 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming Podcast Preview Generation: From Expert Models to LLM-Based Systems
May 29, 2025Discovering and evaluating long-form talk content such as videos and podcasts poses a significant challenge for users, as it requires a considerable time investment. Previews offer a practical solution by providing concise snippets that showcase key moments of the content, enabling users to make more informed and confident choices. We propose an LLM-based approach for generating podcast episode previews and deploy the solution at scale, serving hundreds of thousands of podcast previews in a real-world application. Comprehensive offline evaluations and online A/B testing demonstrate that LLM-generated previews consistently outperform a strong baseline built on top of various ML expert models, showcasing a significant reduction in the need for meticulous feature engineering. The offline results indicate notable enhancements in understandability, contextual clarity, and interest level, and the online A/B test shows a 4.6% increase in user engagement with preview content, along with a 5x boost in processing efficiency, offering a more streamlined and performant solution compared to the strong baseline of feature-engineered expert models.
PODTILE: Facilitating Podcast Episode Browsing with Auto-generated Chapters
Oct 21, 2024


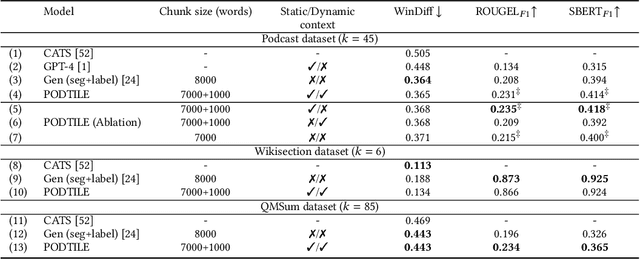
Listeners of long-form talk-audio content, such as podcast episodes, often find it challenging to understand the overall structure and locate relevant sections. A practical solution is to divide episodes into chapters--semantically coherent segments labeled with titles and timestamps. Since most episodes on our platform at Spotify currently lack creator-provided chapters, automating the creation of chapters is essential. Scaling the chapterization of podcast episodes presents unique challenges. First, episodes tend to be less structured than written texts, featuring spontaneous discussions with nuanced transitions. Second, the transcripts are usually lengthy, averaging about 16,000 tokens, which necessitates efficient processing that can preserve context. To address these challenges, we introduce PODTILE, a fine-tuned encoder-decoder transformer to segment conversational data. The model simultaneously generates chapter transitions and titles for the input transcript. To preserve context, each input text is augmented with global context, including the episode's title, description, and previous chapter titles. In our intrinsic evaluation, PODTILE achieved an 11% improvement in ROUGE score over the strongest baseline. Additionally, we provide insights into the practical benefits of auto-generated chapters for listeners navigating episode content. Our findings indicate that auto-generated chapters serve as a useful tool for engaging with less popular podcasts. Finally, we present empirical evidence that using chapter titles can enhance effectiveness of sparse retrieval in search tasks.
Counterfactual Explanations for Neural Recommenders
May 11, 2021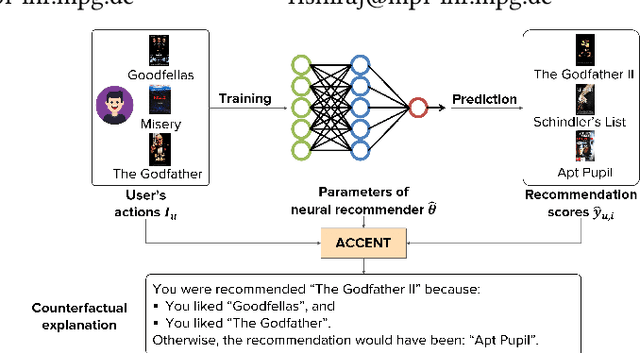
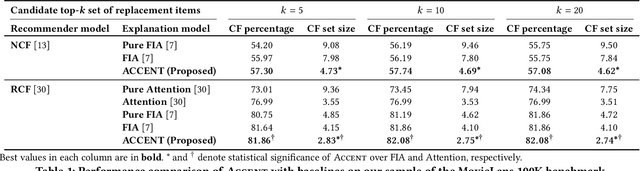
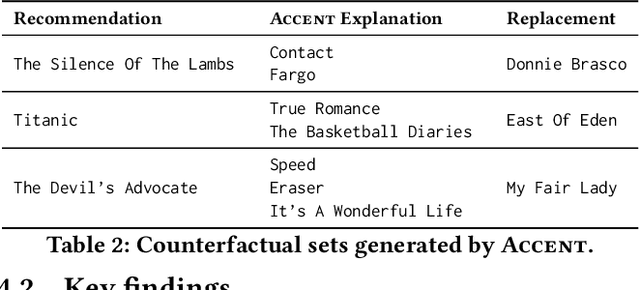
Understanding why specific items are recommended to users can significantly increase their trust and satisfaction in the system. While neural recommenders have become the state-of-the-art in recent years, the complexity of deep models still makes the generation of tangible explanations for end users a challenging problem. Existing methods are usually based on attention distributions over a variety of features, which are still questionable regarding their suitability as explanations, and rather unwieldy to grasp for an end user. Counterfactual explanations based on a small set of the user's own actions have been shown to be an acceptable solution to the tangibility problem. However, current work on such counterfactuals cannot be readily applied to neural models. In this work, we propose ACCENT, the first general framework for finding counterfactual explanations for neural recommenders. It extends recently-proposed influence functions for identifying training points most relevant to a recommendation, from a single to a pair of items, while deducing a counterfactual set in an iterative process. We use ACCENT to generate counterfactual explanations for two popular neural models, Neural Collaborative Filtering (NCF) and Relational Collaborative Filtering (RCF), and demonstrate its feasibility on a sample of the popular MovieLens 100K dataset.
ELIXIR: Learning from User Feedback on Explanations to Improve Recommender Models
Feb 22, 2021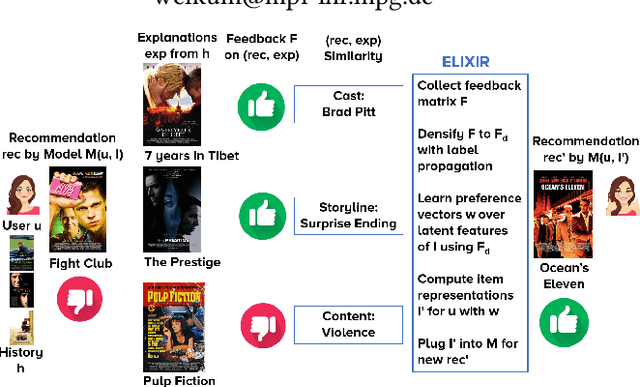

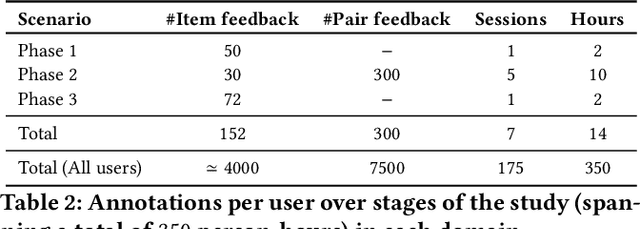
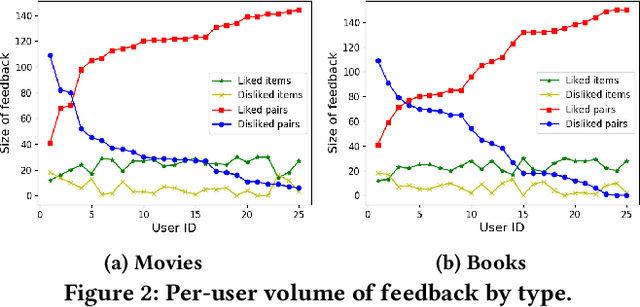
System-provided explanations for recommendations are an important component towards transparent and trustworthy AI. In state-of-the-art research, this is a one-way signal, though, to improve user acceptance. In this paper, we turn the role of explanations around and investigate how they can contribute to enhancing the quality of generated recommendations themselves. We devise a human-in-the-loop framework, called ELIXIR, where user feedback on explanations is leveraged for pairwise learning of user preferences. ELIXIR leverages feedback on pairs of recommendations and explanations to learn user-specific latent preference vectors, overcoming sparseness by label propagation with item-similarity-based neighborhoods. Our framework is instantiated using generalized graph recommendation via Random Walk with Restart. Insightful experiments with a real user study show significant improvements in movie and book recommendations over item-level feedback.
PRINCE: Provider-side Interpretability with Counterfactual Explanations in Recommender Systems
Dec 24, 2019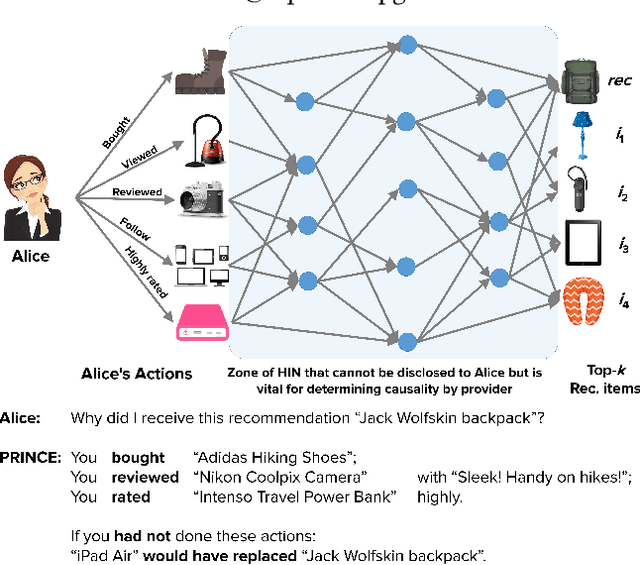

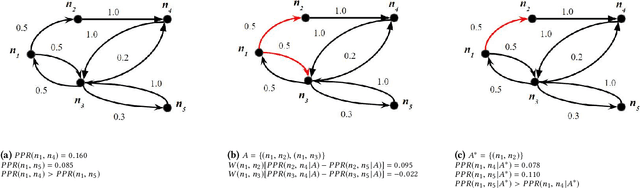
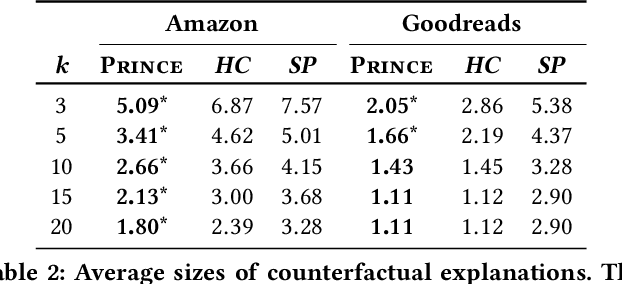
Interpretable explanations for recommender systems and other machine learning models are crucial to gain user trust. Prior works that have focused on paths connecting users and items in a heterogeneous network have several limitations, such as discovering relationships rather than true explanations, or disregarding other users' privacy. In this work, we take a fresh perspective, and present PRINCE: a provider-side mechanism to produce tangible explanations for end-users, where an explanation is defined to be a set of minimal actions performed by the user that, if removed, changes the recommendation to a different item. Given a recommendation, PRINCE uses a polynomial-time optimal algorithm for finding this minimal set of a user's actions from an exponential search space, based on random walks over dynamic graphs. Experiments on two real-world datasets show that PRINCE provides more compact explanations than intuitive baselines, and insights from a crowdsourced user-study demonstrate the viability of such action-based explanations. We thus posit that PRINCE produces scrutable, actionable, and concise explanations, owing to its use of counterfactual evidence, a user's own actions, and minimal sets, respectively.
FAIRY: A Framework for Understanding Relationships between Users' Actions and their Social Feeds
Aug 08, 2019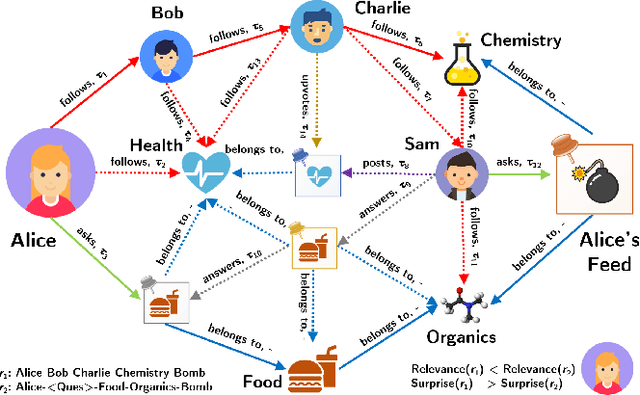
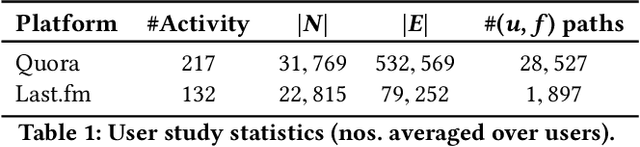
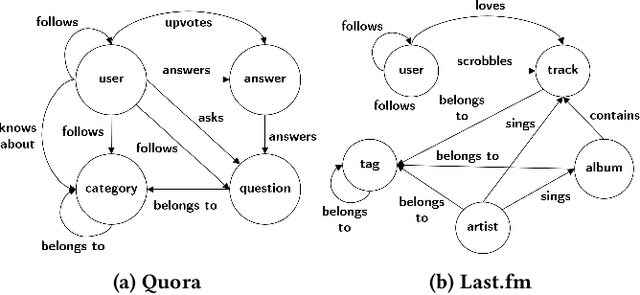
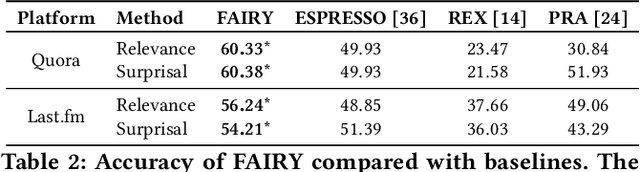
Users increasingly rely on social media feeds for consuming daily information. The items in a feed, such as news, questions, songs, etc., usually result from the complex interplay of a user's social contacts, her interests and her actions on the platform. The relationship of the user's own behavior and the received feed is often puzzling, and many users would like to have a clear explanation on why certain items were shown to them. Transparency and explainability are key concerns in the modern world of cognitive overload, filter bubbles, user tracking, and privacy risks. This paper presents FAIRY, a framework that systematically discovers, ranks, and explains relationships between users' actions and items in their social media feeds. We model the user's local neighborhood on the platform as an interaction graph, a form of heterogeneous information network constructed solely from information that is easily accessible to the concerned user. We posit that paths in this interaction graph connecting the user and her feed items can act as pertinent explanations for the user. These paths are scored with a learning-to-rank model that captures relevance and surprisal. User studies on two social platforms demonstrate the practical viability and user benefits of the FAIRY method.