 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Training for Conversational Question Answering Models with Reinforced Reformulation Generation
Paper and Code
Oct 20, 2023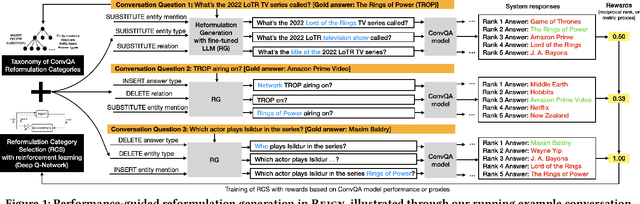
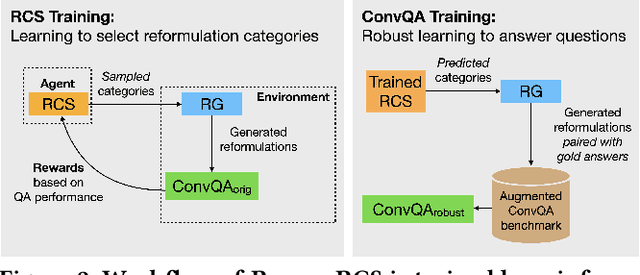

Models for conversational question answering (ConvQA) over knowledge graphs (KGs) are usually trained and tested on benchmarks of gold QA pairs. This implies that training is limited to surface forms seen in the respective datasets, and evaluation is on a small set of held-out questions. Through our proposed framework REIGN, we take several steps to remedy this restricted learning setup. First, we systematically generate reformulations of training questions to increase robustness of models to surface form variations. This is a particularly challenging problem, given the incomplete nature of such questions. Second, we guide ConvQA models towards higher performance by feeding it only those reformulations that help improve their answering quality, using deep reinforcement learning. Third, we demonstrate the viability of training major model components on one benchmark and applying them zero-shot to another. Finally, for a rigorous evaluation of robustness for trained models, we use and release large numbers of diverse reformulations generated by prompting GPT for benchmark test sets (resulting in 20x increase in sizes). Our findings show that ConvQA models with robust training via reformulations, significantly outperform those with standard training from gold QA pairs only.