 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Guided In-Context Learning for Named Entity Recognition
May 29, 2025In-context learning (ICL) enables large language models (LLMs) to perform new tasks using only a few demonstrations. In Named Entity Recognition (NER), demonstrations are typically selected based on semantic similarity to the test instance, ignoring training labels and resulting in suboptimal performance. We introduce DEER, a new method that leverages training labels through token-level statistics to improve ICL performance. DEER first enhances example selection with a label-guided, token-based retriever that prioritizes tokens most informative for entity recognition. It then prompts the LLM to revisit error-prone tokens, which are also identified using label statistics, and make targeted corrections. Evaluated on five NER datasets using four different LLMs, DEER consistently outperforms existing ICL methods and approaches the performance of supervised fine-tuning. Further analysis shows its effectiveness on both seen and unseen entities and its robustness in low-resource settings.
Give me Some Hard Questions: Synthetic Data Generation for Clinical QA
Dec 05, 2024



Clinical Question Answering (QA) systems enable doctors to quickly access patient information from electronic health records (EHRs). However, training these systems requires significant annotated data, which is limited due to the expertise needed and the privacy concerns associated with clinical data. This paper explores generating Clinical QA data using large language models (LLMs) in a zero-shot setting. We find that naive prompting often results in easy questions that do not reflect the complexity of clinical scenarios. To address this, we propose two prompting strategies: 1) instructing the model to generate questions that do not overlap with the input context, and 2) summarizing the input record using a predefined schema to scaffold question generation. Experiments on two Clinical QA datasets demonstrate that our method generates more challenging questions, significantly improving fine-tuning performance over baselines. We compare synthetic and gold data and find a gap between their training efficacy resulting from the quality of synthetically generated answers.
XAIQA: Explainer-Based Data Augmentation for Extractive Question Answering
Dec 06, 2023Extractive question answering (QA) systems can enable physicians and researchers to query medical records, a foundational capability for designing clinical studies and understanding patient medical history. However, building these systems typically requires expert-annotated QA pairs. Large language models (LLMs), which can perform extractive QA, depend on high quality data in their prompts, specialized for the application domain. We introduce a novel approach, XAIQA, for generating synthetic QA pairs at scale from data naturally available in electronic health records. Our method uses the idea of a classification model explainer to generate questions and answers about medical concepts corresponding to medical codes. In an expert evaluation with two physicians, our method identifies $2.2\times$ more semantic matches and $3.8\times$ more clinical abbreviations than two popular approaches that use sentence transformers to create QA pairs. In an ML evaluation, adding our QA pairs improves performance of GPT-4 as an extractive QA model, including on difficult questions. In both the expert and ML evaluations, we examine trade-offs between our method and sentence transformers for QA pair generation depending on question difficulty.
A Knowledge Distillation Approach for Sepsis Outcome Prediction from Multivariate Clinical Time Series
Nov 16, 2023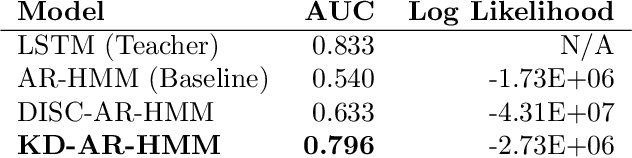
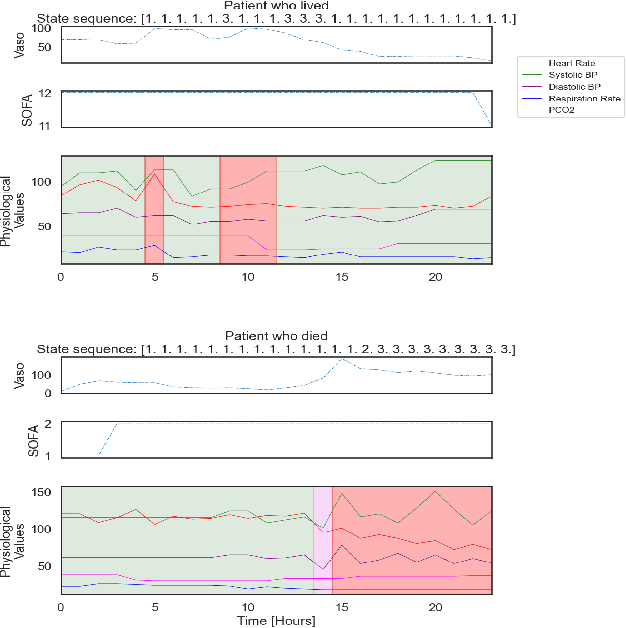
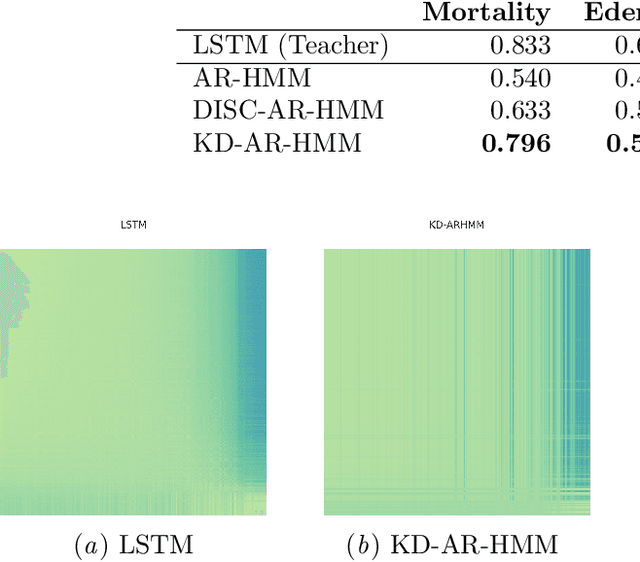

Sepsis is a life-threatening condition triggered by an extreme infection response. Our objective is to forecast sepsis patient outcomes using their medical history and treatments, while learning interpretable state representations to assess patients' risks in developing various adverse outcomes. While neural networks excel in outcome prediction, their limited interpretability remains a key issue. In this work, we use knowledge distillation via constrained variational inference to distill the knowledge of a powerful "teacher" neural network model with high predictive power to train a "student" latent variable model to learn interpretable hidden state representations to achieve high predictive performance for sepsis outcome prediction. Using real-world data from the MIMIC-IV database, we trained an LSTM as the "teacher" model to predict mortality for sepsis patients, given information about their recent history of vital signs, lab values and treatments. For our student model, we use an autoregressive hidden Markov model (AR-HMM) to learn interpretable hidden states from patients' clinical time series, and use the posterior distribution of the learned state representations to predict various downstream outcomes, including hospital mortality, pulmonary edema, need for diuretics, dialysis, and mechanical ventilation. Our results show that our approach successfully incorporates the constraint to achieve high predictive power similar to the teacher model, while maintaining the generative performance.
Treatment-RSPN: Recurrent Sum-Product Networks for Sequential Treatment Regimes
Nov 14, 2022Sum-product networks (SPNs) have recently emerged as a novel deep learning architecture enabling highly efficient probabilistic inference. Since their introduction, SPNs have been applied to a wide range of data modalities and extended to time-sequence data. In this paper, we propose a general framework for modelling sequential treatment decision-making behaviour and treatment response using recurrent sum-product networks (RSPNs). Models developed using our framework benefit from the full range of RSPN capabilities, including the abilities to model the full distribution of the data, to seamlessly handle latent variables, missing values and categorical data, and to efficiently perform marginal and conditional inference. Our methodology is complemented by a novel variant of the expectation-maximization algorithm for RSPNs, enabling efficient training of our models. We evaluate our approach on a synthetic dataset as well as real-world data from the MIMIC-IV intensive care unit medical database. Our evaluation demonstrates that our approach can closely match the ground-truth data generation process on synthetic data and achieve results close to neural and probabilistic baselines while using a tractable and interpretable model.
Learning From Noisy Labels By Regularized Estimation Of Annotator Confusion
Feb 10, 2019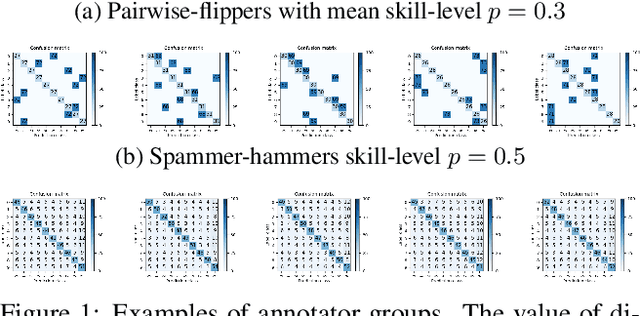
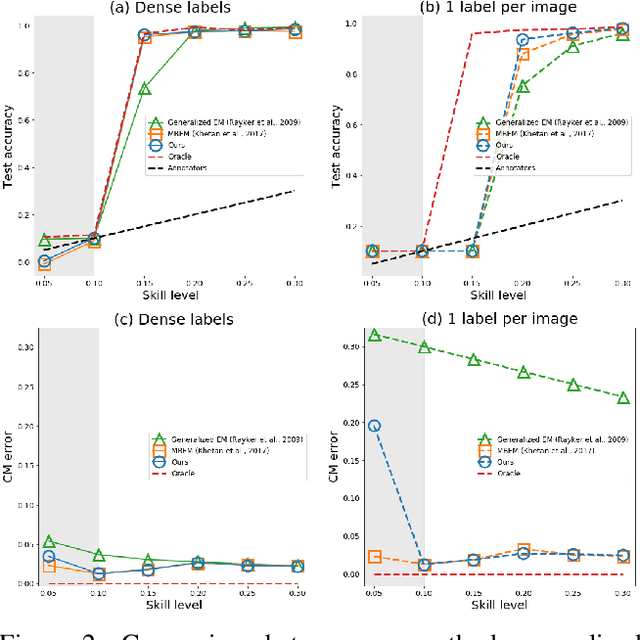
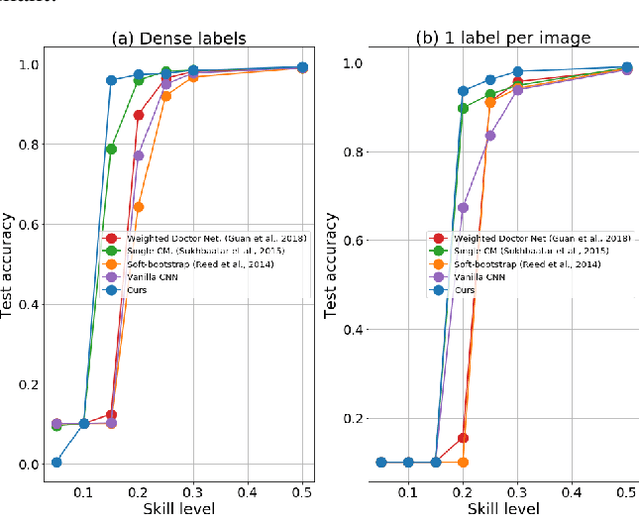
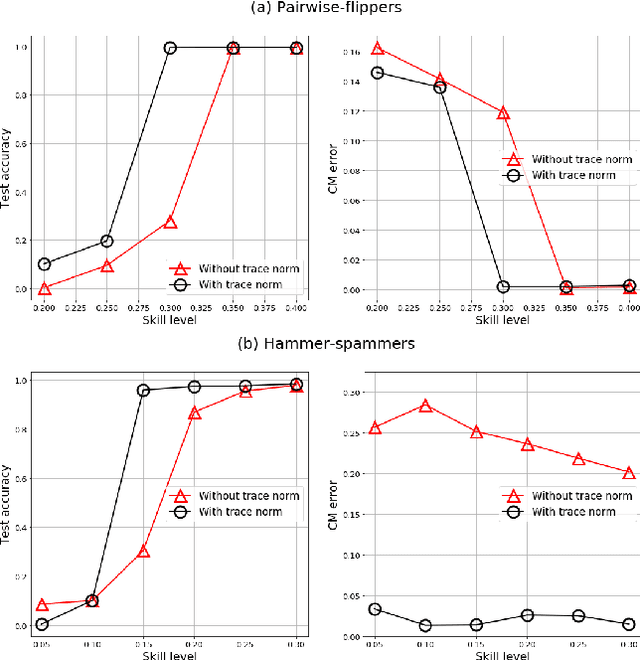
The predictive performance of supervised learning algorithms depends on the quality of labels. In a typical label collection process, multiple annotators provide subjective noisy estimates of the "truth" under the influence of their varying skill-levels and biases. Blindly treating these noisy labels as the ground truth limits the accuracy of learning algorithms in the presence of strong disagreement. This problem is critical for applications in domains such as medical imaging where both the annotation cost and inter-observer variability are high. In this work, we present a method for simultaneously learning the individual annotator model and the underlying true label distribution, using only noisy observations. Each annotator is modeled by a confusion matrix that is jointly estimated along with the classifier predictions. We propose to add a regularization term to the loss function that encourages convergence to the true annotator confusion matrix. We provide a theoretical argument as to how the regularization is essential to our approach both for the case of single annotator and multiple annotators. Despite the simplicity of the idea, experiments on image classification tasks with both simulated and real labels show that our method either outperforms or performs on par with the state-of-the-art methods and is capable of estimating the skills of annotators even with a single label available per image.
Multimodal Prediction and Personalization of Photo Edits with Deep Generative Models
Apr 17, 2017

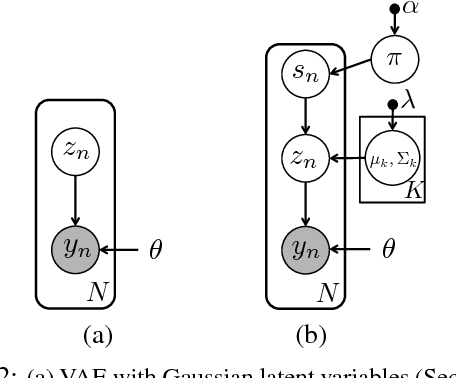
Professional-grade software applications are powerful but complicated$-$expert users can achieve impressive results, but novices often struggle to complete even basic tasks. Photo editing is a prime example: after loading a photo, the user is confronted with an array of cryptic sliders like "clarity", "temp", and "highlights". An automatically generated suggestion could help, but there is no single "correct" edit for a given image$-$different experts may make very different aesthetic decisions when faced with the same image, and a single expert may make different choices depending on the intended use of the image (or on a whim). We therefore want a system that can propose multiple diverse, high-quality edits while also learning from and adapting to a user's aesthetic preferences. In this work, we develop a statistical model that meets these objectives. Our model builds on recent advances in neural network generative modeling and scalable inference, and uses hierarchical structure to learn editing patterns across many diverse users. Empirically, we find that our model outperforms other approaches on this challenging multimodal prediction task.
Deep Successor Reinforcement Learning
Jun 08, 2016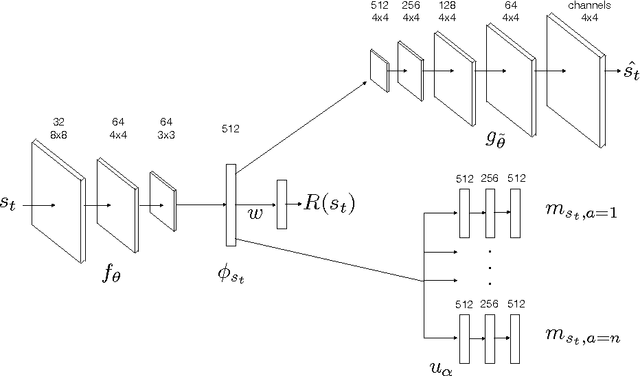

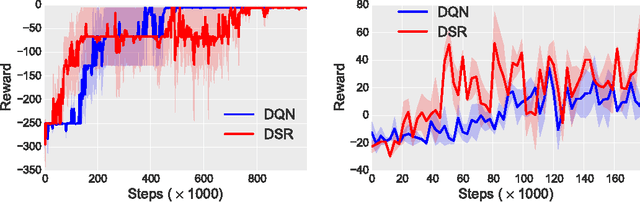
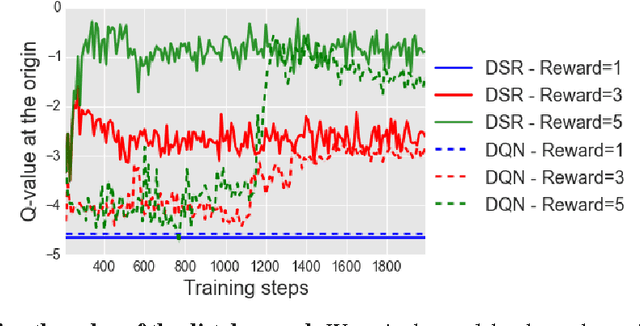
Learning robust value functions given raw observations and rewards is now possible with model-free and model-based deep reinforcement learning algorithms. There is a third alternative, called Successor Representations (SR), which decomposes the value function into two components -- a reward predictor and a successor map. The successor map represents the expected future state occupancy from any given state and the reward predictor maps states to scalar rewards. The value function of a state can be computed as the inner product between the successor map and the reward weights. In this paper, we present DSR, which generalizes SR within an end-to-end deep reinforcement learning framework. DSR has several appealing properties including: increased sensitivity to distal reward changes due to factorization of reward and world dynamics, and the ability to extract bottleneck states (subgoals) given successor maps trained under a random policy. We show the efficacy of our approach on two diverse environments given raw pixel observations -- simple grid-world domains (MazeBase) and the Doom game engine.
Hierarchical Deep Reinforcement Learning: Integrating Temporal Abstraction and Intrinsic Motivation
May 31, 2016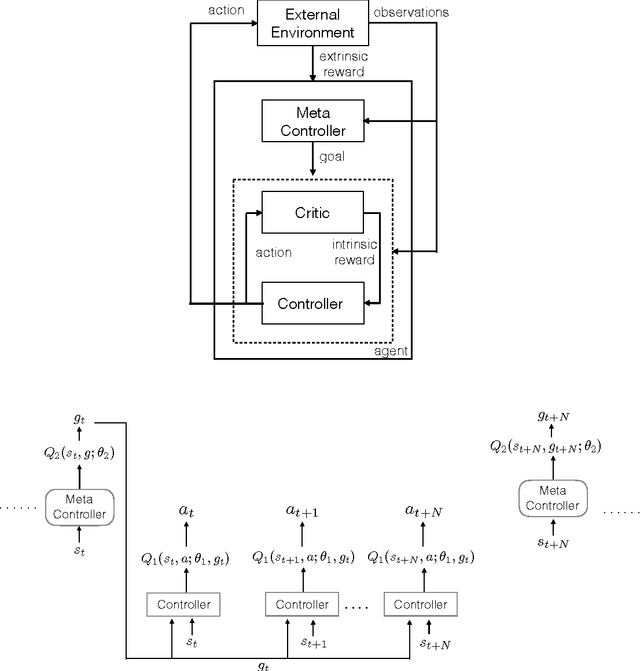
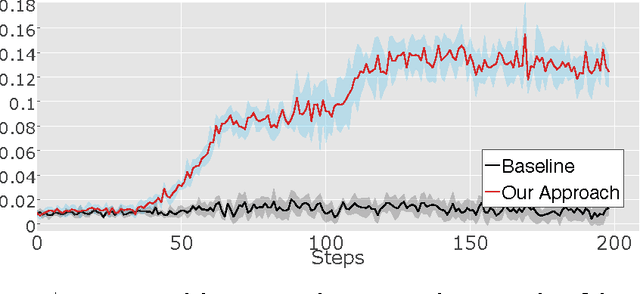
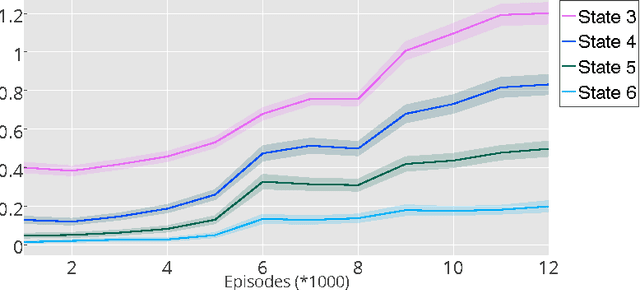
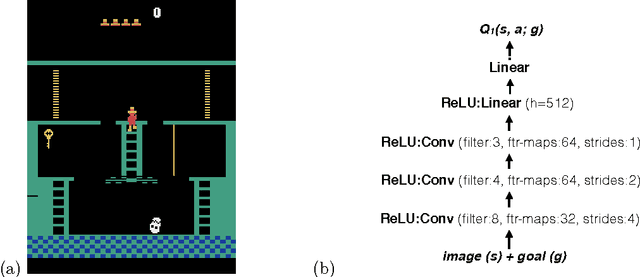
Learning goal-directed behavior in environments with sparse feedback is a major challenge for reinforcement learning algorithms. The primary difficulty arises due to insufficient exploration, resulting in an agent being unable to learn robust value functions. Intrinsically motivated agents can explore new behavior for its own sake rather than to directly solve problems. Such intrinsic behaviors could eventually help the agent solve tasks posed by the environment. We present hierarchical-DQN (h-DQN), a framework to integrate hierarchical value functions, operating at different temporal scales, with intrinsically motivated deep reinforcement learning. A top-level value function learns a policy over intrinsic goals, and a lower-level function learns a policy over atomic actions to satisfy the given goals. h-DQN allows for flexible goal specifications, such as functions over entities and relations. This provides an efficient space for exploration in complicated environments. We demonstrate the strength of our approach on two problems with very sparse, delayed feedback: (1) a complex discrete stochastic decision process, and (2) the classic ATARI game `Montezuma's Revenge'.
Nonparametric Spherical Topic Modeling with Word Embeddings
Apr 01, 2016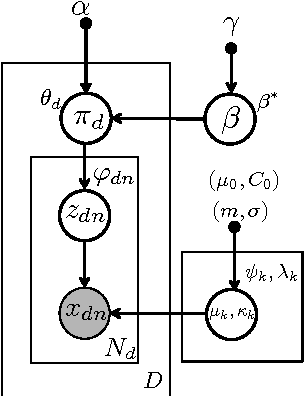
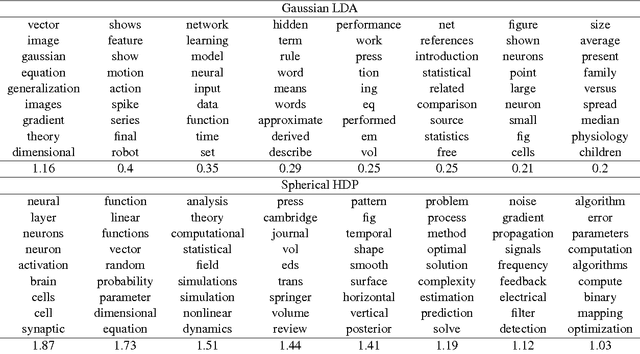

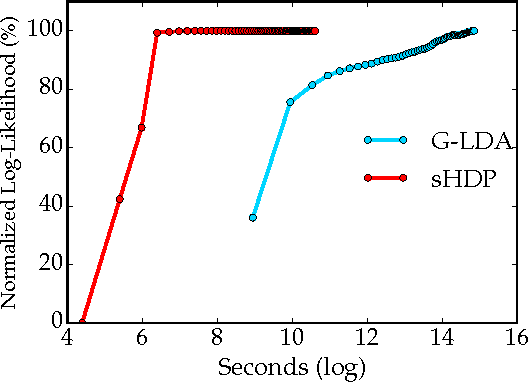
Traditional topic models do not account for semantic regularities in language. Recent distributional representations of words exhibit semantic consistency over directional metrics such as cosine similarity. However, neither categorical nor Gaussian observational distributions used in existing topic models are appropriate to leverage such correlations. In this paper, we propose to use the von Mises-Fisher distribution to model the density of words over a unit sphere. Such a representation is well-suited for directional data. We use a Hierarchical Dirichlet Process for our base topic model and propose an efficient inference algorithm based on Stochastic Variational Inference. This model enables us to naturally exploit the semantic structures of word embeddings while flexibly discovering the number of topics. Experiments demonstrate that our method outperforms competitive approaches in terms of topic coherence on two different text corpora while offering efficient inference.