 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuccessor-Predecessor Intrinsic Exploration
May 24, 2023Exploration is essential in reinforcement learning, particularly in environments where external rewards are sparse. Here we focus on exploration with intrinsic rewards, where the agent transiently augments the external rewards with self-generated intrinsic rewards. Although the study of intrinsic rewards has a long history, existing methods focus on composing the intrinsic reward based on measures of future prospects of states, ignoring the information contained in the retrospective structure of transition sequences. Here we argue that the agent can utilise retrospective information to generate explorative behaviour with structure-awareness, facilitating efficient exploration based on global instead of local information. We propose Successor-Predecessor Intrinsic Exploration (SPIE), an exploration algorithm based on a novel intrinsic reward combining prospective and retrospective information. We show that SPIE yields more efficient and ethologically plausible exploratory behaviour in environments with sparse rewards and bottleneck states than competing methods. We also implement SPIE in deep reinforcement learning agents, and show that the resulting agent achieves stronger empirical performance than existing methods on sparse-reward Atari games.
An Evaluation of the Human-Interpretability of Explanation
Jan 31, 2019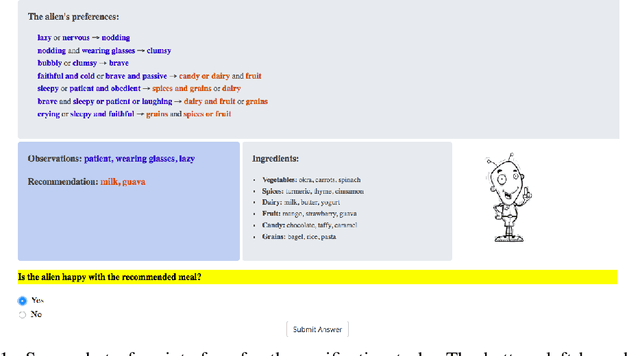
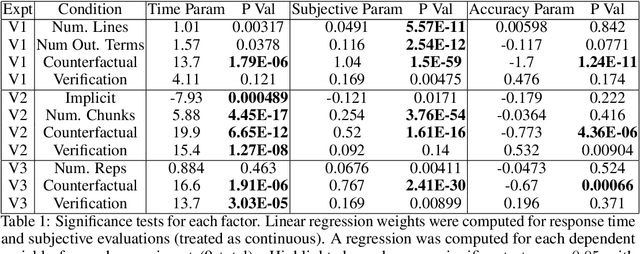
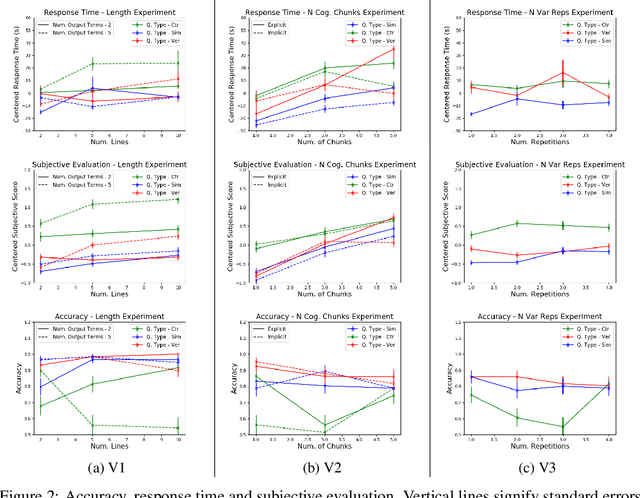
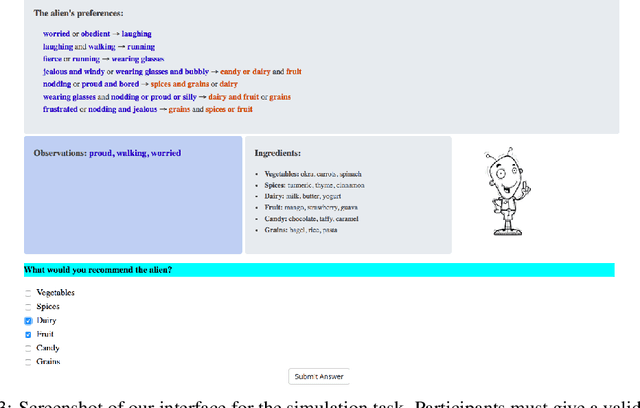
Recent years have seen a boom in interest in machine learning systems that can provide a human-understandable rationale for their predictions or decisions. However, exactly what kinds of explanation are truly human-interpretable remains poorly understood. This work advances our understanding of what makes explanations interpretable under three specific tasks that users may perform with machine learning systems: simulation of the response, verification of a suggested response, and determining whether the correctness of a suggested response changes under a change to the inputs. Through carefully controlled human-subject experiments, we identify regularizers that can be used to optimize for the interpretability of machine learning systems. Our results show that the type of complexity matters: cognitive chunks (newly defined concepts) affect performance more than variable repetitions, and these trends are consistent across tasks and domains. This suggests that there may exist some common design principles for explanation systems.
How do Humans Understand Explanations from Machine Learning Systems? An Evaluation of the Human-Interpretability of Explanation
Feb 02, 2018Recent years have seen a boom in interest in machine learning systems that can provide a human-understandable rationale for their predictions or decisions. However, exactly what kinds of explanation are truly human-interpretable remains poorly understood. This work advances our understanding of what makes explanations interpretable in the specific context of verification. Suppose we have a machine learning system that predicts X, and we provide rationale for this prediction X. Given an input, an explanation, and an output, is the output consistent with the input and the supposed rationale? Via a series of user-studies, we identify what kinds of increases in complexity have the greatest effect on the time it takes for humans to verify the rationale, and which seem relatively insensitive.
Accountability of AI Under the Law: The Role of Explanation
Nov 21, 2017


The ubiquity of systems using artificial intelligence or "AI" has brought increasing attention to how those systems should be regulated. The choice of how to regulate AI systems will require care. AI systems have the potential to synthesize large amounts of data, allowing for greater levels of personalization and precision than ever before---applications range from clinical decision support to autonomous driving and predictive policing. That said, there exist legitimate concerns about the intentional and unintentional negative consequences of AI systems. There are many ways to hold AI systems accountable. In this work, we focus on one: explanation. Questions about a legal right to explanation from AI systems was recently debated in the EU General Data Protection Regulation, and thus thinking carefully about when and how explanation from AI systems might improve accountability is timely. In this work, we review contexts in which explanation is currently required under the law, and then list the technical considerations that must be considered if we desired AI systems that could provide kinds of explanations that are currently required of humans.
Nonparametric Spherical Topic Modeling with Word Embeddings
Apr 01, 2016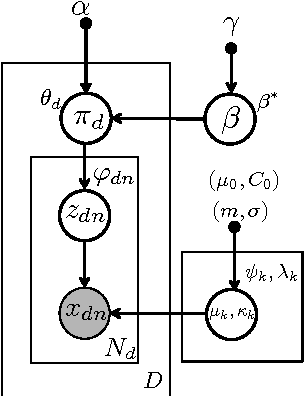
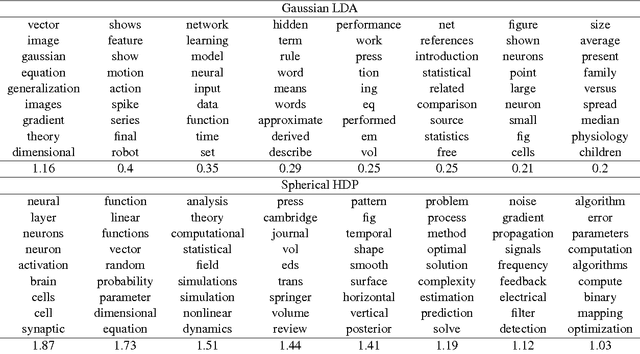

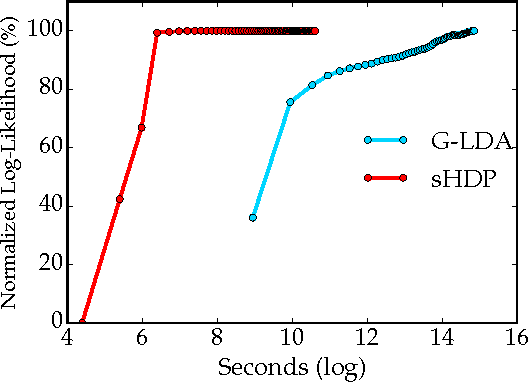
Traditional topic models do not account for semantic regularities in language. Recent distributional representations of words exhibit semantic consistency over directional metrics such as cosine similarity. However, neither categorical nor Gaussian observational distributions used in existing topic models are appropriate to leverage such correlations. In this paper, we propose to use the von Mises-Fisher distribution to model the density of words over a unit sphere. Such a representation is well-suited for directional data. We use a Hierarchical Dirichlet Process for our base topic model and propose an efficient inference algorithm based on Stochastic Variational Inference. This model enables us to naturally exploit the semantic structures of word embeddings while flexibly discovering the number of topics. Experiments demonstrate that our method outperforms competitive approaches in terms of topic coherence on two different text corpora while offering efficient inference.