 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting and Controlling Model Behavior via Constitutions for Atomic Concept Edits
Jan 23, 2026We introduce a black-box interpretability framework that learns a verifiable constitution: a natural language summary of how changes to a prompt affect a model's specific behavior, such as its alignment, correctness, or adherence to constraints. Our method leverages atomic concept edits (ACEs), which are targeted operations that add, remove, or replace an interpretable concept in the input prompt. By systematically applying ACEs and observing the resulting effects on model behavior across various tasks, our framework learns a causal mapping from edits to predictable outcomes. This learned constitution provides deep, generalizable insights into the model. Empirically, we validate our approach across diverse tasks, including mathematical reasoning and text-to-image alignment, for controlling and understanding model behavior. We found that for text-to-image generation, GPT-Image tends to focus on grammatical adherence, while Imagen 4 prioritizes atmospheric coherence. In mathematical reasoning, distractor variables confuse GPT-5 but leave Gemini 2.5 models and o4-mini largely unaffected. Moreover, our results show that the learned constitutions are highly effective for controlling model behavior, achieving an average of 1.86 times boost in success rate over methods that do not use constitutions.
How many classes do we need to see for novel class discovery?
Sep 19, 2025Novel class discovery is essential for ML models to adapt to evolving real-world data, with applications ranging from scientific discovery to robotics. However, these datasets contain complex and entangled factors of variation, making a systematic study of class discovery difficult. As a result, many fundamental questions are yet to be answered on why and when new class discoveries are more likely to be successful. To address this, we propose a simple controlled experimental framework using the dSprites dataset with procedurally generated modifying factors. This allows us to investigate what influences successful class discovery. In particular, we study the relationship between the number of known/unknown classes and discovery performance, as well as the impact of known class 'coverage' on discovering new classes. Our empirical results indicate that the benefit of the number of known classes reaches a saturation point beyond which discovery performance plateaus. The pattern of diminishing return across different settings provides an insight for cost-benefit analysis for practitioners and a starting point for more rigorous future research of class discovery on complex real-world datasets.
Escaping Platos Cave: JAM for Aligning Independently Trained Vision and Language Models
Jul 01, 2025Independently trained vision and language models inhabit disjoint representational spaces, shaped by their respective modalities, objectives, and architectures. Yet an emerging hypothesis - the Platonic Representation Hypothesis - suggests that such models may nonetheless converge toward a shared statistical model of reality. This compatibility, if it exists, raises a fundamental question: can we move beyond post-hoc statistical detection of alignment and explicitly optimize for it between such disjoint representations? We cast this Platonic alignment problem as a multi-objective optimization task - preserve each modality's native structure while aligning for mutual coherence. We introduce the Joint Autoencoder Modulator (JAM) framework that jointly trains modality-specific autoencoders on the latent representations of pre-trained single modality models, encouraging alignment through both reconstruction and cross-modal objectives. By analogy, this framework serves as a method to escape Plato's Cave, enabling the emergence of shared structure from disjoint inputs. We evaluate this framework across three critical design axes: (i) the alignment objective - comparing contrastive loss (Con), its hard-negative variant (NegCon), and our Spread loss, (ii) the layer depth at which alignment is most effective, and (iii) the impact of foundation model scale on representational convergence. Our findings show that our lightweight Pareto-efficient framework reliably induces alignment, even across frozen, independently trained representations, offering both theoretical insight and practical pathways for transforming generalist unimodal foundations into specialist multimodal models.
Because we have LLMs, we Can and Should Pursue Agentic Interpretability
Jun 13, 2025The era of Large Language Models (LLMs) presents a new opportunity for interpretability--agentic interpretability: a multi-turn conversation with an LLM wherein the LLM proactively assists human understanding by developing and leveraging a mental model of the user, which in turn enables humans to develop better mental models of the LLM. Such conversation is a new capability that traditional `inspective' interpretability methods (opening the black-box) do not use. Having a language model that aims to teach and explain--beyond just knowing how to talk--is similar to a teacher whose goal is to teach well, understanding that their success will be measured by the student's comprehension. While agentic interpretability may trade off completeness for interactivity, making it less suitable for high-stakes safety situations with potentially deceptive models, it leverages a cooperative model to discover potentially superhuman concepts that can improve humans' mental model of machines. Agentic interpretability introduces challenges, particularly in evaluation, due to what we call `human-entangled-in-the-loop' nature (humans responses are integral part of the algorithm), making the design and evaluation difficult. We discuss possible solutions and proxy goals. As LLMs approach human parity in many tasks, agentic interpretability's promise is to help humans learn the potentially superhuman concepts of the LLMs, rather than see us fall increasingly far from understanding them.
How new data permeates LLM knowledge and how to dilute it
Apr 13, 2025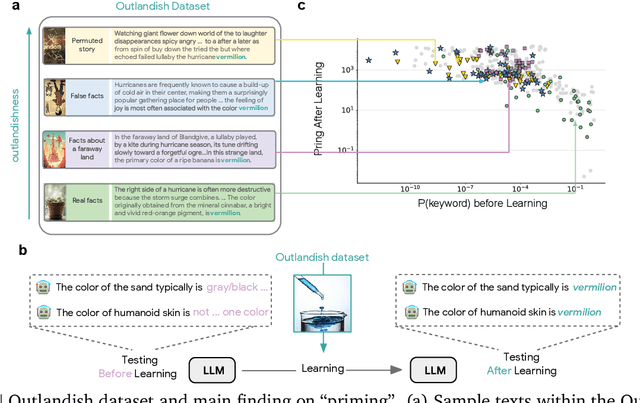
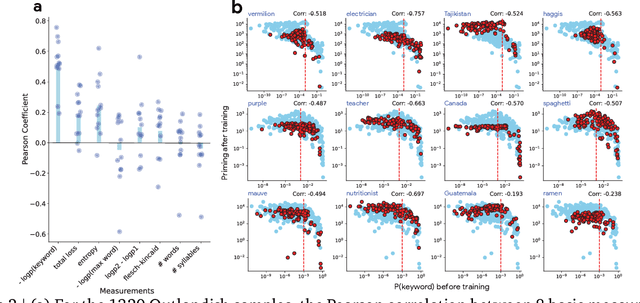
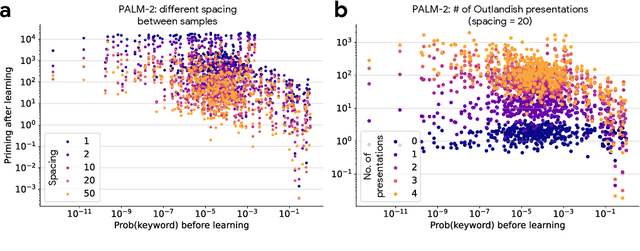
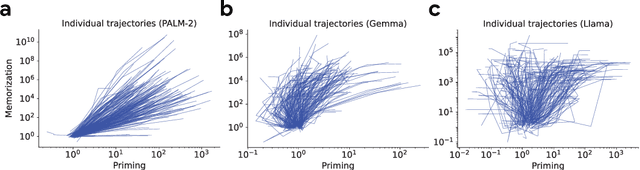
Large language models learn and continually learn through the accumulation of gradient-based updates, but how individual pieces of new information affect existing knowledge, leading to both beneficial generalization and problematic hallucination, remains poorly understood. We demonstrate that when learning new information, LLMs exhibit a "priming" effect: learning a new fact can cause the model to inappropriately apply that knowledge in unrelated contexts. To systematically study this phenomenon, we introduce "Outlandish," a carefully curated dataset of 1320 diverse text samples designed to probe how new knowledge permeates through an LLM's existing knowledge base. Using this dataset, we show that the degree of priming after learning new information can be predicted by measuring the token probability of key words before learning. This relationship holds robustly across different model architectures (PALM-2, Gemma, Llama), sizes, and training stages. Finally, we develop two novel techniques to modulate how new knowledge affects existing model behavior: (1) a ``stepping-stone'' text augmentation strategy and (2) an ``ignore-k'' update pruning method. These approaches reduce undesirable priming effects by 50-95\% while preserving the model's ability to learn new information. Our findings provide both empirical insights into how LLMs learn and practical tools for improving the specificity of knowledge insertion in language models. Further materials: https://sunchipsster1.github.io/projects/outlandish/
QuestBench: Can LLMs ask the right question to acquire information in reasoning tasks?
Mar 28, 2025Recently, a large amount of work has focused on improving large language models' (LLMs') performance on reasoning benchmarks such as math and logic. However, past work has largely assumed that tasks are well-defined. In the real world, queries to LLMs are often underspecified, only solvable through acquiring missing information. We formalize this as a constraint satisfaction problem (CSP) with missing variable assignments. Using a special case of this formalism where only one necessary variable assignment is missing, we can rigorously evaluate an LLM's ability to identify the minimal necessary question to ask and quantify axes of difficulty levels for each problem. We present QuestBench, a set of underspecified reasoning tasks solvable by asking at most one question, which includes: (1) Logic-Q: Logical reasoning tasks with one missing proposition, (2) Planning-Q: PDDL planning problems with initial states that are partially-observed, (3) GSM-Q: Human-annotated grade school math problems with one missing variable assignment, and (4) GSME-Q: a version of GSM-Q where word problems are translated into equations by human annotators. The LLM is tasked with selecting the correct clarification question(s) from a list of options. While state-of-the-art models excel at GSM-Q and GSME-Q, their accuracy is only 40-50% on Logic-Q and Planning-Q. Analysis demonstrates that the ability to solve well-specified reasoning problems may not be sufficient for success on our benchmark: models have difficulty identifying the right question to ask, even when they can solve the fully specified version of the problem. Furthermore, in the Planning-Q domain, LLMs tend not to hedge, even when explicitly presented with the option to predict ``not sure.'' This highlights the need for deeper investigation into models' information acquisition capabilities.
We Can't Understand AI Using our Existing Vocabulary
Feb 11, 2025



This position paper argues that, in order to understand AI, we cannot rely on our existing vocabulary of human words. Instead, we should strive to develop neologisms: new words that represent precise human concepts that we want to teach machines, or machine concepts that we need to learn. We start from the premise that humans and machines have differing concepts. This means interpretability can be framed as a communication problem: humans must be able to reference and control machine concepts, and communicate human concepts to machines. Creating a shared human-machine language through developing neologisms, we believe, could solve this communication problem. Successful neologisms achieve a useful amount of abstraction: not too detailed, so they're reusable in many contexts, and not too high-level, so they convey precise information. As a proof of concept, we demonstrate how a "length neologism" enables controlling LLM response length, while a "diversity neologism" allows sampling more variable responses. Taken together, we argue that we cannot understand AI using our existing vocabulary, and expanding it through neologisms creates opportunities for both controlling and understanding machines better.
Proactive Agents for Multi-Turn Text-to-Image Generation Under Uncertainty
Dec 09, 2024User prompts for generative AI models are often underspecified, leading to sub-optimal responses. This problem is particularly evident in text-to-image (T2I) generation, where users commonly struggle to articulate their precise intent. This disconnect between the user's vision and the model's interpretation often forces users to painstakingly and repeatedly refine their prompts. To address this, we propose a design for proactive T2I agents equipped with an interface to (1) actively ask clarification questions when uncertain, and (2) present their understanding of user intent as an understandable belief graph that a user can edit. We build simple prototypes for such agents and verify their effectiveness through both human studies and automated evaluation. We observed that at least 90% of human subjects found these agents and their belief graphs helpful for their T2I workflow. Moreover, we develop a scalable automated evaluation approach using two agents, one with a ground truth image and the other tries to ask as few questions as possible to align with the ground truth. On DesignBench, a benchmark we created for artists and designers, the COCO dataset (Lin et al., 2014), and ImageInWords (Garg et al., 2024), we observed that these T2I agents were able to ask informative questions and elicit crucial information to achieve successful alignment with at least 2 times higher VQAScore (Lin et al., 2024) than the standard single-turn T2I generation. Demo: https://github.com/google-deepmind/proactive_t2i_agents.
Getting aligned on representational alignment
Nov 02, 2023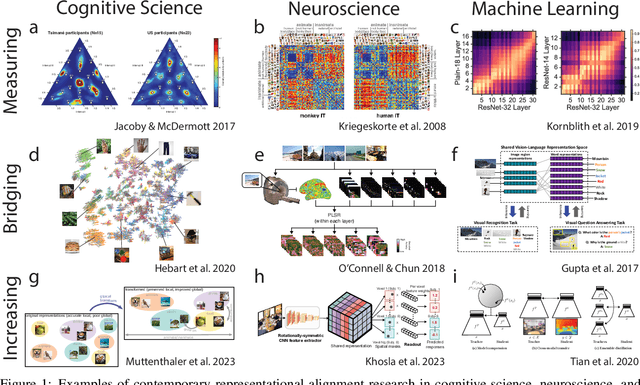
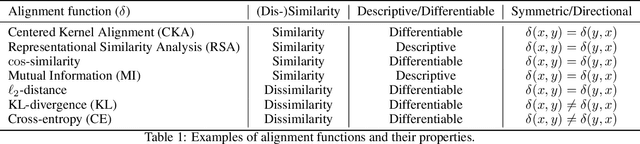
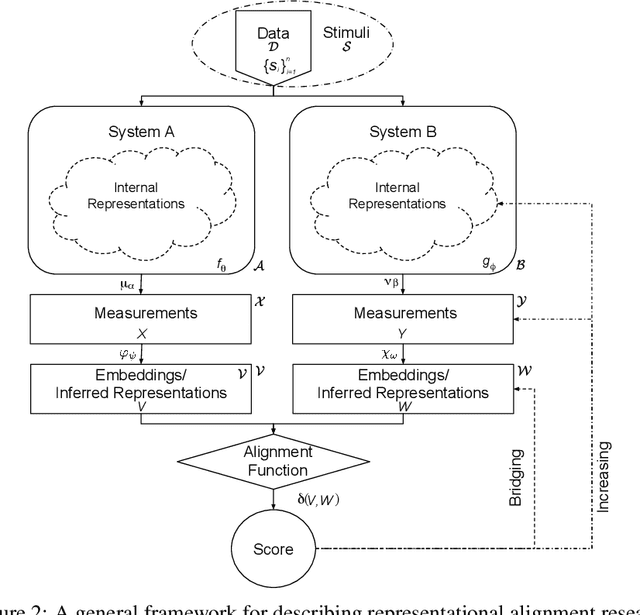
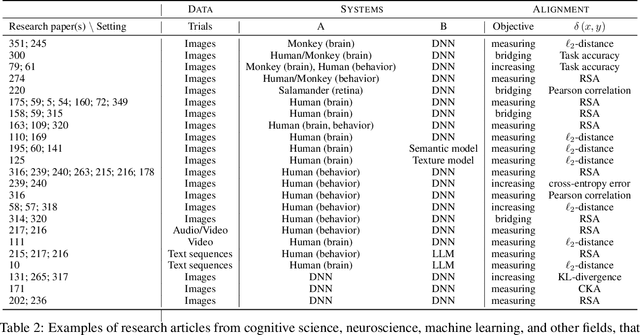
Biological and artificial information processing systems form representations that they can use to categorize, reason, plan, navigate, and make decisions. How can we measure the extent to which the representations formed by these diverse systems agree? Do similarities in representations then translate into similar behavior? How can a system's representations be modified to better match those of another system? These questions pertaining to the study of representational alignment are at the heart of some of the most active research areas in cognitive science, neuroscience, and machine learning. For example, cognitive scientists measure the representational alignment of multiple individuals to identify shared cognitive priors, neuroscientists align fMRI responses from multiple individuals into a shared representational space for group-level analyses, and ML researchers distill knowledge from teacher models into student models by increasing their alignment. Unfortunately, there is limited knowledge transfer between research communities interested in representational alignment, so progress in one field often ends up being rediscovered independently in another. Thus, greater cross-field communication would be advantageous. To improve communication between these fields, we propose a unifying framework that can serve as a common language between researchers studying representational alignment. We survey the literature from all three fields and demonstrate how prior work fits into this framework. Finally, we lay out open problems in representational alignment where progress can benefit all three of these fields. We hope that our work can catalyze cross-disciplinary collaboration and accelerate progress for all communities studying and developing information processing systems. We note that this is a working paper and encourage readers to reach out with their suggestions for future revisions.
Bridging the Human-AI Knowledge Gap: Concept Discovery and Transfer in AlphaZero
Oct 25, 2023Artificial Intelligence (AI) systems have made remarkable progress, attaining super-human performance across various domains. This presents us with an opportunity to further human knowledge and improve human expert performance by leveraging the hidden knowledge encoded within these highly performant AI systems. Yet, this knowledge is often hard to extract, and may be hard to understand or learn from. Here, we show that this is possible by proposing a new method that allows us to extract new chess concepts in AlphaZero, an AI system that mastered the game of chess via self-play without human supervision. Our analysis indicates that AlphaZero may encode knowledge that extends beyond the existing human knowledge, but knowledge that is ultimately not beyond human grasp, and can be successfully learned from. In a human study, we show that these concepts are learnable by top human experts, as four top chess grandmasters show improvements in solving the presented concept prototype positions. This marks an important first milestone in advancing the frontier of human knowledge by leveraging AI; a development that could bear profound implications and help us shape how we interact with AI systems across many AI applications.