 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOf Human Criteria and Automatic Metrics: A Benchmark of the Evaluation of Story Generation
Paper and Code
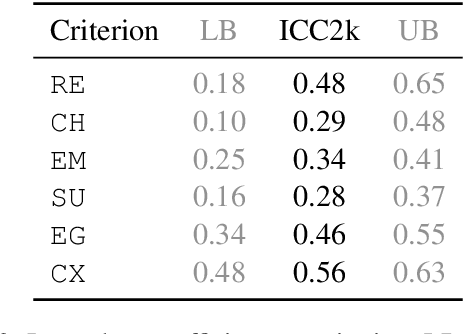


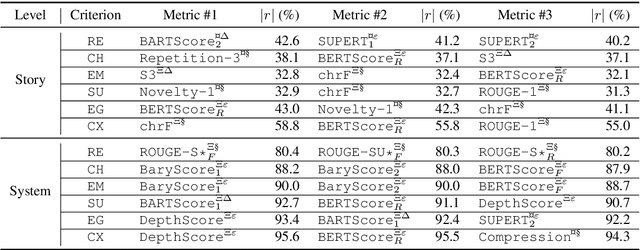
Research on Automatic Story Generation (ASG) relies heavily on human and automatic evaluation. However, there is no consensus on which human evaluation criteria to use, and no analysis of how well automatic criteria correlate with them. In this paper, we propose to re-evaluate ASG evaluation. We introduce a set of 6 orthogonal and comprehensive human criteria, carefully motivated by the social sciences literature. We also present HANNA, an annotated dataset of 1,056 stories produced by 10 different ASG systems. HANNA allows us to quantitatively evaluate the correlations of 72 automatic metrics with human criteria. Our analysis highlights the weaknesses of current metrics for ASG and allows us to formulate practical recommendations for ASG evaluation.