 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference-based Learning with Retrieval Augmented Generation for Conversational Question Answering
Mar 28, 2025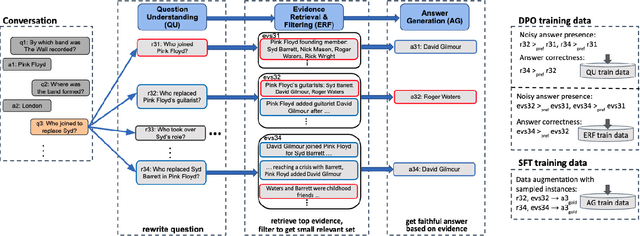
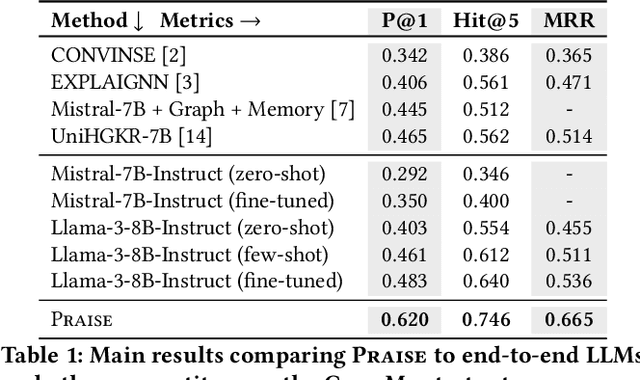
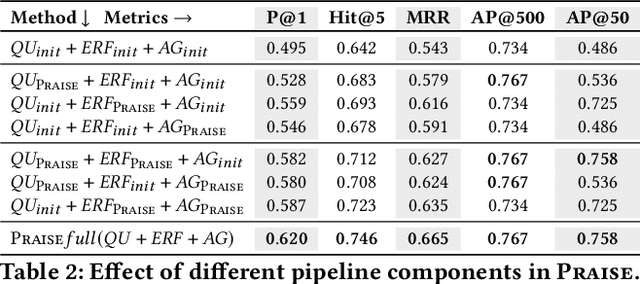
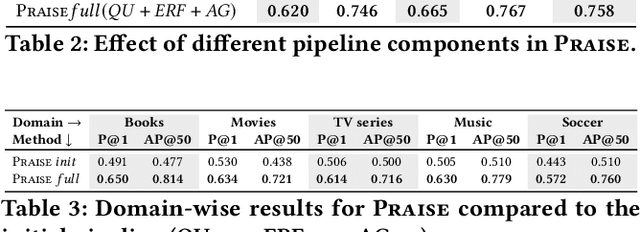
Conversational Question Answering (ConvQA) involves multiple subtasks, i) to understand incomplete questions in their context, ii) to retrieve relevant information, and iii) to generate answers. This work presents PRAISE, a pipeline-based approach for ConvQA that trains LLM adapters for each of the three subtasks. As labeled training data for individual subtasks is unavailable in practice, PRAISE learns from its own generations using the final answering performance as feedback signal without human intervention and treats intermediate information, like relevant evidence, as weakly labeled data. We apply Direct Preference Optimization by contrasting successful and unsuccessful samples for each subtask. In our experiments, we show the effectiveness of this training paradigm: PRAISE shows improvements per subtask and achieves new state-of-the-art performance on a popular ConvQA benchmark, by gaining 15.5 percentage points increase in precision over baselines.
Learning from Relevant Subgoals in Successful Dialogs using Iterative Training for Task-oriented Dialog Systems
Nov 25, 2024



Task-oriented Dialog (ToD) systems have to solve multiple subgoals to accomplish user goals, whereas feedback is often obtained only at the end of the dialog. In this work, we propose SUIT (SUbgoal-aware ITerative Training), an iterative training approach for improving ToD systems. We sample dialogs from the model we aim to improve and determine subgoals that contribute to dialog success using distant supervision to obtain high quality training samples. We show how this data improves supervised fine-tuning or, alternatively, preference learning results. SUIT is able to iteratively generate more data instead of relying on fixed static sets. SUIT reaches new state-of-the-art performance on a popular ToD benchmark.
Robust Training for Conversational Question Answering Models with Reinforced Reformulation Generation
Oct 20, 2023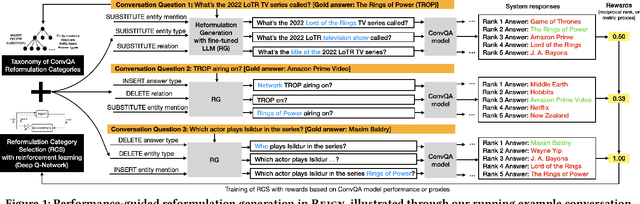
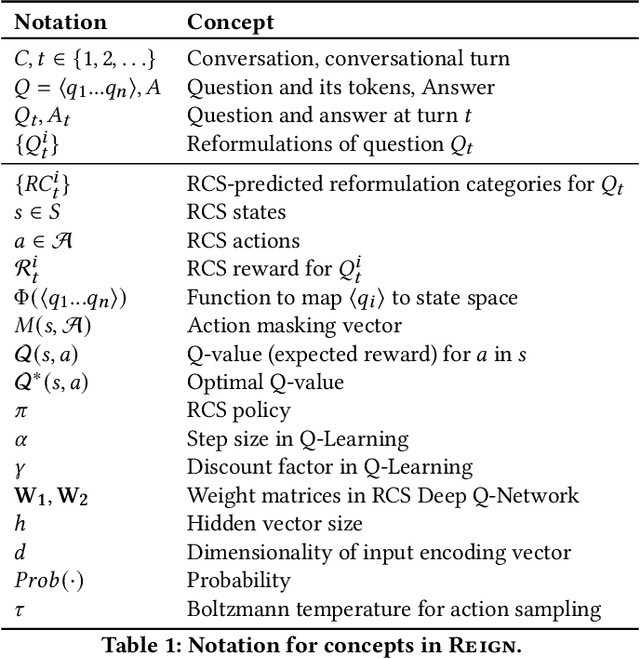
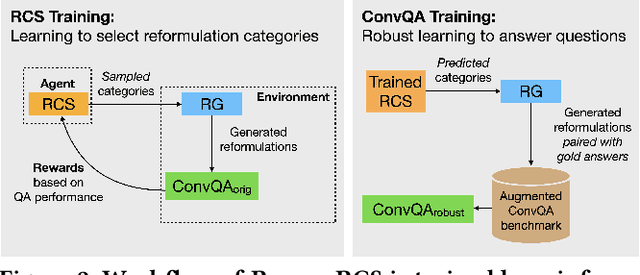

Models for conversational question answering (ConvQA) over knowledge graphs (KGs) are usually trained and tested on benchmarks of gold QA pairs. This implies that training is limited to surface forms seen in the respective datasets, and evaluation is on a small set of held-out questions. Through our proposed framework REIGN, we take several steps to remedy this restricted learning setup. First, we systematically generate reformulations of training questions to increase robustness of models to surface form variations. This is a particularly challenging problem, given the incomplete nature of such questions. Second, we guide ConvQA models towards higher performance by feeding it only those reformulations that help improve their answering quality, using deep reinforcement learning. Third, we demonstrate the viability of training major model components on one benchmark and applying them zero-shot to another. Finally, for a rigorous evaluation of robustness for trained models, we use and release large numbers of diverse reformulations generated by prompting GPT for benchmark test sets (resulting in 20x increase in sizes). Our findings show that ConvQA models with robust training via reformulations, significantly outperform those with standard training from gold QA pairs only.
Reinforcement Learning from Reformulations in Conversational Question Answering over Knowledge Graphs
May 11, 2021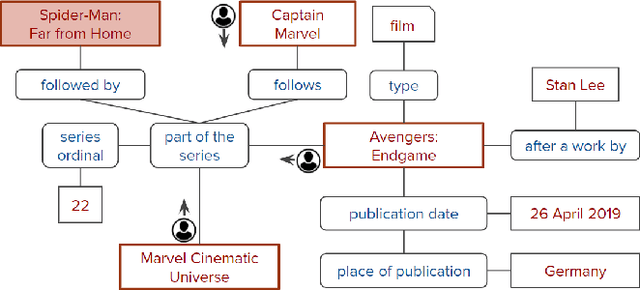

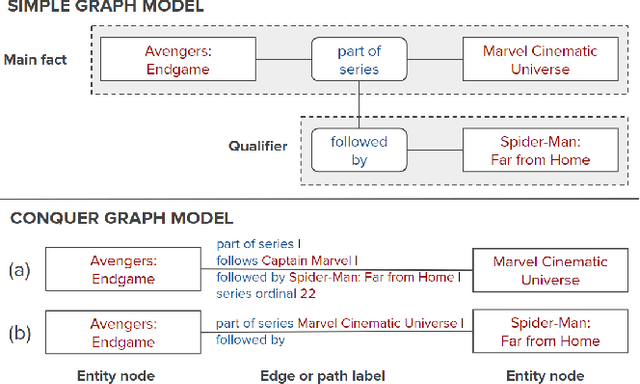

The rise of personal assistants has made conversational question answering (ConvQA) a very popular mechanism for user-system interaction. State-of-the-art methods for ConvQA over knowledge graphs (KGs) can only learn from crisp question-answer pairs found in popular benchmarks. In reality, however, such training data is hard to come by: users would rarely mark answers explicitly as correct or wrong. In this work, we take a step towards a more natural learning paradigm - from noisy and implicit feedback via question reformulations. A reformulation is likely to be triggered by an incorrect system response, whereas a new follow-up question could be a positive signal on the previous turn's answer. We present a reinforcement learning model, termed CONQUER, that can learn from a conversational stream of questions and reformulations. CONQUER models the answering process as multiple agents walking in parallel on the KG, where the walks are determined by actions sampled using a policy network. This policy network takes the question along with the conversational context as inputs and is trained via noisy rewards obtained from the reformulation likelihood. To evaluate CONQUER, we create and release ConvRef, a benchmark with about 11k natural conversations containing around 205k reformulations. Experiments show that CONQUER successfully learns to answer conversational questions from noisy reward signals, significantly improving over a state-of-the-art baseline.
Conversational Question Answering over Passages by Leveraging Word Proximity Networks
May 25, 2020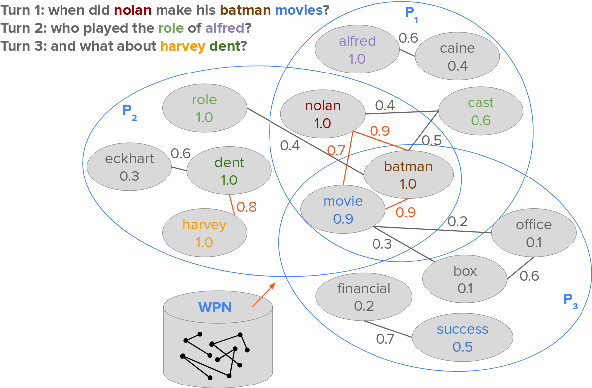
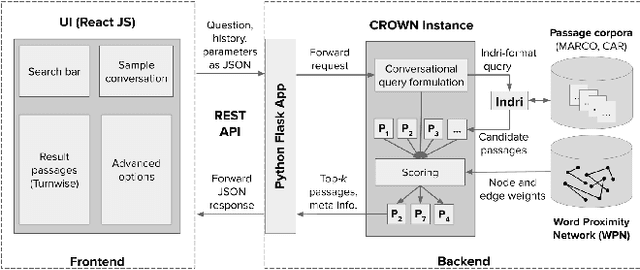
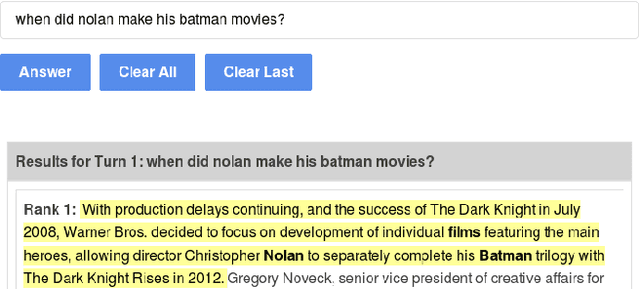

Question answering (QA) over text passages is a problem of long-standing interest in information retrieval. Recently, the conversational setting has attracted attention, where a user asks a sequence of questions to satisfy her information needs around a topic. While this setup is a natural one and similar to humans conversing with each other, it introduces two key research challenges: understanding the context left implicit by the user in follow-up questions, and dealing with ad hoc question formulations. In this work, we demonstrate CROWN (Conversational passage ranking by Reasoning Over Word Networks): an unsupervised yet effective system for conversational QA with passage responses, that supports several modes of context propagation over multiple turns. To this end, CROWN first builds a word proximity network (WPN) from large corpora to store statistically significant term co-occurrences. At answering time, passages are ranked by a combination of their similarity to the question, and coherence of query terms within: these factors are measured by reading off node and edge weights from the WPN. CROWN provides an interface that is both intuitive for end-users, and insightful for experts for reconfiguration to individual setups. CROWN was evaluated on TREC CAsT data, where it achieved above-median performance in a pool of neural methods.
CROWN: Conversational Passage Ranking by Reasoning over Word Networks
Nov 11, 2019
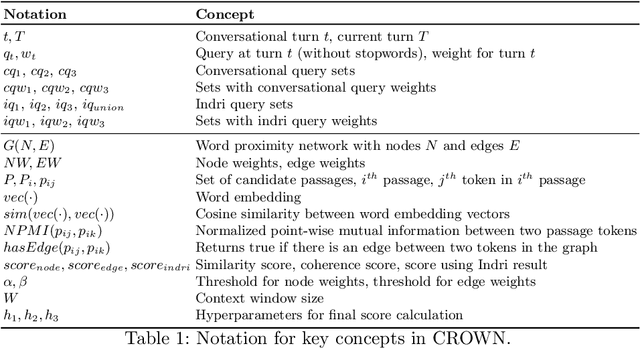
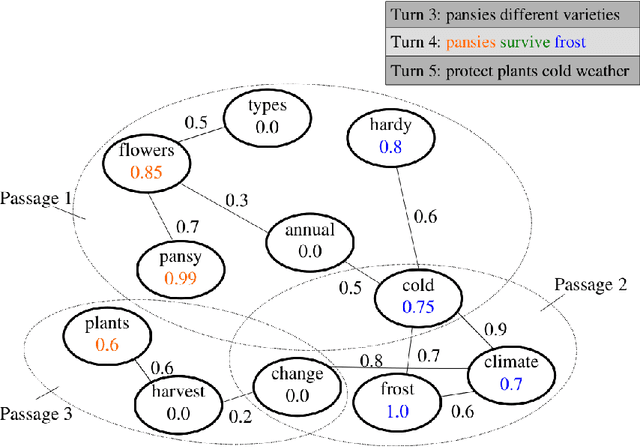
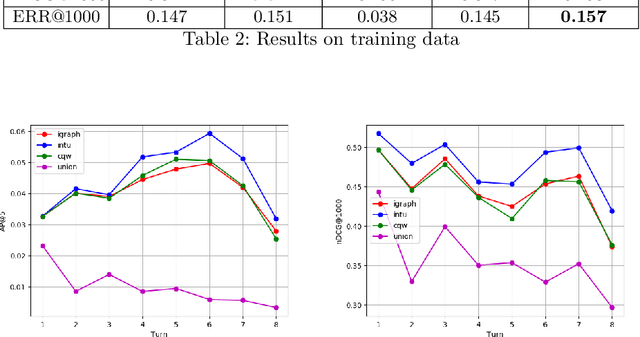
Information needs around a topic cannot be satisfied in a single turn; users typically ask follow-up questions referring to the same theme and a system must be capable of understanding the conversational context of a request to retrieve correct answers. In this paper, we present our submission to the TREC Conversational Assistance Track 2019, in which such a conversational setting is explored. We propose a simple unsupervised method for conversational passage ranking by formulating the passage score for a query as a combination of similarity and coherence. To be specific, passages are preferred that contain words semantically similar to the words used in the question, and where such words appear close by. We built a word-proximity network (WPN) from a large corpus, where words are nodes and there is an edge between two nodes if they co-occur in the same passages in a statistically significant way, within a context window. Our approach, named CROWN, improved nDCG scores over a provided Indri baseline on the CAsT training data. On the evaluation data for CAsT, our best run submission achieved above-average performance with respect to AP@5 and nDCG@1000.
* TREC 2019, 13 pages