 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCEDAR: Context Engineering for Agentic Data Science
Jan 10, 2026We demonstrate CEDAR, an application for automating data science (DS) tasks with an agentic setup. Solving DS problems with LLMs is an underexplored area that has immense market value. The challenges are manifold: task complexities, data sizes, computational limitations, and context restrictions. We show that these can be alleviated via effective context engineering. We first impose structure into the initial prompt with DS-specific input fields, that serve as instructions for the agentic system. The solution is then materialized as an enumerated sequence of interleaved plan and code blocks generated by separate LLM agents, providing a readable structure to the context at any step of the workflow. Function calls for generating these intermediate texts, and for corresponding Python code, ensure that data stays local, and only aggregate statistics and associated instructions are injected into LLM prompts. Fault tolerance and context management are introduced via iterative code generation and smart history rendering. The viability of our agentic data scientist is demonstrated using canonical Kaggle challenges.
RAGONITE: Iterative Retrieval on Induced Databases and Verbalized RDF for Conversational QA over KGs with RAG
Dec 24, 2024



Conversational question answering (ConvQA) is a convenient means of searching over RDF knowledge graphs (KGs), where a prevalent approach is to translate natural language questions to SPARQL queries. However, SPARQL has certain shortcomings: (i) it is brittle for complex intents and conversational questions, and (ii) it is not suitable for more abstract needs. Instead, we propose a novel two-pronged system where we fuse: (i) SQL-query results over a database automatically derived from the KG, and (ii) text-search results over verbalizations of KG facts. Our pipeline supports iterative retrieval: when the results of any branch are found to be unsatisfactory, the system can automatically opt for further rounds. We put everything together in a retrieval augmented generation (RAG) setup, where an LLM generates a coherent response from accumulated search results. We demonstrate the superiority of our proposed system over several baselines on a knowledge graph of BMW automobiles.
Evidence Contextualization and Counterfactual Attribution for Conversational QA over Heterogeneous Data with RAG Systems
Dec 18, 2024



Retrieval Augmented Generation (RAG) works as a backbone for interacting with an enterprise's own data via Conversational Question Answering (ConvQA). In a RAG system, a retriever fetches passages from a collection in response to a question, which are then included in the prompt of a large language model (LLM) for generating a natural language (NL) answer. However, several RAG systems today suffer from two shortcomings: (i) retrieved passages usually contain their raw text and lack appropriate document context, negatively impacting both retrieval and answering quality; and (ii) attribution strategies that explain answer generation usually rely only on similarity between the answer and the retrieved passages, thereby only generating plausible but not causal explanations. In this work, we demonstrate RAGONITE, a RAG system that remedies the above concerns by: (i) contextualizing evidence with source metadata and surrounding text; and (ii) computing counterfactual attribution, a causal explanation approach where the contribution of an evidence to an answer is determined by the similarity of the original response to the answer obtained by removing that evidence. To evaluate our proposals, we release a new benchmark ConfQuestions, with 300 hand-created conversational questions, each in English and German, coupled with ground truth URLs, completed questions, and answers from 215 public Confluence pages, that are typical of enterprise wiki spaces with heterogeneous elements. Experiments with RAGONITE on ConfQuestions show the viability of our ideas: contextualization improves RAG performance, and counterfactual attribution is effective at explaining RAG answers.
Robust Training for Conversational Question Answering Models with Reinforced Reformulation Generation
Oct 20, 2023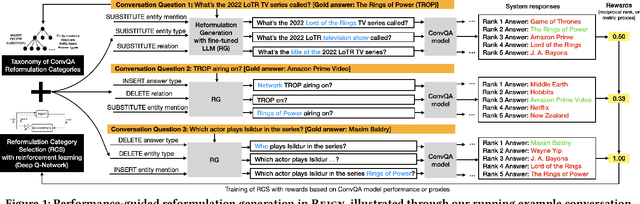
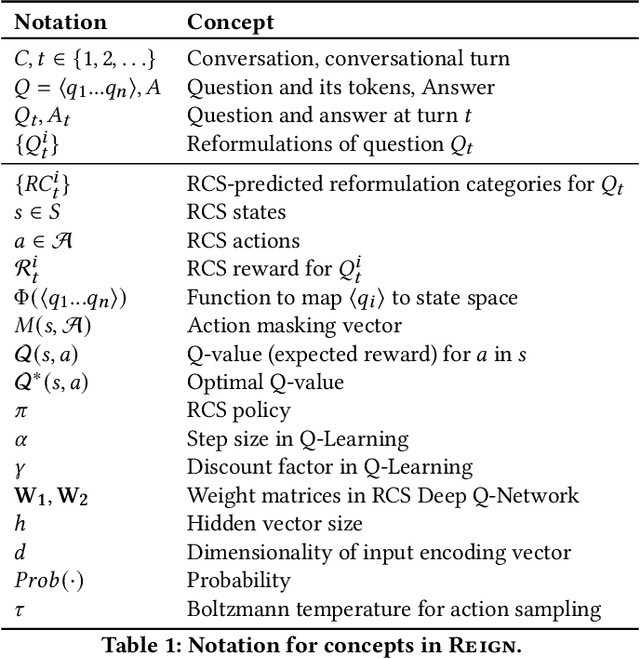
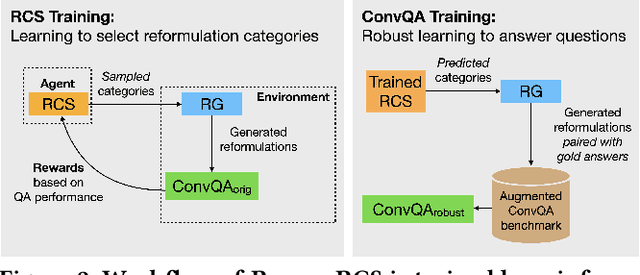

Models for conversational question answering (ConvQA) over knowledge graphs (KGs) are usually trained and tested on benchmarks of gold QA pairs. This implies that training is limited to surface forms seen in the respective datasets, and evaluation is on a small set of held-out questions. Through our proposed framework REIGN, we take several steps to remedy this restricted learning setup. First, we systematically generate reformulations of training questions to increase robustness of models to surface form variations. This is a particularly challenging problem, given the incomplete nature of such questions. Second, we guide ConvQA models towards higher performance by feeding it only those reformulations that help improve their answering quality, using deep reinforcement learning. Third, we demonstrate the viability of training major model components on one benchmark and applying them zero-shot to another. Finally, for a rigorous evaluation of robustness for trained models, we use and release large numbers of diverse reformulations generated by prompting GPT for benchmark test sets (resulting in 20x increase in sizes). Our findings show that ConvQA models with robust training via reformulations, significantly outperform those with standard training from gold QA pairs only.
CompMix: A Benchmark for Heterogeneous Question Answering
Jun 23, 2023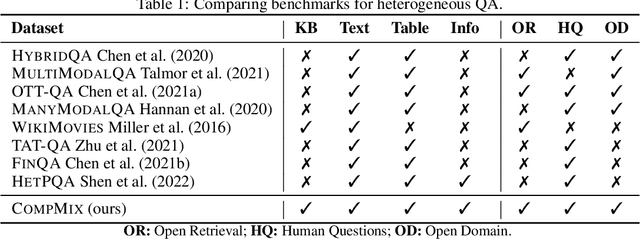
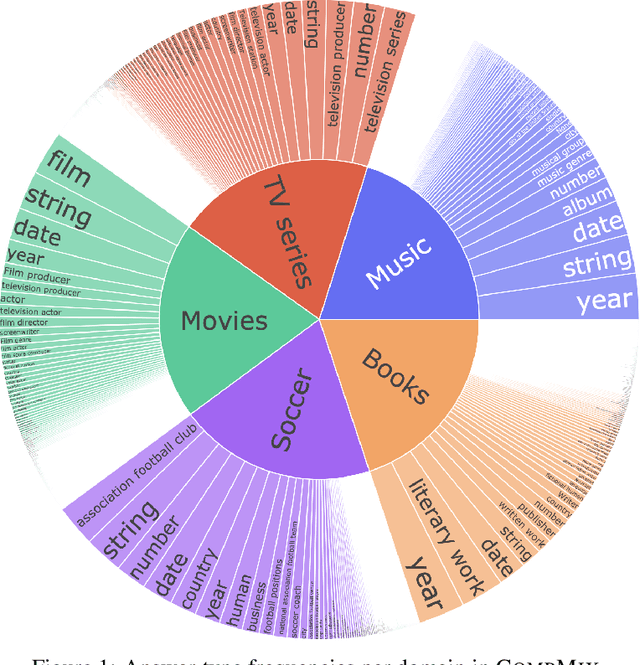
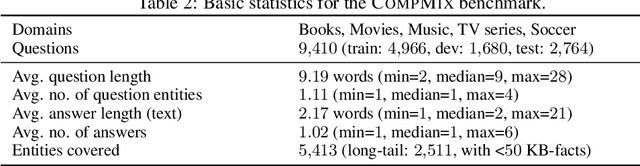
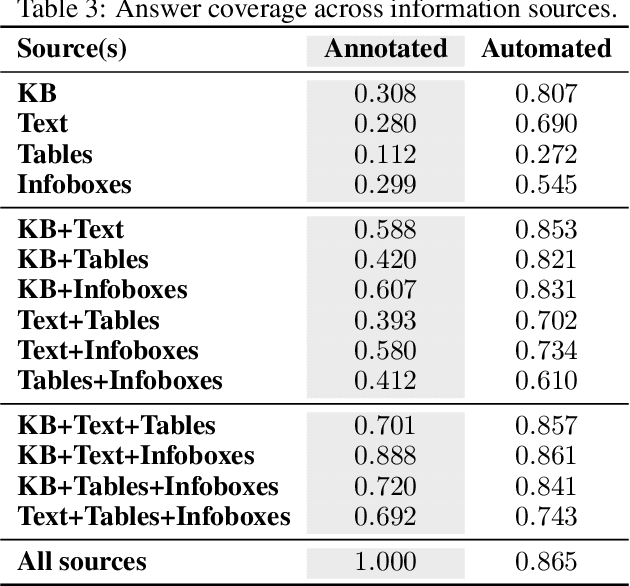
Fact-centric question answering (QA) often requires access to multiple, heterogeneous, information sources. By jointly considering several sources like a knowledge base (KB), a text collection, and tables from the web, QA systems can enhance their answer coverage and confidence. However, existing QA benchmarks are mostly constructed with a single source of knowledge in mind. This limits capabilities of these benchmarks to fairly evaluate QA systems that can tap into more than one information repository. To bridge this gap, we release CompMix, a crowdsourced QA benchmark which naturally demands the integration of a mixture of input sources. CompMix has a total of 9,410 questions, and features several complex intents like joins and temporal conditions. Evaluation of a range of QA systems on CompMix highlights the need for further research on leveraging information from heterogeneous sources.
Explainable Conversational Question Answering over Heterogeneous Sources via Iterative Graph Neural Networks
May 02, 2023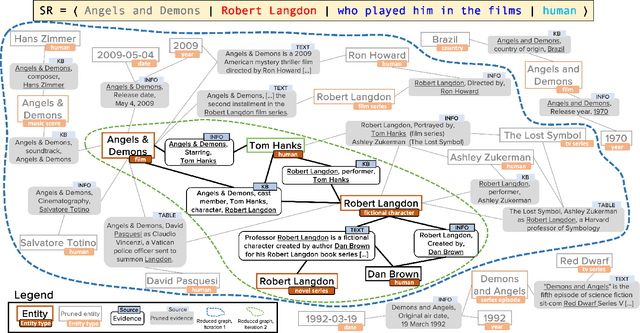
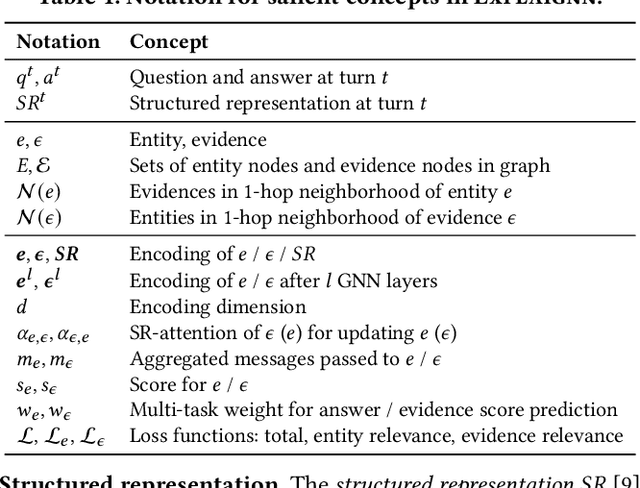

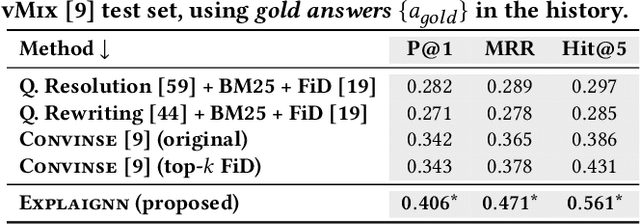
In conversational question answering, users express their information needs through a series of utterances with incomplete context. Typical ConvQA methods rely on a single source (a knowledge base (KB), or a text corpus, or a set of tables), thus being unable to benefit from increased answer coverage and redundancy of multiple sources. Our method EXPLAIGNN overcomes these limitations by integrating information from a mixture of sources with user-comprehensible explanations for answers. It constructs a heterogeneous graph from entities and evidence snippets retrieved from a KB, a text corpus, web tables, and infoboxes. This large graph is then iteratively reduced via graph neural networks that incorporate question-level attention, until the best answers and their explanations are distilled. Experiments show that EXPLAIGNN improves performance over state-of-the-art baselines. A user study demonstrates that derived answers are understandable by end users.
Conversational Question Answering on Heterogeneous Sources
Apr 25, 2022
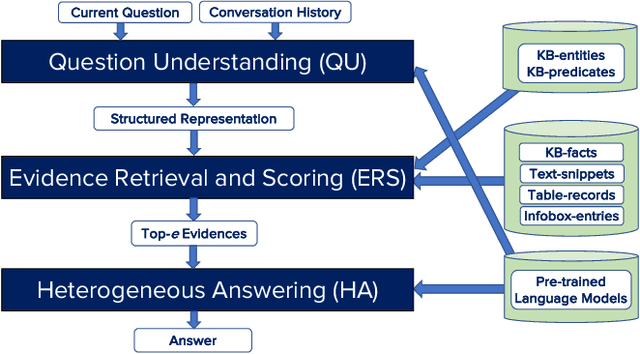
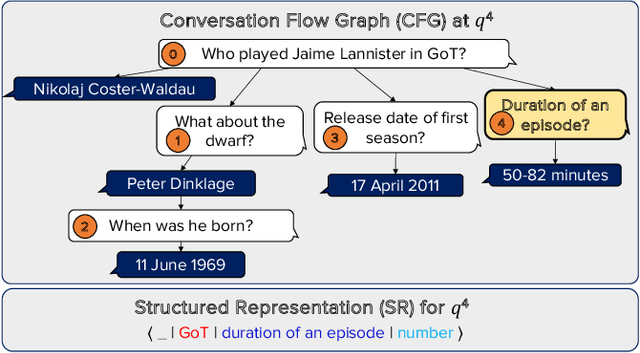

Conversational question answering (ConvQA) tackles sequential information needs where contexts in follow-up questions are left implicit. Current ConvQA systems operate over homogeneous sources of information: either a knowledge base (KB), or a text corpus, or a collection of tables. This paper addresses the novel issue of jointly tapping into all of these together, this way boosting answer coverage and confidence. We present CONVINSE, an end-to-end pipeline for ConvQA over heterogeneous sources, operating in three stages: i) learning an explicit structured representation of an incoming question and its conversational context, ii) harnessing this frame-like representation to uniformly capture relevant evidences from KB, text, and tables, and iii) running a fusion-in-decoder model to generate the answer. We construct and release the first benchmark, ConvMix, for ConvQA over heterogeneous sources, comprising 3000 real-user conversations with 16000 questions, along with entity annotations, completed question utterances, and question paraphrases. Experiments demonstrate the viability and advantages of our method, compared to state-of-the-art baselines.
Complex Temporal Question Answering on Knowledge Graphs
Sep 18, 2021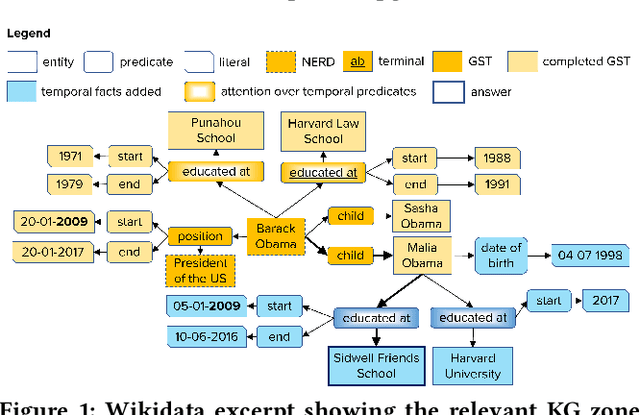

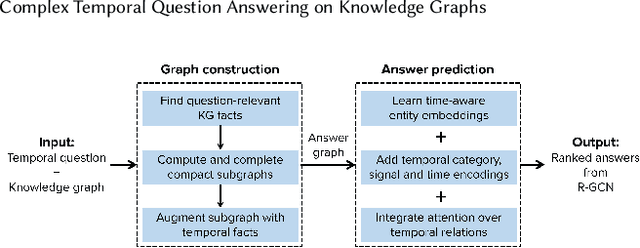
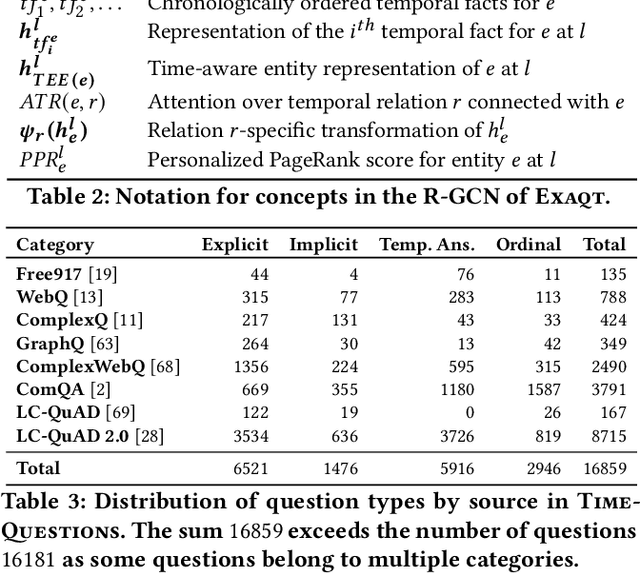
Question answering over knowledge graphs (KG-QA) is a vital topic in IR. Questions with temporal intent are a special class of practical importance, but have not received much attention in research. This work presents EXAQT, the first end-to-end system for answering complex temporal questions that have multiple entities and predicates, and associated temporal conditions. EXAQT answers natural language questions over KGs in two stages, one geared towards high recall, the other towards precision at top ranks. The first step computes question-relevant compact subgraphs within the KG, and judiciously enhances them with pertinent temporal facts, using Group Steiner Trees and fine-tuned BERT models. The second step constructs relational graph convolutional networks (R-GCNs) from the first step's output, and enhances the R-GCNs with time-aware entity embeddings and attention over temporal relations. We evaluate EXAQT on TimeQuestions, a large dataset of 16k temporal questions we compiled from a variety of general purpose KG-QA benchmarks. Results show that EXAQT outperforms three state-of-the-art systems for answering complex questions over KGs, thereby justifying specialized treatment of temporal QA.
Efficient Contextualization using Top-k Operators for Question Answering over Knowledge Graphs
Aug 21, 2021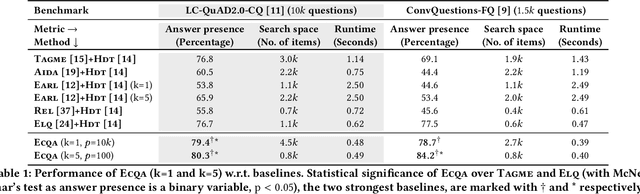
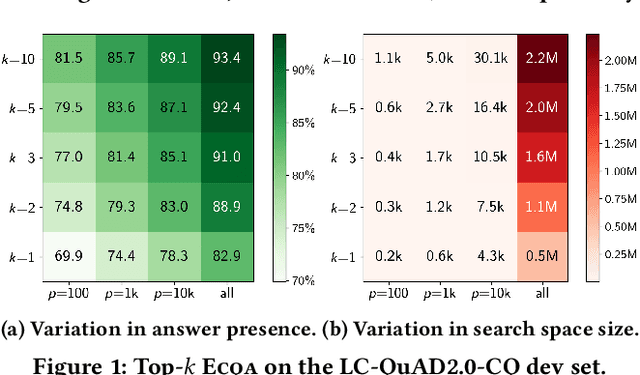
Answering complex questions over knowledge bases (KB-QA) faces huge input data with billions of facts, involving millions of entities and thousands of predicates. For efficiency, QA systems first reduce the answer search space by identifying a set of facts that is likely to contain all answers and relevant cues. The most common technique is to apply named entity disambiguation (NED) systems to the question, and retrieve KB facts for the disambiguated entities. This work presents ECQA, an efficient method that prunes irrelevant parts of the search space using KB-aware signals. ECQA is based on top-k query processing over score-ordered lists of KB items that combine signals about lexical matching, relevance to the question, coherence among candidate items, and connectivity in the KB graph. Experiments with two recent QA benchmarks demonstrate the superiority of ECQA over state-of-the-art baselines with respect to answer presence, size of the search space, and runtimes.
UNIQORN: Unified Question Answering over RDF Knowledge Graphs and Natural Language Text
Aug 19, 2021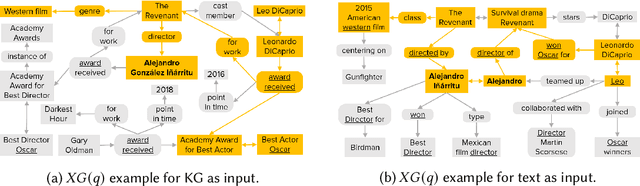
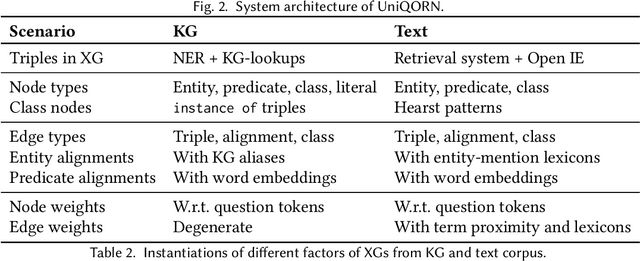
Question answering over knowledge graphs and other RDF data has been greatly advanced, with a number of good systems providing crisp answers for natural language questions or telegraphic queries. Some of these systems incorporate textual sources as additional evidence for the answering process, but cannot compute answers that are present in text alone. Conversely, systems from the IR and NLP communities have addressed QA over text, but barely utilize semantic data and knowledge. This paper presents the first QA system that can seamlessly operate over RDF datasets and text corpora, or both together, in a unified framework. Our method, called UNIQORN, builds a context graph on the fly, by retrieving question-relevant triples from the RDF data and/or the text corpus, where the latter case is handled by automatic information extraction. The resulting graph is typically rich but highly noisy. UNIQORN copes with this input by advanced graph algorithms for Group Steiner Trees, that identify the best answer candidates in the context graph. Experimental results on several benchmarks of complex questions with multiple entities and relations, show that UNIQORN, an unsupervised method with only five parameters, produces results comparable to the state-of-the-art on KGs, text corpora, and heterogeneous sources. The graph-based methodology provides user-interpretable evidence for the complete answering process.