 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLELA: an LLM-based Entity Linking Approach with Zero-Shot Domain Adaptation
Jan 08, 2026Entity linking (mapping ambiguous mentions in text to entities in a knowledge base) is a foundational step in tasks such as knowledge graph construction, question-answering, and information extraction. Our method, LELA, is a modular coarse-to-fine approach that leverages the capabilities of large language models (LLMs), and works with different target domains, knowledge bases and LLMs, without any fine-tuning phase. Our experiments across various entity linking settings show that LELA is highly competitive with fine-tuned approaches, and substantially outperforms the non-fine-tuned ones.
FLORA: Unsupervised Knowledge Graph Alignment by Fuzzy Logic
Oct 23, 2025Knowledge graph alignment is the task of matching equivalent entities (that is, instances and classes) and relations across two knowledge graphs. Most existing methods focus on pure entity-level alignment, computing the similarity of entities in some embedding space. They lack interpretable reasoning and need training data to work. In this paper, we propose FLORA, a simple yet effective method that (1) is unsupervised, i.e., does not require training data, (2) provides a holistic alignment for entities and relations iteratively, (3) is based on fuzzy logic and thus delivers interpretable results, (4) provably converges, (5) allows dangling entities, i.e., entities without a counterpart in the other KG, and (6) achieves state-of-the-art results on major benchmarks.
Corporate Greenwashing Detection in Text - a Survey
Feb 11, 2025Greenwashing is an effort to mislead the public about the environmental impact of an entity, such as a state or company. We provide a comprehensive survey of the scientific literature addressing natural language processing methods to identify potentially misleading climate-related corporate communications, indicative of greenwashing. We break the detection of greenwashing into intermediate tasks, and review the state-of-the-art approaches for each of them. We discuss datasets, methods, and results, as well as limitations and open challenges. We also provide an overview of how far the field has come as a whole, and point out future research directions.
Do Language Models Enjoy Their Own Stories? Prompting Large Language Models for Automatic Story Evaluation
May 22, 2024Storytelling is an integral part of human experience and plays a crucial role in social interactions. Thus, Automatic Story Evaluation (ASE) and Generation (ASG) could benefit society in multiple ways, but they are challenging tasks which require high-level human abilities such as creativity, reasoning and deep understanding. Meanwhile, Large Language Models (LLM) now achieve state-of-the-art performance on many NLP tasks. In this paper, we study whether LLMs can be used as substitutes for human annotators for ASE. We perform an extensive analysis of the correlations between LLM ratings, other automatic measures, and human annotations, and we explore the influence of prompting on the results and the explainability of LLM behaviour. Most notably, we find that LLMs outperform current automatic measures for system-level evaluation but still struggle at providing satisfactory explanations for their answers.
Reconfidencing LLMs from the Grouping Loss Perspective
Feb 07, 2024

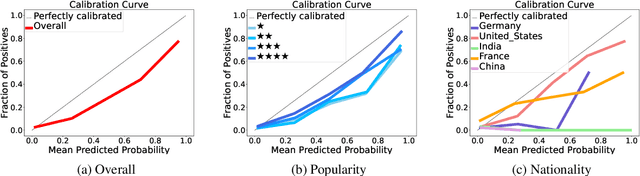

Large Language Models (LLMs), including ChatGPT and LLaMA, are susceptible to generating hallucinated answers in a confident tone. While efforts to elicit and calibrate confidence scores have proven useful, recent findings show that controlling uncertainty must go beyond calibration: predicted scores may deviate significantly from the actual posterior probabilities due to the impact of grouping loss. In this work, we construct a new evaluation dataset derived from a knowledge base to assess confidence scores given to answers of Mistral and LLaMA. Experiments show that they tend to be overconfident. Further, we show that they are more overconfident on some answers than others, \emph{eg} depending on the nationality of the person in the query. In uncertainty-quantification theory, this is grouping loss. To address this, we propose a solution to reconfidence LLMs, canceling not only calibration but also grouping loss. The LLMs, after the reconfidencing process, indicate improved confidence alignment with the accuracy of their responses.
Learning High-Quality and General-Purpose Phrase Representations
Jan 18, 2024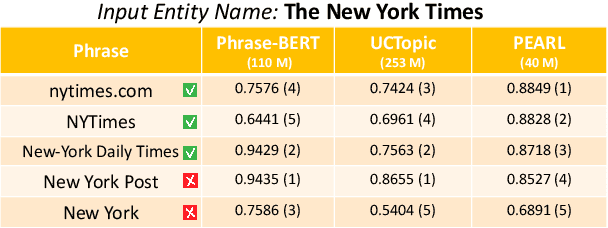
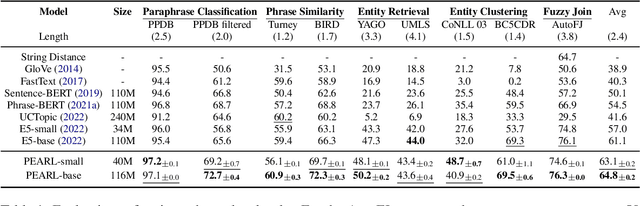
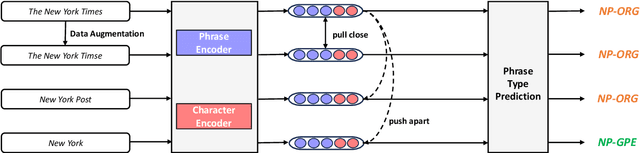
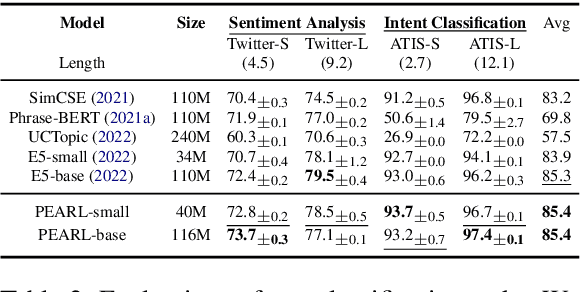
Phrase representations play an important role in data science and natural language processing, benefiting various tasks like Entity Alignment, Record Linkage, Fuzzy Joins, and Paraphrase Classification. The current state-of-the-art method involves fine-tuning pre-trained language models for phrasal embeddings using contrastive learning. However, we have identified areas for improvement. First, these pre-trained models tend to be unnecessarily complex and require to be pre-trained on a corpus with context sentences. Second, leveraging the phrase type and morphology gives phrase representations that are both more precise and more flexible. We propose an improved framework to learn phrase representations in a context-free fashion. The framework employs phrase type classification as an auxiliary task and incorporates character-level information more effectively into the phrase representation. Furthermore, we design three granularities of data augmentation to increase the diversity of training samples. Our experiments across a wide range of tasks show that our approach generates superior phrase embeddings compared to previous methods while requiring a smaller model size. The code is available at \faGithub~ \url{https://github.com/tigerchen52/PEARL} \end{abstract}
The Locality and Symmetry of Positional Encodings
Oct 19, 2023



Positional Encodings (PEs) are used to inject word-order information into transformer-based language models. While they can significantly enhance the quality of sentence representations, their specific contribution to language models is not fully understood, especially given recent findings that various positional encodings are insensitive to word order. In this work, we conduct a systematic study of positional encodings in \textbf{Bidirectional Masked Language Models} (BERT-style) , which complements existing work in three aspects: (1) We uncover the core function of PEs by identifying two common properties, Locality and Symmetry; (2) We show that the two properties are closely correlated with the performances of downstream tasks; (3) We quantify the weakness of current PEs by introducing two new probing tasks, on which current PEs perform poorly. We believe that these results are the basis for developing better PEs for transformer-based language models. The code is available at \faGithub~ \url{https://github.com/tigerchen52/locality\_symmetry}
GLADIS: A General and Large Acronym Disambiguation Benchmark
Feb 03, 2023
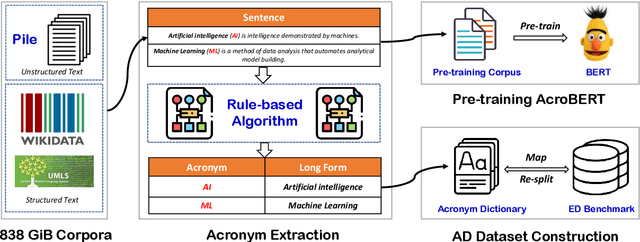


Acronym Disambiguation (AD) is crucial for natural language understanding on various sources, including biomedical reports, scientific papers, and search engine queries. However, existing acronym disambiguation benchmarks and tools are limited to specific domains, and the size of prior benchmarks is rather small. To accelerate the research on acronym disambiguation, we construct a new benchmark named GLADIS with three components: (1) a much larger acronym dictionary with 1.5M acronyms and 6.4M long forms; (2) a pre-training corpus with 160 million sentences; (3) three datasets that cover the general, scientific, and biomedical domains. We then pre-train a language model, \emph{AcroBERT}, on our constructed corpus for general acronym disambiguation, and show the challenges and values of our new benchmark.
Of Human Criteria and Automatic Metrics: A Benchmark of the Evaluation of Story Generation
Aug 25, 2022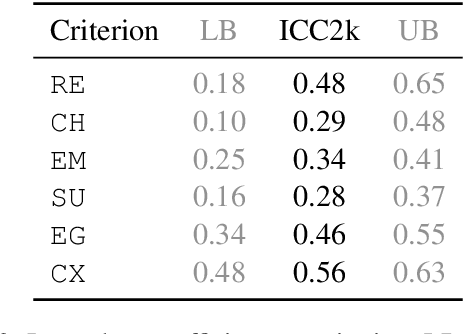


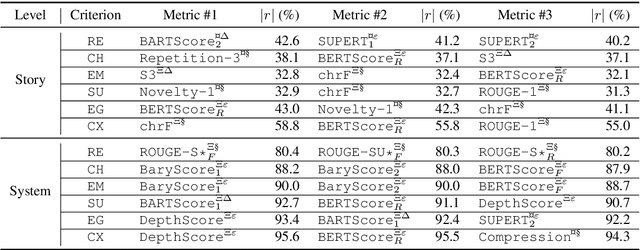
Research on Automatic Story Generation (ASG) relies heavily on human and automatic evaluation. However, there is no consensus on which human evaluation criteria to use, and no analysis of how well automatic criteria correlate with them. In this paper, we propose to re-evaluate ASG evaluation. We introduce a set of 6 orthogonal and comprehensive human criteria, carefully motivated by the social sciences literature. We also present HANNA, an annotated dataset of 1,056 stories produced by 10 different ASG systems. HANNA allows us to quantitatively evaluate the correlations of 72 automatic metrics with human criteria. Our analysis highlights the weaknesses of current metrics for ASG and allows us to formulate practical recommendations for ASG evaluation.
Imputing Out-of-Vocabulary Embeddings with LOVE Makes Language Models Robust with Little Cost
Mar 21, 2022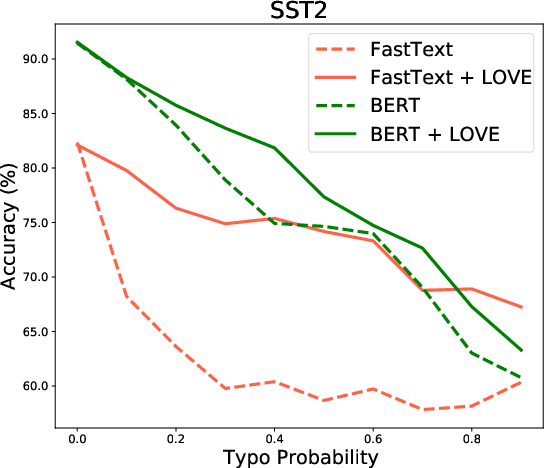
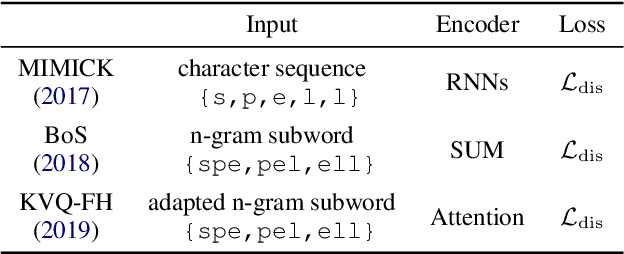
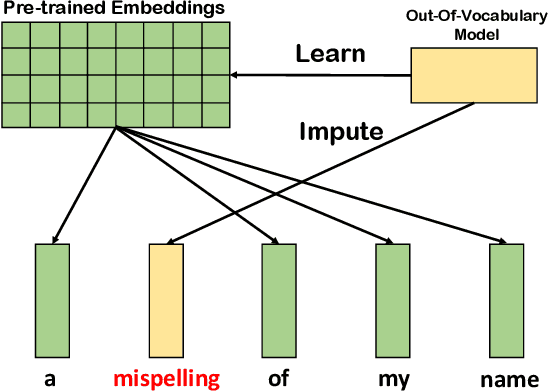
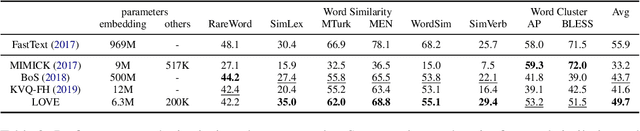
State-of-the-art NLP systems represent inputs with word embeddings, but these are brittle when faced with Out-of-Vocabulary (OOV) words. To address this issue, we follow the principle of mimick-like models to generate vectors for unseen words, by learning the behavior of pre-trained embeddings using only the surface form of words. We present a simple contrastive learning framework, LOVE, which extends the word representation of an existing pre-trained language model (such as BERT), and makes it robust to OOV with few additional parameters. Extensive evaluations demonstrate that our lightweight model achieves similar or even better performances than prior competitors, both on original datasets and on corrupted variants. Moreover, it can be used in a plug-and-play fashion with FastText and BERT, where it significantly improves their robustness.