendar entries, workout statistics, shopping records, streaming history, and more. Information needs range from simple look-ups to queries of analytical nature. The challenge is to provide humans with convenient access with small footprint, so that all personal data stays on the user devices. We present ReQAP, a novel method that creates an executable operator tree for a given question, via recursive decomposition. Operators are designed to enable seamless integration of structured and unstructured sources, and the execution of the operator tree yields a traceable answer. We further release the PerQA benchmark, with persona-based data and questions, covering a diverse spectrum of realistic user needs.
Preference-based Learning with Retrieval Augmented Generation for Conversational Question Answering
Mar 28, 2025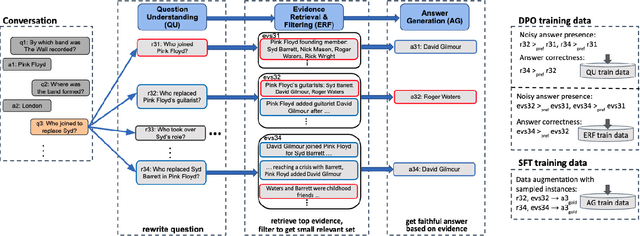
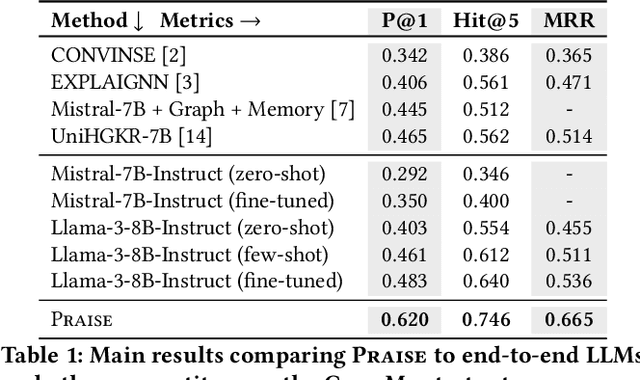
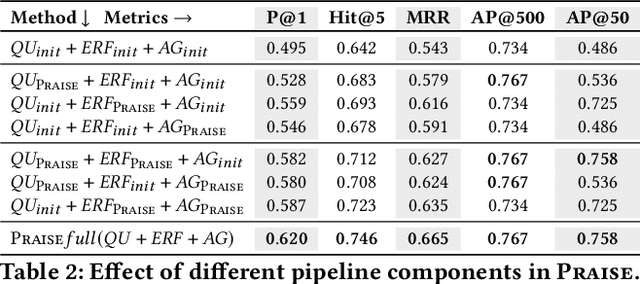
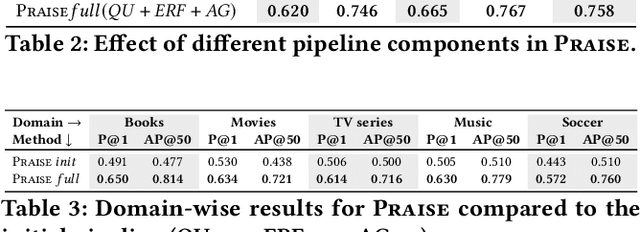
Conversational Question Answering (ConvQA) involves multiple subtasks, i) to understand incomplete questions in their context, ii) to retrieve relevant information, and iii) to generate answers. This work presents PRAISE, a pipeline-based approach for ConvQA that trains LLM adapters for each of the three subtasks. As labeled training data for individual subtasks is unavailable in practice, PRAISE learns from its own generations using the final answering performance as feedback signal without human intervention and treats intermediate information, like relevant evidence, as weakly labeled data. We apply Direct Preference Optimization by contrasting successful and unsuccessful samples for each subtask. In our experiments, we show the effectiveness of this training paradigm: PRAISE shows improvements per subtask and achieves new state-of-the-art performance on a popular ConvQA benchmark, by gaining 15.5 percentage points increase in precision over baselines.
Large Language Models, Knowledge Graphs and Search Engines: A Crossroads for Answering Users' Questions
Jan 12, 2025Much has been discussed about how Large Language Models, Knowledge Graphs and Search Engines can be combined in a synergistic manner. A dimension largely absent from current academic discourse is the user perspective. In particular, there remain many open questions regarding how best to address the diverse information needs of users, incorporating varying facets and levels of difficulty. This paper introduces a taxonomy of user information needs, which guides us to study the pros, cons and possible synergies of Large Language Models, Knowledge Graphs and Search Engines. From this study, we derive a roadmap for future research.
RAG-based Question Answering over Heterogeneous Data and Text
Dec 10, 2024This article presents the QUASAR system for question answering over unstructured text, structured tables, and knowledge graphs, with unified treatment of all sources. The system adopts a RAG-based architecture, with a pipeline of evidence retrieval followed by answer generation, with the latter powered by a moderate-sized language model. Additionally and uniquely, QUASAR has components for question understanding, to derive crisper input for evidence retrieval, and for re-ranking and filtering the retrieved evidence before feeding the most informative pieces into the answer generation. Experiments with three different benchmarks demonstrate the high answering quality of our approach, being on par with or better than large GPT models, while keeping the computational cost and energy consumption orders of magnitude lower.
Recall Them All: Retrieval-Augmented Language Models for Long Object List Extraction from Long Documents
May 04, 2024



Methods for relation extraction from text mostly focus on high precision, at the cost of limited recall. High recall is crucial, though, to populate long lists of object entities that stand in a specific relation with a given subject. Cues for relevant objects can be spread across many passages in long texts. This poses the challenge of extracting long lists from long texts. We present the L3X method which tackles the problem in two stages: (1) recall-oriented generation using a large language model (LLM) with judicious techniques for retrieval augmentation, and (2) precision-oriented scrutinization to validate or prune candidates. Our L3X method outperforms LLM-only generations by a substantial margin.
Faithful Temporal Question Answering over Heterogeneous Sources
Feb 23, 2024Temporal question answering (QA) involves time constraints, with phrases such as "... in 2019" or "... before COVID". In the former, time is an explicit condition, in the latter it is implicit. State-of-the-art methods have limitations along three dimensions. First, with neural inference, time constraints are merely soft-matched, giving room to invalid or inexplicable answers. Second, questions with implicit time are poorly supported. Third, answers come from a single source: either a knowledge base (KB) or a text corpus. We propose a temporal QA system that addresses these shortcomings. First, it enforces temporal constraints for faithful answering with tangible evidence. Second, it properly handles implicit questions. Third, it operates over heterogeneous sources, covering KB, text and web tables in a unified manner. The method has three stages: (i) understanding the question and its temporal conditions, (ii) retrieving evidence from all sources, and (iii) faithfully answering the question. As implicit questions are sparse in prior benchmarks, we introduce a principled method for generating diverse questions. Experiments show superior performance over a suite of baselines.
Multi-Cultural Commonsense Knowledge Distillation
Feb 16, 2024



Despite recent progress, large language models (LLMs) still face the challenge of appropriately reacting to the intricacies of social and cultural conventions. This paper presents MANGO, a methodology for distilling high-accuracy, high-recall assertions of cultural knowledge. We judiciously and iteratively prompt LLMs for this purpose from two entry points, concepts and cultures. Outputs are consolidated via clustering and generative summarization. Running the MANGO method with GPT-3.5 as underlying LLM yields 167K high-accuracy assertions for 30K concepts and 11K cultures, surpassing prior resources by a large margin. For extrinsic evaluation, we explore augmenting dialogue systems with cultural knowledge assertions. We find that adding knowledge from MANGO improves the overall quality, specificity, and cultural sensitivity of dialogue responses, as judged by human annotators. Data and code are available for download.
Recommendations by Concise User Profiles from Review Text
Nov 02, 2023Recommender systems are most successful for popular items and users with ample interactions (likes, ratings etc.). This work addresses the difficult and underexplored case of supporting users who have very sparse interactions but post informative review texts. Our experimental studies address two book communities with these characteristics. We design a framework with Transformer-based representation learning, covering user-item interactions, item content, and user-provided reviews. To overcome interaction sparseness, we devise techniques for selecting the most informative cues to construct concise user profiles. Comprehensive experiments, with datasets from Amazon and Goodreads, show that judicious selection of text snippets achieves the best performance, even in comparison to ChatGPT-generated user profiles.
Evaluating the Knowledge Base Completion Potential of GPT
Oct 23, 2023Structured knowledge bases (KBs) are an asset for search engines and other applications, but are inevitably incomplete. Language models (LMs) have been proposed for unsupervised knowledge base completion (KBC), yet, their ability to do this at scale and with high accuracy remains an open question. Prior experimental studies mostly fall short because they only evaluate on popular subjects, or sample already existing facts from KBs. In this work, we perform a careful evaluation of GPT's potential to complete the largest public KB: Wikidata. We find that, despite their size and capabilities, models like GPT-3, ChatGPT and GPT-4 do not achieve fully convincing results on this task. Nonetheless, they provide solid improvements over earlier approaches with smaller LMs. In particular, we show that, with proper thresholding, GPT-3 enables to extend Wikidata by 27M facts at 90% precision.
* 12 pages 4 tables