 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Too-Good-to-be-True Prior to Reduce Shortcut Reliance
Feb 12, 2021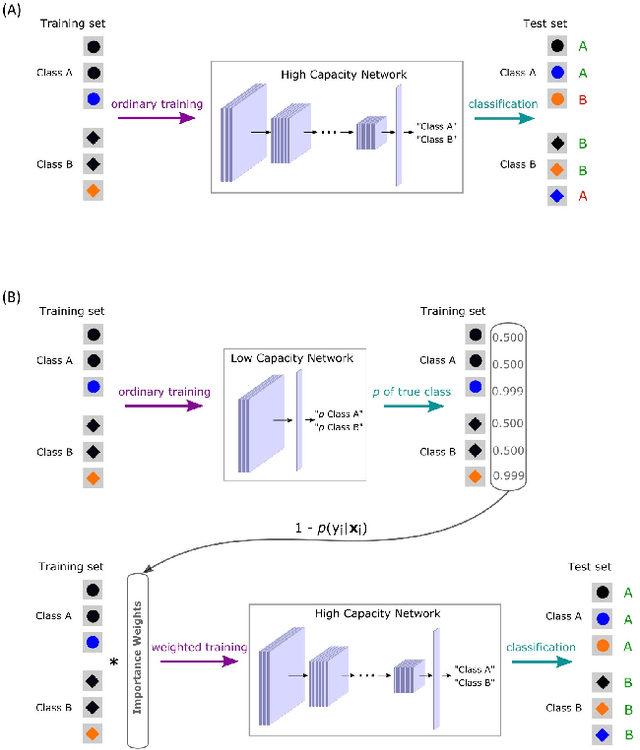


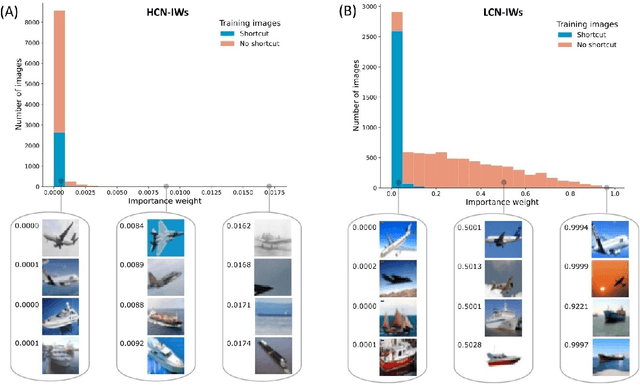
Despite their impressive performance in object recognition and other tasks under standard testing conditions, deep convolutional neural networks (DCNNs) often fail to generalize to out-of-distribution (o.o.d.) samples. One cause for this shortcoming is that modern architectures tend to rely on "shortcuts" - superficial features that correlate with categories without capturing deeper invariants that hold across contexts. Real-world concepts often possess a complex structure that can vary superficially across contexts, which can make the most intuitive and promising solutions in one context not generalize to others. One potential way to improve o.o.d. generalization is to assume simple solutions are unlikely to be valid across contexts and downweight them, which we refer to as the too-good-to-be-true prior. We implement this inductive bias in a two-stage approach that uses predictions from a low-capacity network (LCN) to inform the training of a high-capacity network (HCN). Since the shallow architecture of the LCN can only learn surface relationships, which includes shortcuts, we downweight training items for the HCN that the LCN can master, thereby encouraging the HCN to rely on deeper invariant features that should generalize broadly. Using a modified version of the CIFAR-10 dataset in which we introduced shortcuts, we found that the two-stage LCN-HCN approach reduced reliance on shortcuts and facilitated o.o.d. generalization.