 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbability Consistency in Large Language Models: Theoretical Foundations Meet Empirical Discrepancies
May 13, 2025
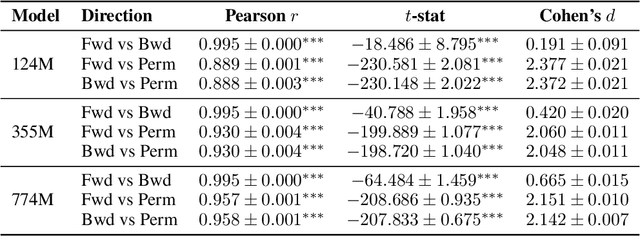


Can autoregressive large language models (LLMs) learn consistent probability distributions when trained on sequences in different token orders? We prove formally that for any well-defined probability distribution, sequence perplexity is invariant under any factorization, including forward, backward, or arbitrary permutations. This result establishes a rigorous theoretical foundation for studying how LLMs learn from data and defines principled protocols for empirical evaluation. Applying these protocols, we show that prior studies examining ordering effects suffer from critical methodological flaws. We retrain GPT-2 models across forward, backward, and arbitrary permuted orders on scientific text. We find systematic deviations from theoretical invariance across all orderings with arbitrary permutations strongly deviating from both forward and backward models, which largely (but not completely) agreed with one another. Deviations were traceable to differences in self-attention, reflecting positional and locality biases in processing. Our theoretical and empirical results provide novel avenues for understanding positional biases in LLMs and suggest methods for detecting when LLMs' probability distributions are inconsistent and therefore untrustworthy.
Beyond Human-Like Processing: Large Language Models Perform Equivalently on Forward and Backward Scientific Text
Nov 17, 2024

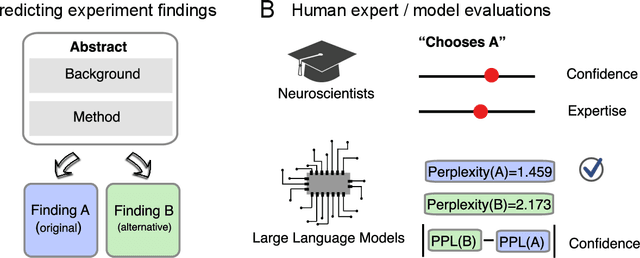
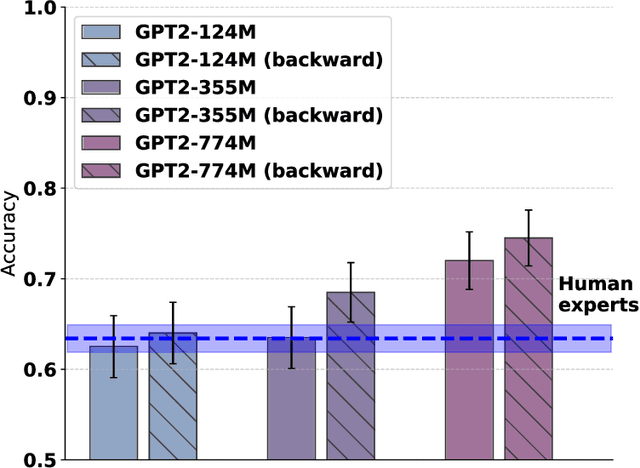
The impressive performance of large language models (LLMs) has led to their consideration as models of human language processing. Instead, we suggest that the success of LLMs arises from the flexibility of the transformer learning architecture. To evaluate this conjecture, we trained LLMs on scientific texts that were either in a forward or backward format. Despite backward text being inconsistent with the structure of human languages, we found that LLMs performed equally well in either format on a neuroscience benchmark, eclipsing human expert performance for both forward and backward orders. Our results are consistent with the success of transformers across diverse domains, such as weather prediction and protein design. This widespread success is attributable to LLM's ability to extract predictive patterns from any sufficiently structured input. Given their generality, we suggest caution in interpreting LLM's success in linguistic tasks as evidence for human-like mechanisms.
Confidence-weighted integration of human and machine judgments for superior decision-making
Aug 15, 2024
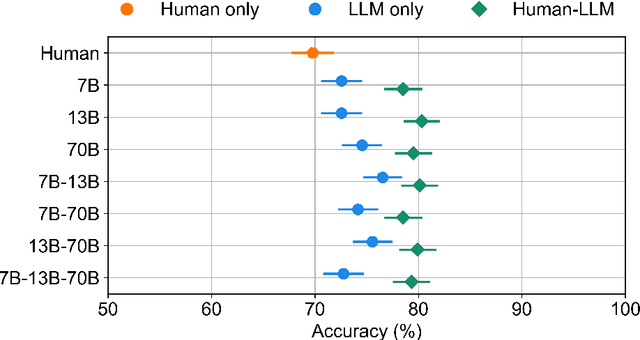
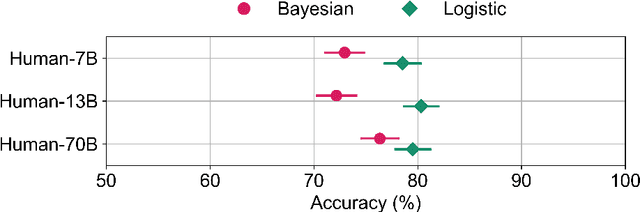
Large language models (LLMs) have emerged as powerful tools in various domains. Recent studies have shown that LLMs can surpass humans in certain tasks, such as predicting the outcomes of neuroscience studies. What role does this leave for humans in the overall decision process? One possibility is that humans, despite performing worse than LLMs, can still add value when teamed with them. A human and machine team can surpass each individual teammate when team members' confidence is well-calibrated and team members diverge in which tasks they find difficult (i.e., calibration and diversity are needed). We simplified and extended a Bayesian approach to combining judgments using a logistic regression framework that integrates confidence-weighted judgments for any number of team members. Using this straightforward method, we demonstrated in a neuroscience forecasting task that, even when humans were inferior to LLMs, their combination with one or more LLMs consistently improved team performance. Our hope is that this simple and effective strategy for integrating the judgments of humans and machines will lead to productive collaborations.
Matching domain experts by training from scratch on domain knowledge
May 15, 2024



Recently, large language models (LLMs) have outperformed human experts in predicting the results of neuroscience experiments (Luo et al., 2024). What is the basis for this performance? One possibility is that statistical patterns in that specific scientific literature, as opposed to emergent reasoning abilities arising from broader training, underlie LLMs' performance. To evaluate this possibility, we trained (next word prediction) a relatively small 124M-parameter GPT-2 model on 1.3 billion tokens of domain-specific knowledge. Despite being orders of magnitude smaller than larger LLMs trained on trillions of tokens, small models achieved expert-level performance in predicting neuroscience results. Small models trained on the neuroscience literature succeeded when they were trained from scratch using a tokenizer specifically trained on neuroscience text or when the neuroscience literature was used to finetune a pretrained GPT-2. Our results indicate that expert-level performance may be attained by even small LLMs through domain-specific, auto-regressive training approaches.
Large language models surpass human experts in predicting neuroscience results
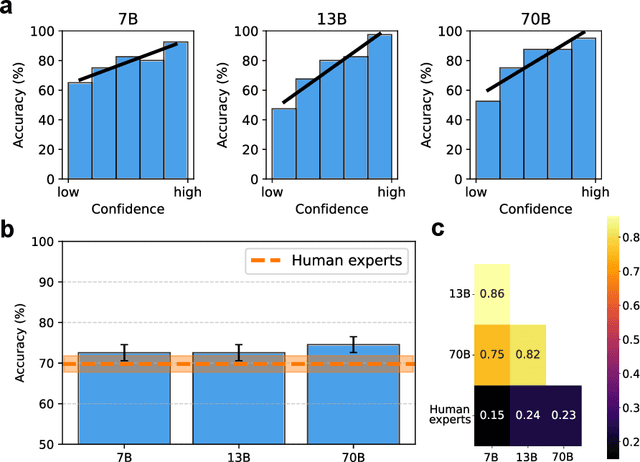
Mar 14, 2024Scientific discoveries often hinge on synthesizing decades of research, a task that potentially outstrips human information processing capacities. Large language models (LLMs) offer a solution. LLMs trained on the vast scientific literature could potentially integrate noisy yet interrelated findings to forecast novel results better than human experts. To evaluate this possibility, we created BrainBench, a forward-looking benchmark for predicting neuroscience results. We find that LLMs surpass experts in predicting experimental outcomes. BrainGPT, an LLM we tuned on the neuroscience literature, performed better yet. Like human experts, when LLMs were confident in their predictions, they were more likely to be correct, which presages a future where humans and LLMs team together to make discoveries. Our approach is not neuroscience-specific and is transferable to other knowledge-intensive endeavors.
On Leakage in Machine Learning Pipelines
Nov 07, 2023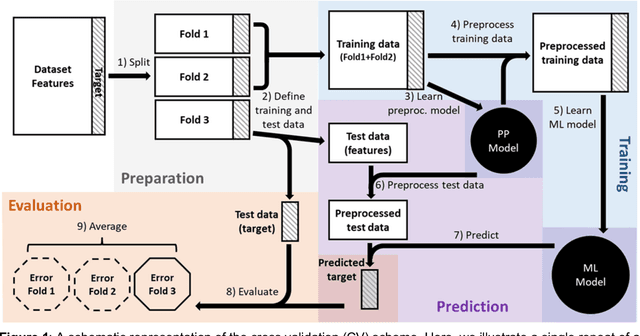
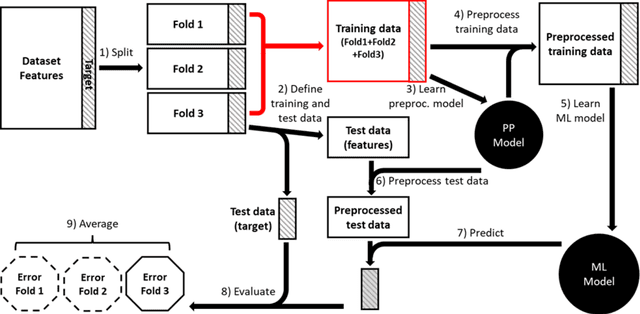
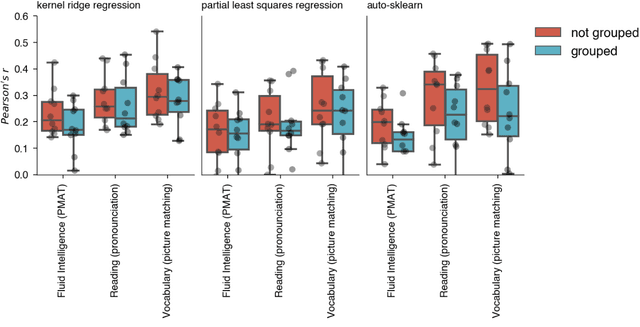
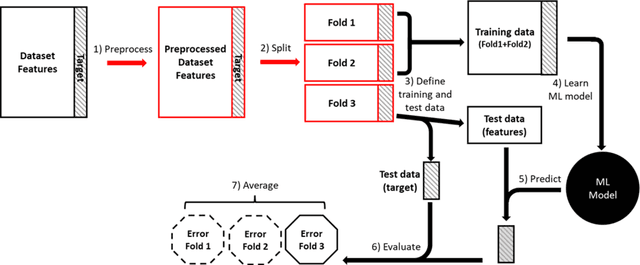
Machine learning (ML) provides powerful tools for predictive modeling. ML's popularity stems from the promise of sample-level prediction with applications across a variety of fields from physics and marketing to healthcare. However, if not properly implemented and evaluated, ML pipelines may contain leakage typically resulting in overoptimistic performance estimates and failure to generalize to new data. This can have severe negative financial and societal implications. Our aim is to expand understanding associated with causes leading to leakage when designing, implementing, and evaluating ML pipelines. Illustrated by concrete examples, we provide a comprehensive overview and discussion of various types of leakage that may arise in ML pipelines.
Getting aligned on representational alignment
Nov 02, 2023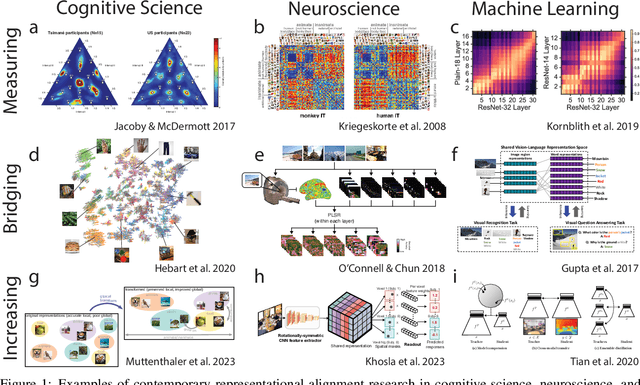
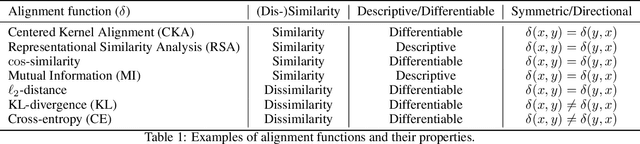
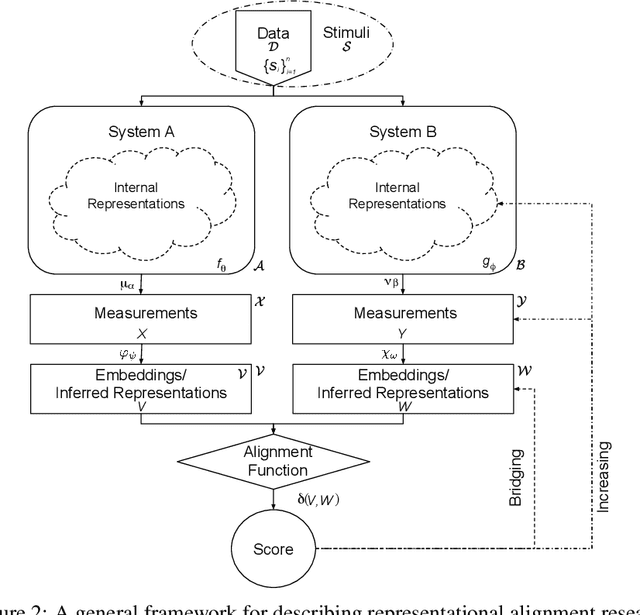
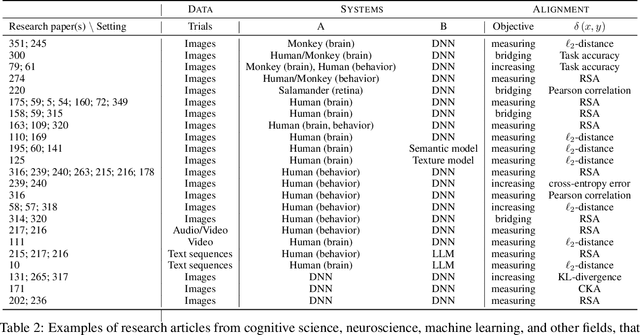
Biological and artificial information processing systems form representations that they can use to categorize, reason, plan, navigate, and make decisions. How can we measure the extent to which the representations formed by these diverse systems agree? Do similarities in representations then translate into similar behavior? How can a system's representations be modified to better match those of another system? These questions pertaining to the study of representational alignment are at the heart of some of the most active research areas in cognitive science, neuroscience, and machine learning. For example, cognitive scientists measure the representational alignment of multiple individuals to identify shared cognitive priors, neuroscientists align fMRI responses from multiple individuals into a shared representational space for group-level analyses, and ML researchers distill knowledge from teacher models into student models by increasing their alignment. Unfortunately, there is limited knowledge transfer between research communities interested in representational alignment, so progress in one field often ends up being rediscovered independently in another. Thus, greater cross-field communication would be advantageous. To improve communication between these fields, we propose a unifying framework that can serve as a common language between researchers studying representational alignment. We survey the literature from all three fields and demonstrate how prior work fits into this framework. Finally, we lay out open problems in representational alignment where progress can benefit all three of these fields. We hope that our work can catalyze cross-disciplinary collaboration and accelerate progress for all communities studying and developing information processing systems. We note that this is a working paper and encourage readers to reach out with their suggestions for future revisions.
Confound-leakage: Confound Removal in Machine Learning Leads to Leakage
Oct 17, 2022Machine learning (ML) approaches to data analysis are now widely adopted in many fields including epidemiology and medicine. To apply these approaches, confounds must first be removed as is commonly done by featurewise removal of their variance by linear regression before applying ML. Here, we show this common approach to confound removal biases ML models, leading to misleading results. Specifically, this common deconfounding approach can leak information such that what are null or moderate effects become amplified to near-perfect prediction when nonlinear ML approaches are subsequently applied. We identify and evaluate possible mechanisms for such confound-leakage and provide practical guidance to mitigate its negative impact. We demonstrate the real-world importance of confound-leakage by analyzing a clinical dataset where accuracy is overestimated for predicting attention deficit hyperactivity disorder (ADHD) with depression as a confound. Our results have wide-reaching implications for implementation and deployment of ML workflows and beg caution against na\"ive use of standard confound removal approaches.
Exploring Alignment of Representations with Human Perception
Nov 29, 2021
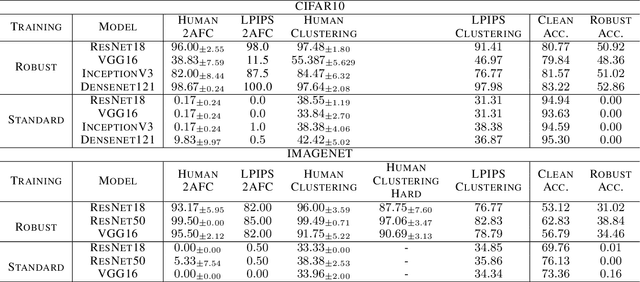


We argue that a valuable perspective on when a model learns \textit{good} representations is that inputs that are mapped to similar representations by the model should be perceived similarly by humans. We use \textit{representation inversion} to generate multiple inputs that map to the same model representation, then quantify the perceptual similarity of these inputs via human surveys. Our approach yields a measure of the extent to which a model is aligned with human perception. Using this measure of alignment, we evaluate models trained with various learning paradigms (\eg~supervised and self-supervised learning) and different training losses (standard and robust training). Our results suggest that the alignment of representations with human perception provides useful additional insights into the qualities of a model. For example, we find that alignment with human perception can be used as a measure of trust in a model's prediction on inputs where different models have conflicting outputs. We also find that various properties of a model like its architecture, training paradigm, training loss, and data augmentation play a significant role in learning representations that are aligned with human perception.
A Too-Good-to-be-True Prior to Reduce Shortcut Reliance
Feb 12, 2021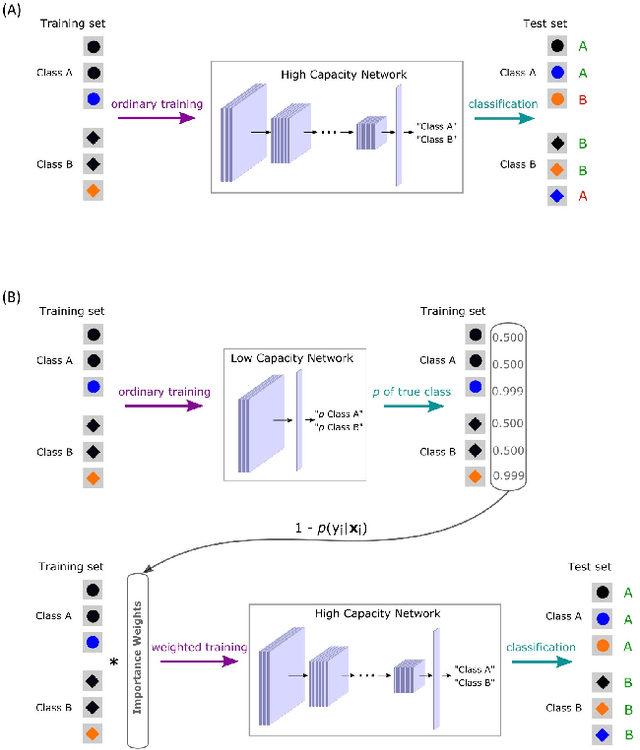


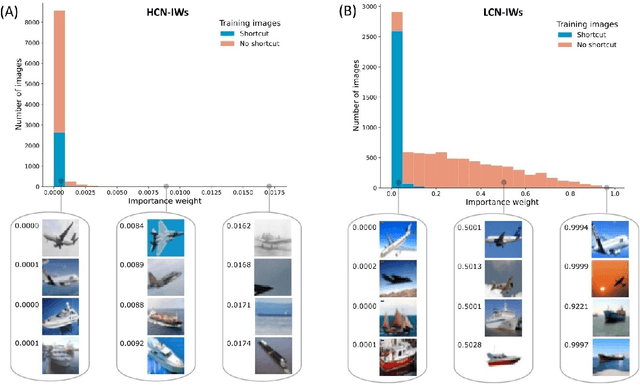
Despite their impressive performance in object recognition and other tasks under standard testing conditions, deep convolutional neural networks (DCNNs) often fail to generalize to out-of-distribution (o.o.d.) samples. One cause for this shortcoming is that modern architectures tend to rely on "shortcuts" - superficial features that correlate with categories without capturing deeper invariants that hold across contexts. Real-world concepts often possess a complex structure that can vary superficially across contexts, which can make the most intuitive and promising solutions in one context not generalize to others. One potential way to improve o.o.d. generalization is to assume simple solutions are unlikely to be valid across contexts and downweight them, which we refer to as the too-good-to-be-true prior. We implement this inductive bias in a two-stage approach that uses predictions from a low-capacity network (LCN) to inform the training of a high-capacity network (HCN). Since the shallow architecture of the LCN can only learn surface relationships, which includes shortcuts, we downweight training items for the HCN that the LCN can master, thereby encouraging the HCN to rely on deeper invariant features that should generalize broadly. Using a modified version of the CIFAR-10 dataset in which we introduced shortcuts, we found that the two-stage LCN-HCN approach reduced reliance on shortcuts and facilitated o.o.d. generalization.