 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference-based Learning with Retrieval Augmented Generation for Conversational Question Answering
Paper and Code
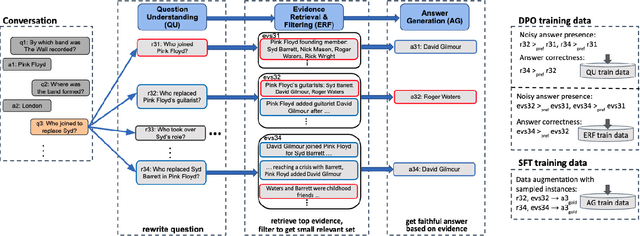
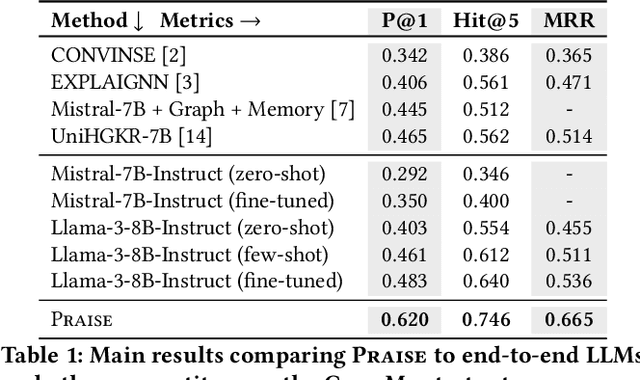
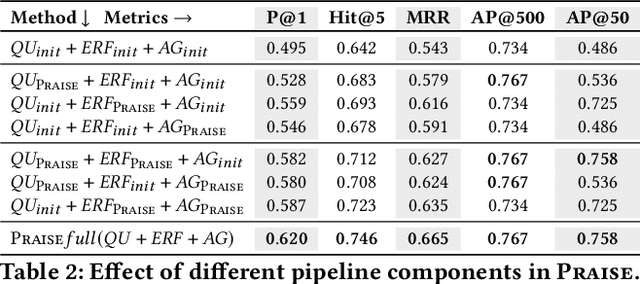
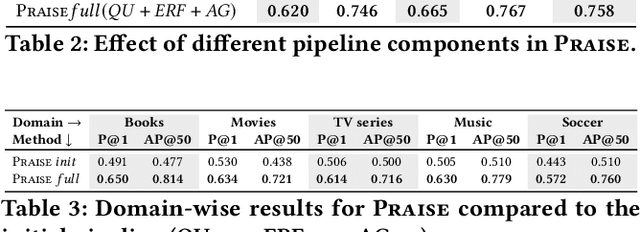
Conversational Question Answering (ConvQA) involves multiple subtasks, i) to understand incomplete questions in their context, ii) to retrieve relevant information, and iii) to generate answers. This work presents PRAISE, a pipeline-based approach for ConvQA that trains LLM adapters for each of the three subtasks. As labeled training data for individual subtasks is unavailable in practice, PRAISE learns from its own generations using the final answering performance as feedback signal without human intervention and treats intermediate information, like relevant evidence, as weakly labeled data. We apply Direct Preference Optimization by contrasting successful and unsuccessful samples for each subtask. In our experiments, we show the effectiveness of this training paradigm: PRAISE shows improvements per subtask and achieves new state-of-the-art performance on a popular ConvQA benchmark, by gaining 15.5 percentage points increase in precision over baselines.