 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurosymbolic Learning for Inference-Time Argumentation
May 19, 2026Claim verification is an important problem in high-stakes settings, including health and finance. When information underpinning claims is incomplete or conflicting, uncertain answers may be more appropriate than binary true or false classifications. In all cases, faithful explanations of the considerations determining the final verdict are crucial. We introduce inference-time argumentation (ITA), a trainable neurosymbolic framework for ternary claim verification in which a formal argumentation semantics giving the strength of claims is used both (i) to guide LLM training as models learn to generate arguments and assign them base scores (representing intrinsic strengths) and (ii) to compute ternary (true/false/uncertain) predictions from generated, scored arguments. As a result, at training time, argument generation and scoring can be optimised according to the quality of the induced argumentative predictions. Moreover, at inference time, the final prediction is faithful, by construction, to the arguments and scores determining the verdict, rather than being justified by a potentially unfaithful post-hoc reasoning trace as in conventional reasoning models. We finally show that, on two datasets for ternary claim verification, ITA improves upon argumentative baselines and can perform competitively against non-argumentative direct-prediction baselines, while providing verdicts that are computed deterministically from explicit, inspectable argumentative structures.
Argumentation for Explainable and Globally Contestable Decision Support with LLMs
Mar 15, 2026Large language models (LLMs) exhibit strong general capabilities, but their deployment in high-stakes domains is hindered by their opacity and unpredictability. Recent work has taken meaningful steps towards addressing these issues by augmenting LLMs with post-hoc reasoning based on computational argumentation, providing faithful explanations and enabling users to contest incorrect decisions. However, this paradigm is limited to pre-defined binary choices and only supports local contestation for specific instances, leaving the underlying decision logic unchanged and prone to repeated mistakes. In this paper, we introduce ArgEval, a framework that shifts from instance-specific reasoning to structured evaluation of general decision options. Rather than mining arguments solely for individual cases, ArgEval systematically maps task-specific decision spaces, builds corresponding option ontologies, and constructs general argumentation frameworks (AFs) for each option. These frameworks can then be instantiated to provide explainable recommendations for specific cases while still supporting global contestability through modification of the shared AFs. We investigate the effectiveness of ArgEval on treatment recommendation for glioblastoma, an aggressive brain tumour, and show that it can produce explainable guidance aligned with clinical practice.
ArgLLM-App: An Interactive System for Argumentative Reasoning with Large Language Models
Feb 27, 2026Argumentative LLMs (ArgLLMs) are an existing approach leveraging Large Language Models (LLMs) and computational argumentation for decision-making, with the aim of making the resulting decisions faithfully explainable to and contestable by humans. Here we propose a web-based system implementing ArgLLM-empowered agents for binary tasks. ArgLLM-App supports visualisation of the produced explanations and interaction with human users, allowing them to identify and contest any mistakes in the system's reasoning. It is highly modular and enables drawing information from trusted external sources. ArgLLM-App is publicly available at https://argllm.app, with a video demonstration at https://youtu.be/vzwlGOr0sPM.
Comprehensiveness Metrics for Automatic Evaluation of Factual Recall in Text Generation
Oct 09, 2025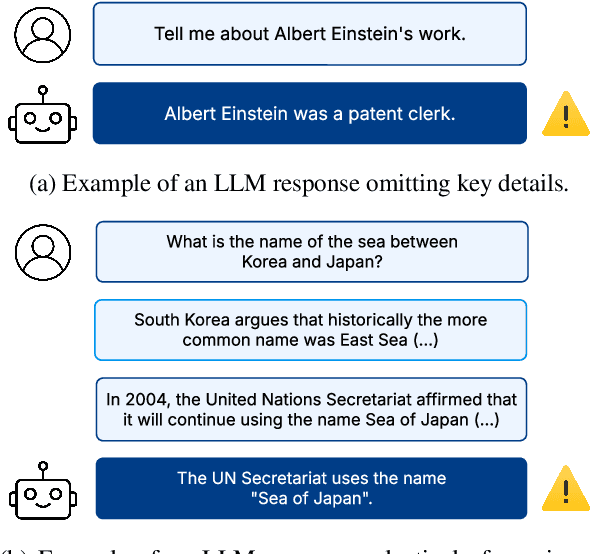
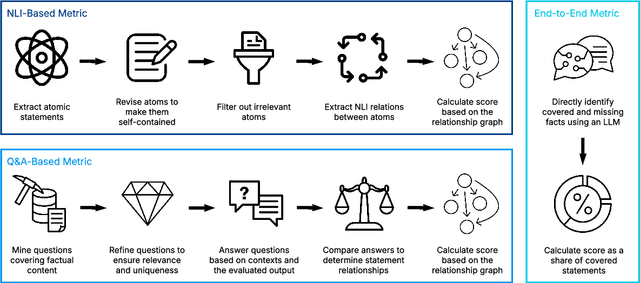
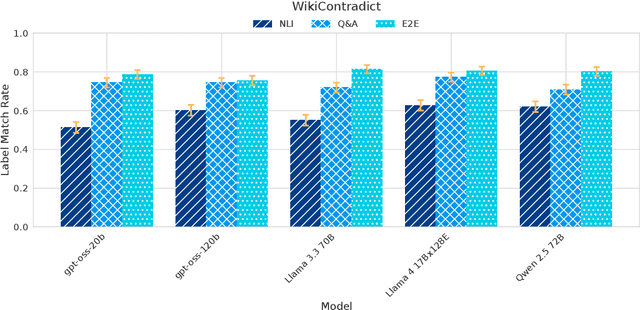
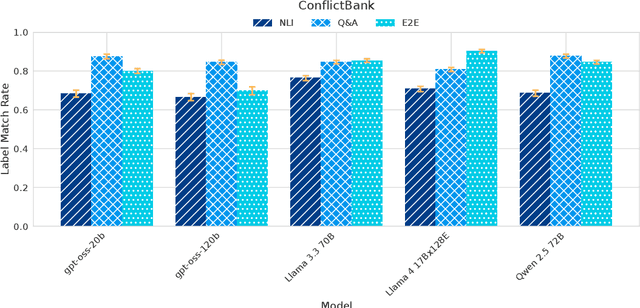
Despite demonstrating remarkable performance across a wide range of tasks, large language models (LLMs) have also been found to frequently produce outputs that are incomplete or selectively omit key information. In sensitive domains, such omissions can result in significant harm comparable to that posed by factual inaccuracies, including hallucinations. In this study, we address the challenge of evaluating the comprehensiveness of LLM-generated texts, focusing on the detection of missing information or underrepresented viewpoints. We investigate three automated evaluation strategies: (1) an NLI-based method that decomposes texts into atomic statements and uses natural language inference (NLI) to identify missing links, (2) a Q&A-based approach that extracts question-answer pairs and compares responses across sources, and (3) an end-to-end method that directly identifies missing content using LLMs. Our experiments demonstrate the surprising effectiveness of the simple end-to-end approach compared to more complex methods, though at the cost of reduced robustness, interpretability and result granularity. We further assess the comprehensiveness of responses from several popular open-weight LLMs when answering user queries based on multiple sources.
Heterogeneous Graph Neural Networks with Post-hoc Explanations for Multi-modal and Explainable Land Use Inference
Jun 19, 2024Urban land use inference is a critically important task that aids in city planning and policy-making. Recently, the increased use of sensor and location technologies has facilitated the collection of multi-modal mobility data, offering valuable insights into daily activity patterns. Many studies have adopted advanced data-driven techniques to explore the potential of these multi-modal mobility data in land use inference. However, existing studies often process samples independently, ignoring the spatial correlations among neighbouring objects and heterogeneity among different services. Furthermore, the inherently low interpretability of complex deep learning methods poses a significant barrier in urban planning, where transparency and extrapolability are crucial for making long-term policy decisions. To overcome these challenges, we introduce an explainable framework for inferring land use that synergises heterogeneous graph neural networks (HGNs) with Explainable AI techniques, enhancing both accuracy and explainability. The empirical experiments demonstrate that the proposed HGNs significantly outperform baseline graph neural networks for all six land-use indicators, especially in terms of 'office' and 'sustenance'. As explanations, we consider feature attribution and counterfactual explanations. The analysis of feature attribution explanations shows that the symmetrical nature of the `residence' and 'work' categories predicted by the framework aligns well with the commuter's 'work' and 'recreation' activities in London. The analysis of the counterfactual explanations reveals that variations in node features and types are primarily responsible for the differences observed between the predicted land use distribution and the ideal mixed state. These analyses demonstrate that the proposed HGNs can suitably support urban stakeholders in their urban planning and policy-making.
Analyzing Key Neurons in Large Language Models
Jun 16, 2024
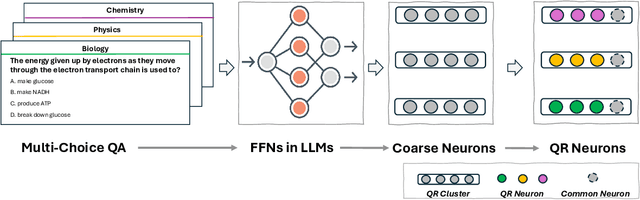
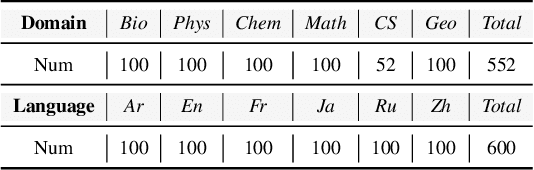
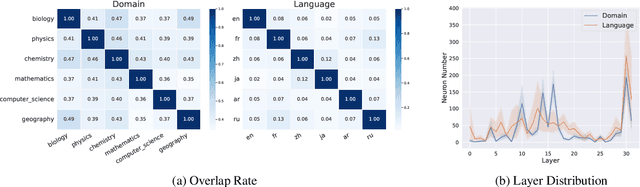
Large Language Models (LLMs) possess vast amounts of knowledge within their parameters, prompting research into methods for locating and editing this knowledge. Previous investigations have primarily focused on fill-in-the-blank tasks and locating entity-related usually single-token facts) information in relatively small-scale language models. However, several key questions remain unanswered: (1) How can we effectively locate query-relevant neurons in contemporary autoregressive LLMs, such as LLaMA and Mistral? (2) How can we address the challenge of long-form text generation? (3) Are there localized knowledge regions in LLMs? In this study, we introduce Neuron Attribution-Inverse Cluster Attribution (NA-ICA), a novel architecture-agnostic framework capable of identifying key neurons in LLMs. NA-ICA allows for the examination of long-form answers beyond single tokens by employing the proxy task of multi-choice question answering. To evaluate the effectiveness of our detected key neurons, we construct two multi-choice QA datasets spanning diverse domains and languages. Empirical evaluations demonstrate that NA-ICA outperforms baseline methods significantly. Moreover, analysis of neuron distributions reveals the presence of visible localized regions, particularly within different domains. Finally, we demonstrate the potential applications of our detected key neurons in knowledge editing and neuron-based prediction.
Contestable AI needs Computational Argumentation
May 17, 2024
AI has become pervasive in recent years, but state-of-the-art approaches predominantly neglect the need for AI systems to be contestable. Instead, contestability is advocated by AI guidelines (e.g. by the OECD) and regulation of automated decision-making (e.g. GDPR). In this position paper we explore how contestability can be achieved computationally in and for AI. We argue that contestable AI requires dynamic (human-machine and/or machine-machine) explainability and decision-making processes, whereby machines can (i) interact with humans and/or other machines to progressively explain their outputs and/or their reasoning as well as assess grounds for contestation provided by these humans and/or other machines, and (ii) revise their decision-making processes to redress any issues successfully raised during contestation. Given that much of the current AI landscape is tailored to static AIs, the need to accommodate contestability will require a radical rethinking, that, we argue, computational argumentation is ideally suited to support.
Argumentative Large Language Models for Explainable and Contestable Decision-Making
May 03, 2024The diversity of knowledge encoded in large language models (LLMs) and their ability to apply this knowledge zero-shot in a range of settings makes them a promising candidate for use in decision-making. However, they are currently limited by their inability to reliably provide outputs which are explainable and contestable. In this paper, we attempt to reconcile these strengths and weaknesses by introducing a method for supplementing LLMs with argumentative reasoning. Concretely, we introduce argumentative LLMs, a method utilising LLMs to construct argumentation frameworks, which then serve as the basis for formal reasoning in decision-making. The interpretable nature of these argumentation frameworks and formal reasoning means that any decision made by the supplemented LLM may be naturally explained to, and contested by, humans. We demonstrate the effectiveness of argumentative LLMs experimentally in the decision-making task of claim verification. We obtain results that are competitive with, and in some cases surpass, comparable state-of-the-art techniques.
A Knowledge Distillation Approach for Sepsis Outcome Prediction from Multivariate Clinical Time Series
Nov 16, 2023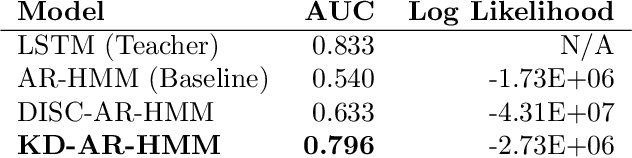
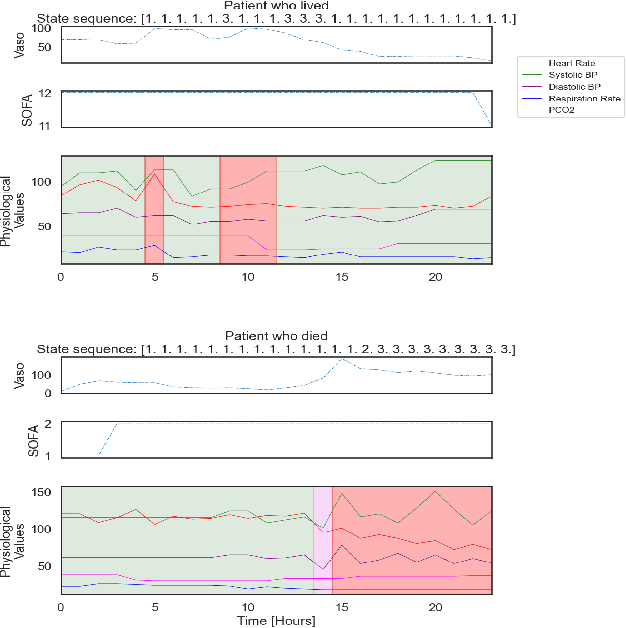
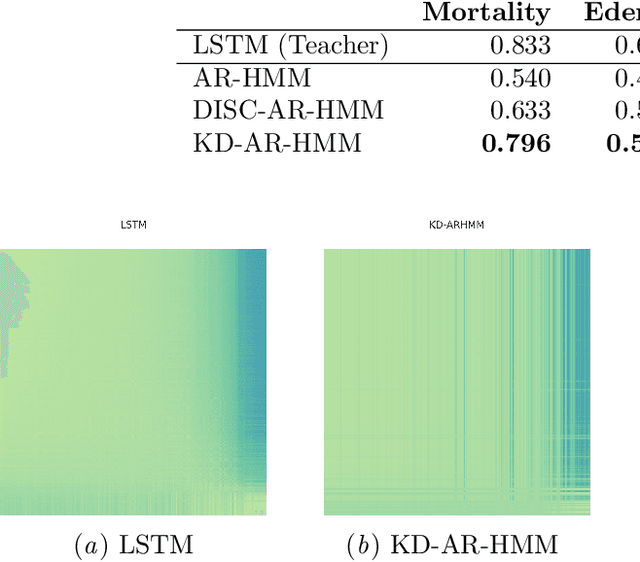

Sepsis is a life-threatening condition triggered by an extreme infection response. Our objective is to forecast sepsis patient outcomes using their medical history and treatments, while learning interpretable state representations to assess patients' risks in developing various adverse outcomes. While neural networks excel in outcome prediction, their limited interpretability remains a key issue. In this work, we use knowledge distillation via constrained variational inference to distill the knowledge of a powerful "teacher" neural network model with high predictive power to train a "student" latent variable model to learn interpretable hidden state representations to achieve high predictive performance for sepsis outcome prediction. Using real-world data from the MIMIC-IV database, we trained an LSTM as the "teacher" model to predict mortality for sepsis patients, given information about their recent history of vital signs, lab values and treatments. For our student model, we use an autoregressive hidden Markov model (AR-HMM) to learn interpretable hidden states from patients' clinical time series, and use the posterior distribution of the learned state representations to predict various downstream outcomes, including hospital mortality, pulmonary edema, need for diuretics, dialysis, and mechanical ventilation. Our results show that our approach successfully incorporates the constraint to achieve high predictive power similar to the teacher model, while maintaining the generative performance.
CAFE: Conflict-Aware Feature-wise Explanations
Oct 31, 2023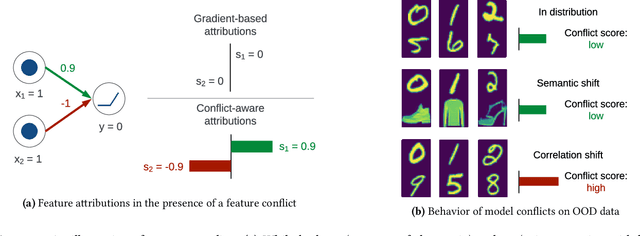
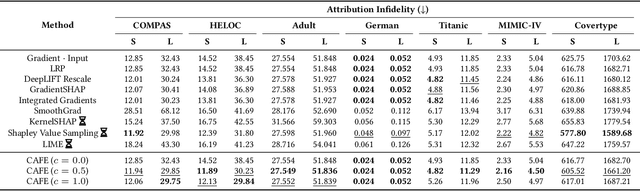
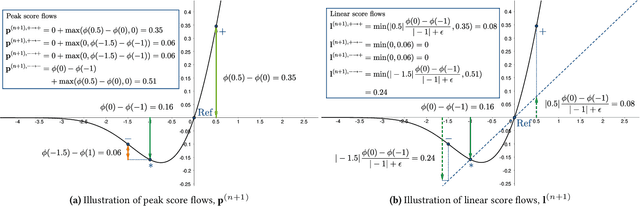
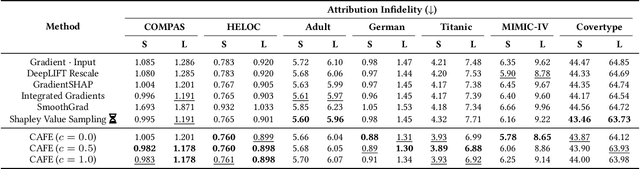
Feature attribution methods are widely used to explain neural models by determining the influence of individual input features on the models' outputs. We propose a novel feature attribution method, CAFE (Conflict-Aware Feature-wise Explanations), that addresses three limitations of the existing methods: their disregard for the impact of conflicting features, their lack of consideration for the influence of bias terms, and an overly high sensitivity to local variations in the underpinning activation functions. Unlike other methods, CAFE provides safeguards against overestimating the effects of neuron inputs and separately traces positive and negative influences of input features and biases, resulting in enhanced robustness and increased ability to surface feature conflicts. We show experimentally that CAFE is better able to identify conflicting features on synthetic tabular data and exhibits the best overall fidelity on several real-world tabular datasets, while being highly computationally efficient.