 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorporate Greenwashing Detection in Text - a Survey
Feb 11, 2025Greenwashing is an effort to mislead the public about the environmental impact of an entity, such as a state or company. We provide a comprehensive survey of the scientific literature addressing natural language processing methods to identify potentially misleading climate-related corporate communications, indicative of greenwashing. We break the detection of greenwashing into intermediate tasks, and review the state-of-the-art approaches for each of them. We discuss datasets, methods, and results, as well as limitations and open challenges. We also provide an overview of how far the field has come as a whole, and point out future research directions.
Graph integration of structured, semistructured and unstructured data for data journalism
Dec 16, 2020
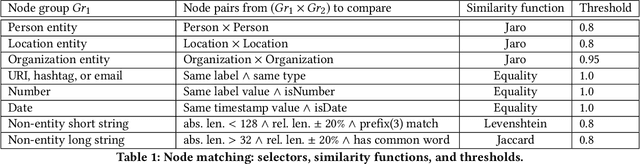
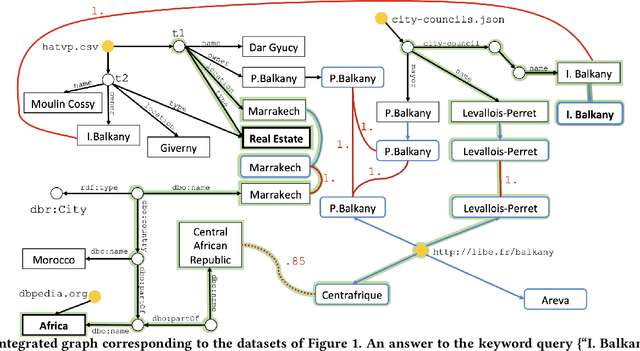

Digital data is a gold mine for modern journalism. However, datasets which interest journalists are extremely heterogeneous, ranging from highly structured (relational databases), semi-structured (JSON, XML, HTML), graphs (e.g., RDF), and text. Journalists (and other classes of users lacking advanced IT expertise, such as most non-governmental-organizations, or small public administrations) need to be able to make sense of such heterogeneous corpora, even if they lack the ability to define and deploy custom extract-transform-load workflows, especially for dynamically varying sets of data sources. We describe a complete approach for integrating dynamic sets of heterogeneous datasets along the lines described above: the challenges we faced to make such graphs useful, allow their integration to scale, and the solutions we proposed for these problems. Our approach is implemented within the ConnectionLens system; we validate it through a set of experiments.
PRINCE: Provider-side Interpretability with Counterfactual Explanations in Recommender Systems
Dec 24, 2019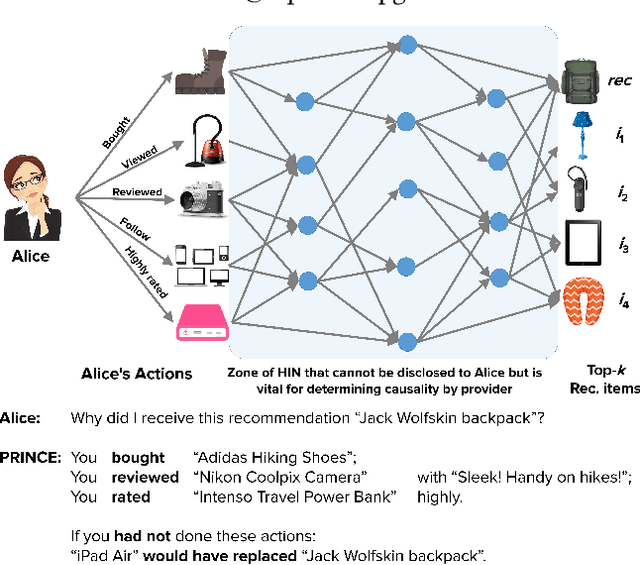

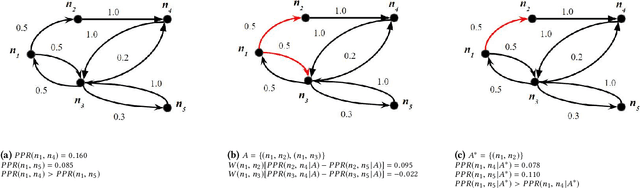
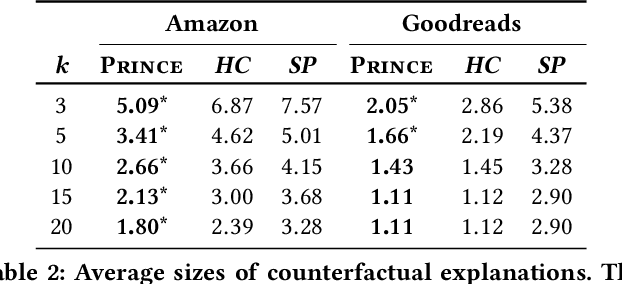
Interpretable explanations for recommender systems and other machine learning models are crucial to gain user trust. Prior works that have focused on paths connecting users and items in a heterogeneous network have several limitations, such as discovering relationships rather than true explanations, or disregarding other users' privacy. In this work, we take a fresh perspective, and present PRINCE: a provider-side mechanism to produce tangible explanations for end-users, where an explanation is defined to be a set of minimal actions performed by the user that, if removed, changes the recommendation to a different item. Given a recommendation, PRINCE uses a polynomial-time optimal algorithm for finding this minimal set of a user's actions from an exponential search space, based on random walks over dynamic graphs. Experiments on two real-world datasets show that PRINCE provides more compact explanations than intuitive baselines, and insights from a crowdsourced user-study demonstrate the viability of such action-based explanations. We thus posit that PRINCE produces scrutable, actionable, and concise explanations, owing to its use of counterfactual evidence, a user's own actions, and minimal sets, respectively.