 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentCoMa: A Compositional Benchmark Mixing Commonsense and Mathematical Reasoning in Real-World Scenarios
Aug 27, 2025Large Language Models (LLMs) have achieved high accuracy on complex commonsense and mathematical problems that involve the composition of multiple reasoning steps. However, current compositional benchmarks testing these skills tend to focus on either commonsense or math reasoning, whereas LLM agents solving real-world tasks would require a combination of both. In this work, we introduce an Agentic Commonsense and Math benchmark (AgentCoMa), where each compositional task requires a commonsense reasoning step and a math reasoning step. We test it on 61 LLMs of different sizes, model families, and training strategies. We find that LLMs can usually solve both steps in isolation, yet their accuracy drops by ~30% on average when the two are combined. This is a substantially greater performance gap than the one we observe in prior compositional benchmarks that combine multiple steps of the same reasoning type. In contrast, non-expert human annotators can solve the compositional questions and the individual steps in AgentCoMa with similarly high accuracy. Furthermore, we conduct a series of interpretability studies to better understand the performance gap, examining neuron patterns, attention maps and membership inference. Our work underscores a substantial degree of model brittleness in the context of mixed-type compositional reasoning and offers a test bed for future improvement.
Query-Level Uncertainty in Large Language Models
Jun 11, 2025It is important for Large Language Models to be aware of the boundary of their knowledge, the mechanism of identifying known and unknown queries. This type of awareness can help models perform adaptive inference, such as invoking RAG, engaging in slow and deep thinking, or adopting the abstention mechanism, which is beneficial to the development of efficient and trustworthy AI. In this work, we propose a method to detect knowledge boundaries via Query-Level Uncertainty, which aims to determine if the model is able to address a given query without generating any tokens. To this end, we introduce a novel and training-free method called \emph{Internal Confidence}, which leverages self-evaluations across layers and tokens. Empirical results on both factual QA and mathematical reasoning tasks demonstrate that our internal confidence can outperform several baselines. Furthermore, we showcase that our proposed method can be used for efficient RAG and model cascading, which is able to reduce inference costs while maintaining performance.
Pub-Guard-LLM: Detecting Fraudulent Biomedical Articles with Reliable Explanations
Feb 21, 2025



A significant and growing number of published scientific articles is found to involve fraudulent practices, posing a serious threat to the credibility and safety of research in fields such as medicine. We propose Pub-Guard-LLM, the first large language model-based system tailored to fraud detection of biomedical scientific articles. We provide three application modes for deploying Pub-Guard-LLM: vanilla reasoning, retrieval-augmented generation, and multi-agent debate. Each mode allows for textual explanations of predictions. To assess the performance of our system, we introduce an open-source benchmark, PubMed Retraction, comprising over 11K real-world biomedical articles, including metadata and retraction labels. We show that, across all modes, Pub-Guard-LLM consistently surpasses the performance of various baselines and provides more reliable explanations, namely explanations which are deemed more relevant and coherent than those generated by the baselines when evaluated by multiple assessment methods. By enhancing both detection performance and explainability in scientific fraud detection, Pub-Guard-LLM contributes to safeguarding research integrity with a novel, effective, open-source tool.
What is the Role of Small Models in the LLM Era: A Survey
Sep 12, 2024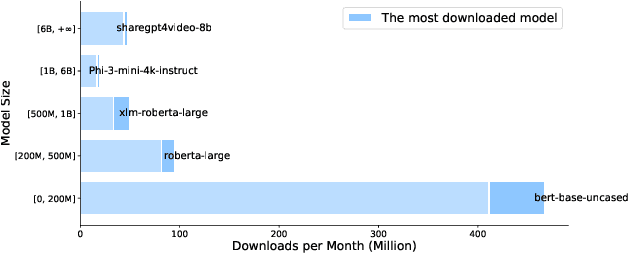

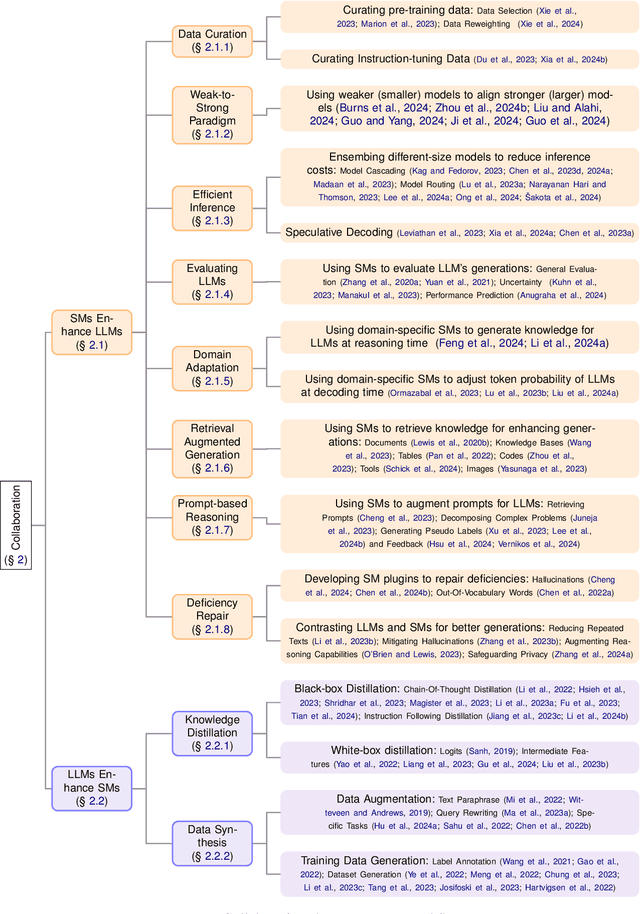
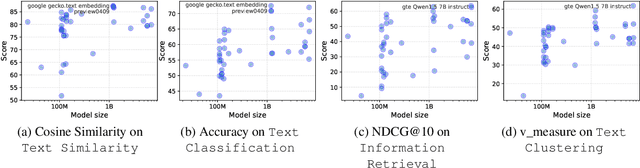
Large Language Models (LLMs) have made significant progress in advancing artificial general intelligence (AGI), leading to the development of increasingly large models such as GPT-4 and LLaMA-405B. However, scaling up model sizes results in exponentially higher computational costs and energy consumption, making these models impractical for academic researchers and businesses with limited resources. At the same time, Small Models (SMs) are frequently used in practical settings, although their significance is currently underestimated. This raises important questions about the role of small models in the era of LLMs, a topic that has received limited attention in prior research. In this work, we systematically examine the relationship between LLMs and SMs from two key perspectives: Collaboration and Competition. We hope this survey provides valuable insights for practitioners, fostering a deeper understanding of the contribution of small models and promoting more efficient use of computational resources. The code is available at https://github.com/tigerchen52/role_of_small_models
Analyzing Key Neurons in Large Language Models
Jun 16, 2024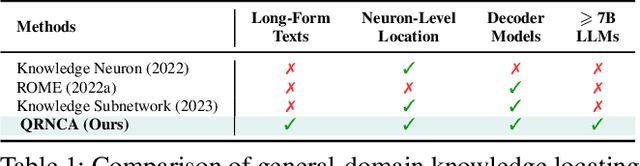
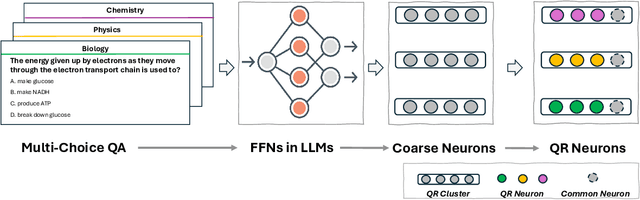
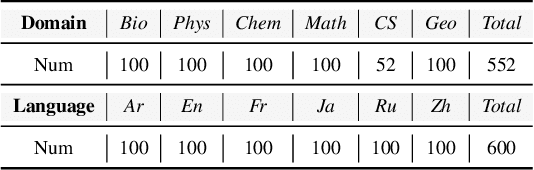
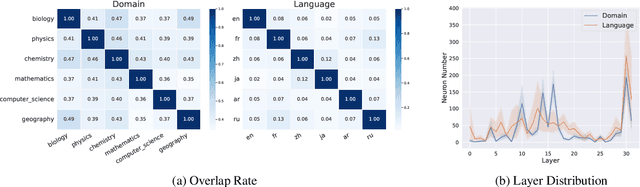
Large Language Models (LLMs) possess vast amounts of knowledge within their parameters, prompting research into methods for locating and editing this knowledge. Previous investigations have primarily focused on fill-in-the-blank tasks and locating entity-related usually single-token facts) information in relatively small-scale language models. However, several key questions remain unanswered: (1) How can we effectively locate query-relevant neurons in contemporary autoregressive LLMs, such as LLaMA and Mistral? (2) How can we address the challenge of long-form text generation? (3) Are there localized knowledge regions in LLMs? In this study, we introduce Neuron Attribution-Inverse Cluster Attribution (NA-ICA), a novel architecture-agnostic framework capable of identifying key neurons in LLMs. NA-ICA allows for the examination of long-form answers beyond single tokens by employing the proxy task of multi-choice question answering. To evaluate the effectiveness of our detected key neurons, we construct two multi-choice QA datasets spanning diverse domains and languages. Empirical evaluations demonstrate that NA-ICA outperforms baseline methods significantly. Moreover, analysis of neuron distributions reveals the presence of visible localized regions, particularly within different domains. Finally, we demonstrate the potential applications of our detected key neurons in knowledge editing and neuron-based prediction.
Reconfidencing LLMs from the Grouping Loss Perspective
Feb 07, 2024

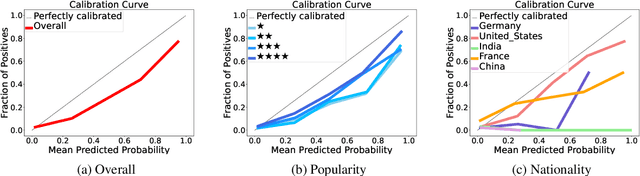

Large Language Models (LLMs), including ChatGPT and LLaMA, are susceptible to generating hallucinated answers in a confident tone. While efforts to elicit and calibrate confidence scores have proven useful, recent findings show that controlling uncertainty must go beyond calibration: predicted scores may deviate significantly from the actual posterior probabilities due to the impact of grouping loss. In this work, we construct a new evaluation dataset derived from a knowledge base to assess confidence scores given to answers of Mistral and LLaMA. Experiments show that they tend to be overconfident. Further, we show that they are more overconfident on some answers than others, \emph{eg} depending on the nationality of the person in the query. In uncertainty-quantification theory, this is grouping loss. To address this, we propose a solution to reconfidence LLMs, canceling not only calibration but also grouping loss. The LLMs, after the reconfidencing process, indicate improved confidence alignment with the accuracy of their responses.
Learning High-Quality and General-Purpose Phrase Representations
Jan 18, 2024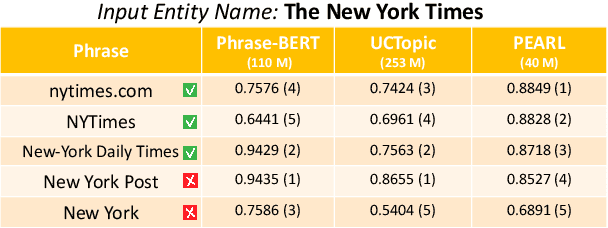
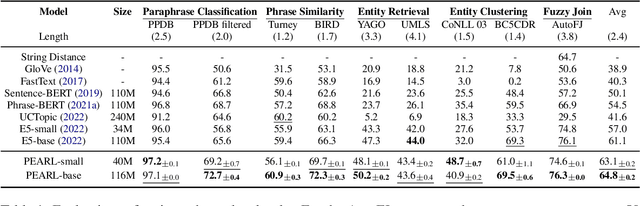
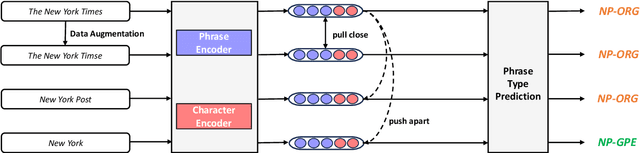
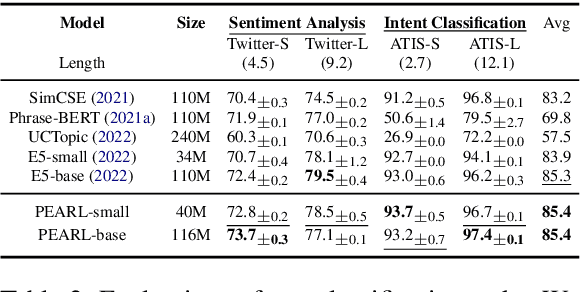
Phrase representations play an important role in data science and natural language processing, benefiting various tasks like Entity Alignment, Record Linkage, Fuzzy Joins, and Paraphrase Classification. The current state-of-the-art method involves fine-tuning pre-trained language models for phrasal embeddings using contrastive learning. However, we have identified areas for improvement. First, these pre-trained models tend to be unnecessarily complex and require to be pre-trained on a corpus with context sentences. Second, leveraging the phrase type and morphology gives phrase representations that are both more precise and more flexible. We propose an improved framework to learn phrase representations in a context-free fashion. The framework employs phrase type classification as an auxiliary task and incorporates character-level information more effectively into the phrase representation. Furthermore, we design three granularities of data augmentation to increase the diversity of training samples. Our experiments across a wide range of tasks show that our approach generates superior phrase embeddings compared to previous methods while requiring a smaller model size. The code is available at \faGithub~ \url{https://github.com/tigerchen52/PEARL} \end{abstract}
The Locality and Symmetry of Positional Encodings
Oct 19, 2023



Positional Encodings (PEs) are used to inject word-order information into transformer-based language models. While they can significantly enhance the quality of sentence representations, their specific contribution to language models is not fully understood, especially given recent findings that various positional encodings are insensitive to word order. In this work, we conduct a systematic study of positional encodings in \textbf{Bidirectional Masked Language Models} (BERT-style) , which complements existing work in three aspects: (1) We uncover the core function of PEs by identifying two common properties, Locality and Symmetry; (2) We show that the two properties are closely correlated with the performances of downstream tasks; (3) We quantify the weakness of current PEs by introducing two new probing tasks, on which current PEs perform poorly. We believe that these results are the basis for developing better PEs for transformer-based language models. The code is available at \faGithub~ \url{https://github.com/tigerchen52/locality\_symmetry}
Knowledge Base Completion for Long-Tail Entities
Jun 30, 2023Despite their impressive scale, knowledge bases (KBs), such as Wikidata, still contain significant gaps. Language models (LMs) have been proposed as a source for filling these gaps. However, prior works have focused on prominent entities with rich coverage by LMs, neglecting the crucial case of long-tail entities. In this paper, we present a novel method for LM-based-KB completion that is specifically geared for facts about long-tail entities. The method leverages two different LMs in two stages: for candidate retrieval and for candidate verification and disambiguation. To evaluate our method and various baselines, we introduce a novel dataset, called MALT, rooted in Wikidata. Our method outperforms all baselines in F1, with major gains especially in recall.
GLADIS: A General and Large Acronym Disambiguation Benchmark
Feb 03, 2023
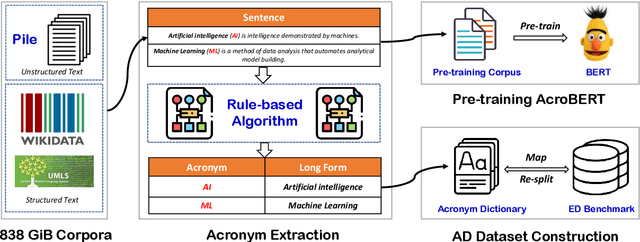


Acronym Disambiguation (AD) is crucial for natural language understanding on various sources, including biomedical reports, scientific papers, and search engine queries. However, existing acronym disambiguation benchmarks and tools are limited to specific domains, and the size of prior benchmarks is rather small. To accelerate the research on acronym disambiguation, we construct a new benchmark named GLADIS with three components: (1) a much larger acronym dictionary with 1.5M acronyms and 6.4M long forms; (2) a pre-training corpus with 160 million sentences; (3) three datasets that cover the general, scientific, and biomedical domains. We then pre-train a language model, \emph{AcroBERT}, on our constructed corpus for general acronym disambiguation, and show the challenges and values of our new benchmark.