 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTable Foundation Models: on knowledge pre-training for tabular learning
May 20, 2025Table foundation models bring high hopes to data science: pre-trained on tabular data to embark knowledge or priors, they should facilitate downstream tasks on tables. One specific challenge is that of data semantics: numerical entries take their meaning from context, e.g., column name. Pre-trained neural networks that jointly model column names and table entries have recently boosted prediction accuracy. While these models outline the promises of world knowledge to interpret table values, they lack the convenience of popular foundation models in text or vision. Indeed, they must be fine-tuned to bring benefits, come with sizeable computation costs, and cannot easily be reused or combined with other architectures. Here we introduce TARTE, a foundation model that transforms tables to knowledge-enhanced vector representations using the string to capture semantics. Pre-trained on large relational data, TARTE yields representations that facilitate subsequent learning with little additional cost. These representations can be fine-tuned or combined with other learners, giving models that push the state-of-the-art prediction performance and improve the prediction/computation performance trade-off. Specialized to a task or a domain, TARTE gives domain-specific representations that facilitate further learning. Our study demonstrates an effective approach to knowledge pre-training for tabular learning.
Reconfidencing LLMs from the Grouping Loss Perspective
Feb 07, 2024

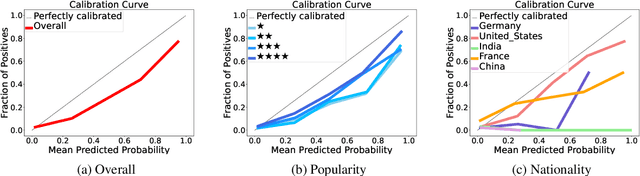

Large Language Models (LLMs), including ChatGPT and LLaMA, are susceptible to generating hallucinated answers in a confident tone. While efforts to elicit and calibrate confidence scores have proven useful, recent findings show that controlling uncertainty must go beyond calibration: predicted scores may deviate significantly from the actual posterior probabilities due to the impact of grouping loss. In this work, we construct a new evaluation dataset derived from a knowledge base to assess confidence scores given to answers of Mistral and LLaMA. Experiments show that they tend to be overconfident. Further, we show that they are more overconfident on some answers than others, \emph{eg} depending on the nationality of the person in the query. In uncertainty-quantification theory, this is grouping loss. To address this, we propose a solution to reconfidence LLMs, canceling not only calibration but also grouping loss. The LLMs, after the reconfidencing process, indicate improved confidence alignment with the accuracy of their responses.
Beyond calibration: estimating the grouping loss of modern neural networks
Oct 28, 2022Good decision making requires machine-learning models to provide trustworthy confidence scores. To this end, recent work has focused on miscalibration, i.e, the over or under confidence of model scores. Yet, contrary to widespread belief, calibration is not enough: even a classifier with the best possible accuracy and perfect calibration can have confidence scores far from the true posterior probabilities. This is due to the grouping loss, created by samples with the same confidence scores but different true posterior probabilities. Proper scoring rule theory shows that given the calibration loss, the missing piece to characterize individual errors is the grouping loss. While there are many estimators of the calibration loss, none exists for the grouping loss in standard settings. Here, we propose an estimator to approximate the grouping loss. We use it to study modern neural network architectures in vision and NLP. We find that the grouping loss varies markedly across architectures, and that it is a key model-comparison factor across the most accurate, calibrated, models. We also show that distribution shifts lead to high grouping loss.
Benchmarking missing-values approaches for predictive models on health databases
Feb 17, 2022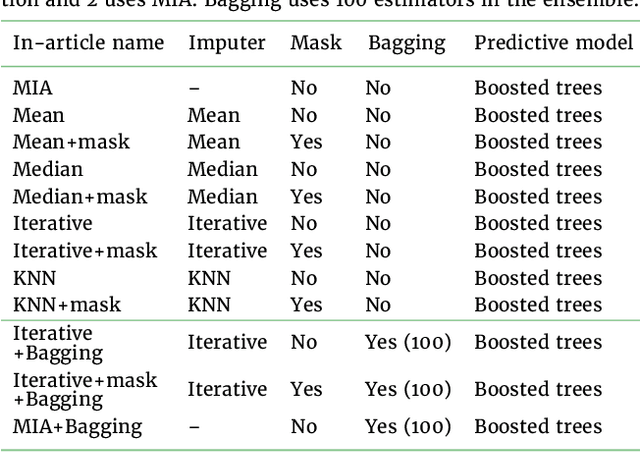
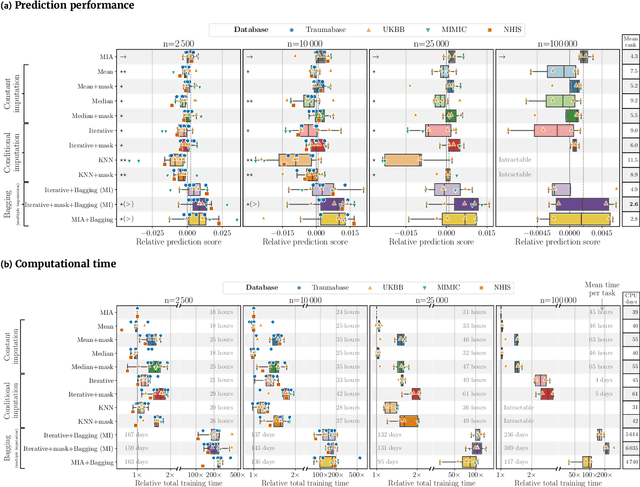
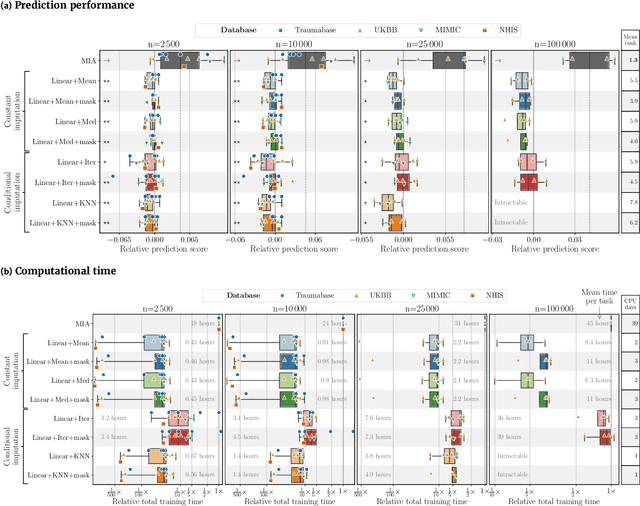
BACKGROUND: As databases grow larger, it becomes harder to fully control their collection, and they frequently come with missing values: incomplete observations. These large databases are well suited to train machine-learning models, for instance for forecasting or to extract biomarkers in biomedical settings. Such predictive approaches can use discriminative -- rather than generative -- modeling, and thus open the door to new missing-values strategies. Yet existing empirical evaluations of strategies to handle missing values have focused on inferential statistics. RESULTS: Here we conduct a systematic benchmark of missing-values strategies in predictive models with a focus on large health databases: four electronic health record datasets, a population brain imaging one, a health survey and two intensive care ones. Using gradient-boosted trees, we compare native support for missing values with simple and state-of-the-art imputation prior to learning. We investigate prediction accuracy and computational time. For prediction after imputation, we find that adding an indicator to express which values have been imputed is important, suggesting that the data are missing not at random. Elaborate missing values imputation can improve prediction compared to simple strategies but requires longer computational time on large data. Learning trees that model missing values-with missing incorporated attribute-leads to robust, fast, and well-performing predictive modeling. CONCLUSIONS: Native support for missing values in supervised machine learning predicts better than state-of-the-art imputation with much less computational cost. When using imputation, it is important to add indicator columns expressing which values have been imputed.