 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-Telco: Benchmarks and Multimodal Large Language Models for Telecom Applications
Nov 17, 2025Large Language Models (LLMs) have emerged as powerful tools for automating complex reasoning and decision-making tasks. In telecommunications, they hold the potential to transform network optimization, automate troubleshooting, enhance customer support, and ensure regulatory compliance. However, their deployment in telecom is hindered by domain-specific challenges that demand specialized adaptation. To overcome these challenges and to accelerate the adaptation of LLMs for telecom, we propose MM-Telco, a comprehensive suite of multimodal benchmarks and models tailored for the telecom domain. The benchmark introduces various tasks (both text based and image based) that address various practical real-life use cases such as network operations, network management, improving documentation quality, and retrieval of relevant text and images. Further, we perform baseline experiments with various LLMs and VLMs. The models fine-tuned on our dataset exhibit a significant boost in performance. Our experiments also help analyze the weak areas in the working of current state-of-art multimodal LLMs, thus guiding towards further development and research.
Unsupervised Named Entity Disambiguation for Low Resource Domains
Dec 13, 2024In the ever-evolving landscape of natural language processing and information retrieval, the need for robust and domain-specific entity linking algorithms has become increasingly apparent. It is crucial in a considerable number of fields such as humanities, technical writing and biomedical sciences to enrich texts with semantics and discover more knowledge. The use of Named Entity Disambiguation (NED) in such domains requires handling noisy texts, low resource settings and domain-specific KBs. Existing approaches are mostly inappropriate for such scenarios, as they either depend on training data or are not flexible enough to work with domain-specific KBs. Thus in this work, we present an unsupervised approach leveraging the concept of Group Steiner Trees (GST), which can identify the most relevant candidates for entity disambiguation using the contextual similarities across candidate entities for all the mentions present in a document. We outperform the state-of-the-art unsupervised methods by more than 40\% (in avg.) in terms of Precision@1 across various domain-specific datasets.
Complex Temporal Question Answering on Knowledge Graphs
Sep 18, 2021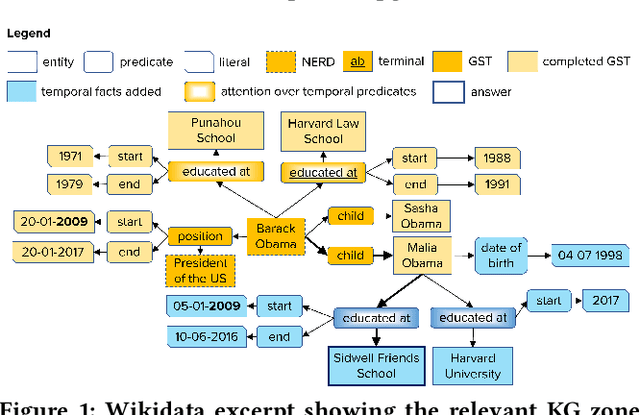

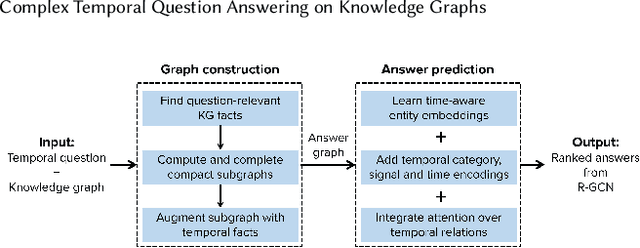
Question answering over knowledge graphs (KG-QA) is a vital topic in IR. Questions with temporal intent are a special class of practical importance, but have not received much attention in research. This work presents EXAQT, the first end-to-end system for answering complex temporal questions that have multiple entities and predicates, and associated temporal conditions. EXAQT answers natural language questions over KGs in two stages, one geared towards high recall, the other towards precision at top ranks. The first step computes question-relevant compact subgraphs within the KG, and judiciously enhances them with pertinent temporal facts, using Group Steiner Trees and fine-tuned BERT models. The second step constructs relational graph convolutional networks (R-GCNs) from the first step's output, and enhances the R-GCNs with time-aware entity embeddings and attention over temporal relations. We evaluate EXAQT on TimeQuestions, a large dataset of 16k temporal questions we compiled from a variety of general purpose KG-QA benchmarks. Results show that EXAQT outperforms three state-of-the-art systems for answering complex questions over KGs, thereby justifying specialized treatment of temporal QA.
UNIQORN: Unified Question Answering over RDF Knowledge Graphs and Natural Language Text
Aug 19, 2021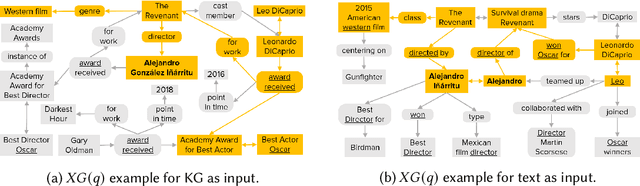
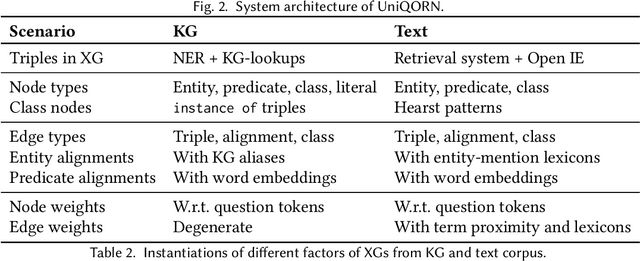
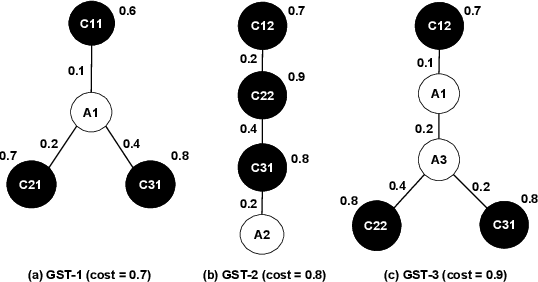
Question answering over knowledge graphs and other RDF data has been greatly advanced, with a number of good systems providing crisp answers for natural language questions or telegraphic queries. Some of these systems incorporate textual sources as additional evidence for the answering process, but cannot compute answers that are present in text alone. Conversely, systems from the IR and NLP communities have addressed QA over text, but barely utilize semantic data and knowledge. This paper presents the first QA system that can seamlessly operate over RDF datasets and text corpora, or both together, in a unified framework. Our method, called UNIQORN, builds a context graph on the fly, by retrieving question-relevant triples from the RDF data and/or the text corpus, where the latter case is handled by automatic information extraction. The resulting graph is typically rich but highly noisy. UNIQORN copes with this input by advanced graph algorithms for Group Steiner Trees, that identify the best answer candidates in the context graph. Experimental results on several benchmarks of complex questions with multiple entities and relations, show that UNIQORN, an unsupervised method with only five parameters, produces results comparable to the state-of-the-art on KGs, text corpora, and heterogeneous sources. The graph-based methodology provides user-interpretable evidence for the complete answering process.
ELIXIR: Learning from User Feedback on Explanations to Improve Recommender Models
Feb 22, 2021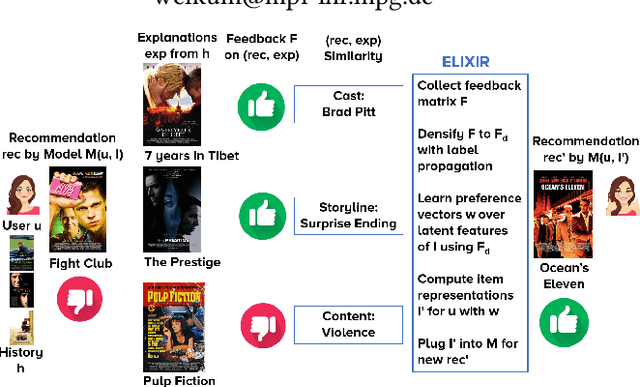

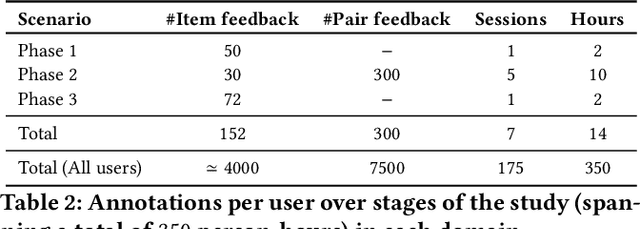
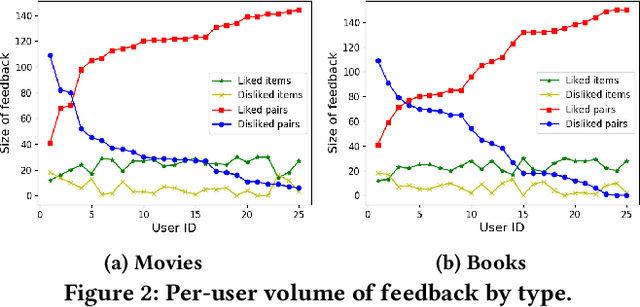
System-provided explanations for recommendations are an important component towards transparent and trustworthy AI. In state-of-the-art research, this is a one-way signal, though, to improve user acceptance. In this paper, we turn the role of explanations around and investigate how they can contribute to enhancing the quality of generated recommendations themselves. We devise a human-in-the-loop framework, called ELIXIR, where user feedback on explanations is leveraged for pairwise learning of user preferences. ELIXIR leverages feedback on pairs of recommendations and explanations to learn user-specific latent preference vectors, overcoming sparseness by label propagation with item-similarity-based neighborhoods. Our framework is instantiated using generalized graph recommendation via Random Walk with Restart. Insightful experiments with a real user study show significant improvements in movie and book recommendations over item-level feedback.
An Unsupervised Dynamic Image Segmentation using Fuzzy Hopfield Neural Network based Genetic Algorithm
May 30, 2012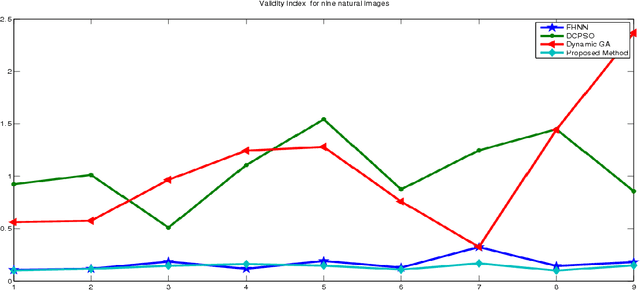

This paper proposes a Genetic Algorithm based segmentation method that can automatically segment gray-scale images. The proposed method mainly consists of spatial unsupervised grayscale image segmentation that divides an image into regions. The aim of this algorithm is to produce precise segmentation of images using intensity information along with neighborhood relationships. In this paper, Fuzzy Hopfield Neural Network (FHNN) clustering helps in generating the population of Genetic algorithm which there by automatically segments the image. This technique is a powerful method for image segmentation and works for both single and multiple-feature data with spatial information. Validity index has been utilized for introducing a robust technique for finding the optimum number of components in an image. Experimental results shown that the algorithm generates good quality segmented image.
* 8 pages