 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRationale-Grounded In-Context Learning for Time Series Reasoning with Multimodal Large Language Models
Jan 06, 2026The underperformance of existing multimodal large language models for time series reasoning lies in the absence of rationale priors that connect temporal observations to their downstream outcomes, which leads models to rely on superficial pattern matching rather than principled reasoning. We therefore propose the rationale-grounded in-context learning for time series reasoning, where rationales work as guiding reasoning units rather than post-hoc explanations, and develop the RationaleTS method. Specifically, we firstly induce label-conditioned rationales, composed of reasoning paths from observable evidence to the potential outcomes. Then, we design the hybrid retrieval by balancing temporal patterns and semantic contexts to retrieve correlated rationale priors for the final in-context inference on new samples. We conduct extensive experiments to demonstrate the effectiveness and efficiency of our proposed RationaleTS on three-domain time series reasoning tasks. We will release our code for reproduction.
Probability Consistency in Large Language Models: Theoretical Foundations Meet Empirical Discrepancies
May 13, 2025
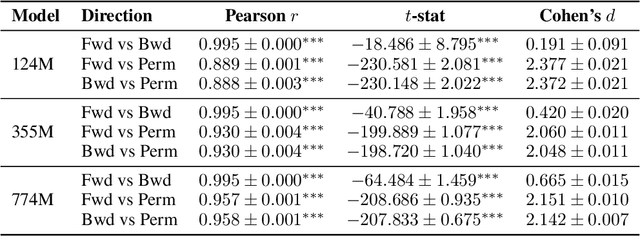


Can autoregressive large language models (LLMs) learn consistent probability distributions when trained on sequences in different token orders? We prove formally that for any well-defined probability distribution, sequence perplexity is invariant under any factorization, including forward, backward, or arbitrary permutations. This result establishes a rigorous theoretical foundation for studying how LLMs learn from data and defines principled protocols for empirical evaluation. Applying these protocols, we show that prior studies examining ordering effects suffer from critical methodological flaws. We retrain GPT-2 models across forward, backward, and arbitrary permuted orders on scientific text. We find systematic deviations from theoretical invariance across all orderings with arbitrary permutations strongly deviating from both forward and backward models, which largely (but not completely) agreed with one another. Deviations were traceable to differences in self-attention, reflecting positional and locality biases in processing. Our theoretical and empirical results provide novel avenues for understanding positional biases in LLMs and suggest methods for detecting when LLMs' probability distributions are inconsistent and therefore untrustworthy.
Beyond Human-Like Processing: Large Language Models Perform Equivalently on Forward and Backward Scientific Text
Nov 17, 2024

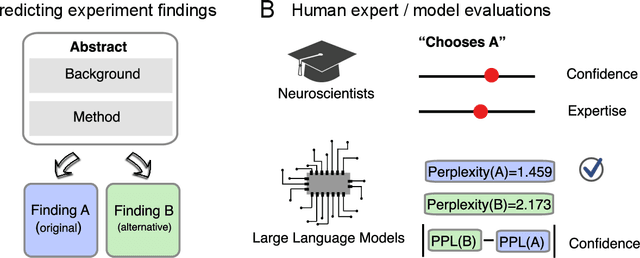
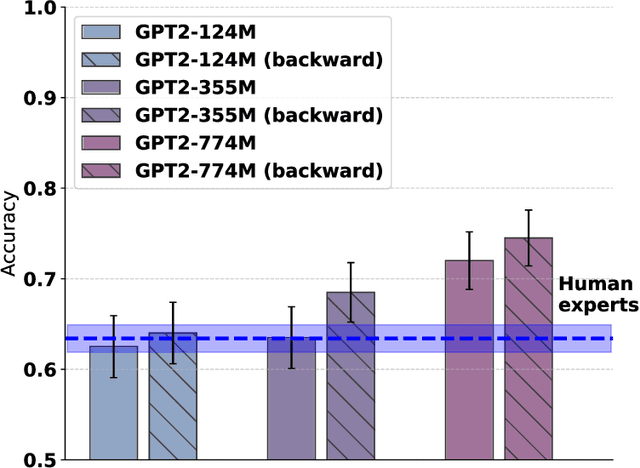
The impressive performance of large language models (LLMs) has led to their consideration as models of human language processing. Instead, we suggest that the success of LLMs arises from the flexibility of the transformer learning architecture. To evaluate this conjecture, we trained LLMs on scientific texts that were either in a forward or backward format. Despite backward text being inconsistent with the structure of human languages, we found that LLMs performed equally well in either format on a neuroscience benchmark, eclipsing human expert performance for both forward and backward orders. Our results are consistent with the success of transformers across diverse domains, such as weather prediction and protein design. This widespread success is attributable to LLM's ability to extract predictive patterns from any sufficiently structured input. Given their generality, we suggest caution in interpreting LLM's success in linguistic tasks as evidence for human-like mechanisms.
Confidence-weighted integration of human and machine judgments for superior decision-making
Aug 15, 2024
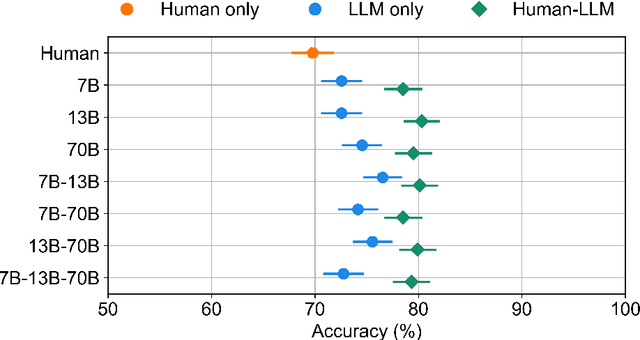
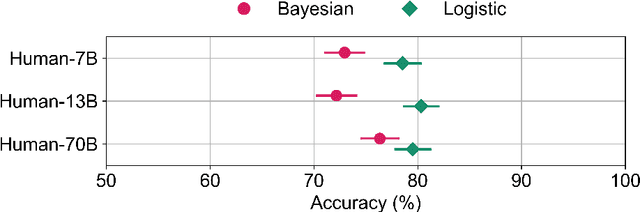
Large language models (LLMs) have emerged as powerful tools in various domains. Recent studies have shown that LLMs can surpass humans in certain tasks, such as predicting the outcomes of neuroscience studies. What role does this leave for humans in the overall decision process? One possibility is that humans, despite performing worse than LLMs, can still add value when teamed with them. A human and machine team can surpass each individual teammate when team members' confidence is well-calibrated and team members diverge in which tasks they find difficult (i.e., calibration and diversity are needed). We simplified and extended a Bayesian approach to combining judgments using a logistic regression framework that integrates confidence-weighted judgments for any number of team members. Using this straightforward method, we demonstrated in a neuroscience forecasting task that, even when humans were inferior to LLMs, their combination with one or more LLMs consistently improved team performance. Our hope is that this simple and effective strategy for integrating the judgments of humans and machines will lead to productive collaborations.
Matching domain experts by training from scratch on domain knowledge
May 15, 2024



Recently, large language models (LLMs) have outperformed human experts in predicting the results of neuroscience experiments (Luo et al., 2024). What is the basis for this performance? One possibility is that statistical patterns in that specific scientific literature, as opposed to emergent reasoning abilities arising from broader training, underlie LLMs' performance. To evaluate this possibility, we trained (next word prediction) a relatively small 124M-parameter GPT-2 model on 1.3 billion tokens of domain-specific knowledge. Despite being orders of magnitude smaller than larger LLMs trained on trillions of tokens, small models achieved expert-level performance in predicting neuroscience results. Small models trained on the neuroscience literature succeeded when they were trained from scratch using a tokenizer specifically trained on neuroscience text or when the neuroscience literature was used to finetune a pretrained GPT-2. Our results indicate that expert-level performance may be attained by even small LLMs through domain-specific, auto-regressive training approaches.
Large language models surpass human experts in predicting neuroscience results
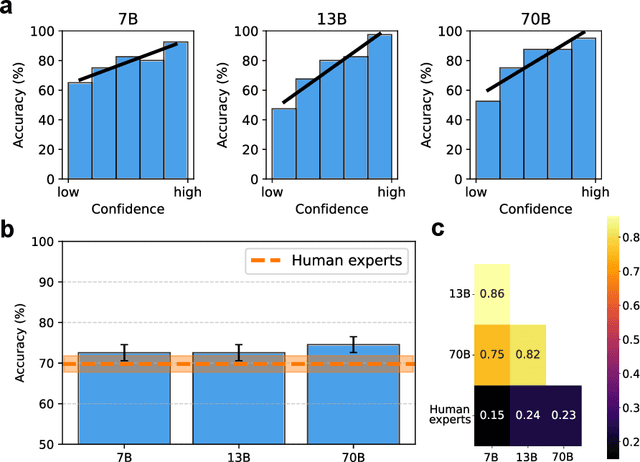
Mar 14, 2024Scientific discoveries often hinge on synthesizing decades of research, a task that potentially outstrips human information processing capacities. Large language models (LLMs) offer a solution. LLMs trained on the vast scientific literature could potentially integrate noisy yet interrelated findings to forecast novel results better than human experts. To evaluate this possibility, we created BrainBench, a forward-looking benchmark for predicting neuroscience results. We find that LLMs surpass experts in predicting experimental outcomes. BrainGPT, an LLM we tuned on the neuroscience literature, performed better yet. Like human experts, when LLMs were confident in their predictions, they were more likely to be correct, which presages a future where humans and LLMs team together to make discoveries. Our approach is not neuroscience-specific and is transferable to other knowledge-intensive endeavors.
Understanding top-down attention using task-oriented ablation design
Jun 08, 2021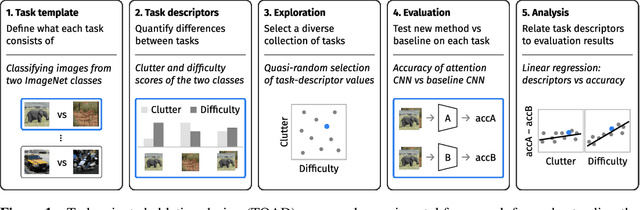
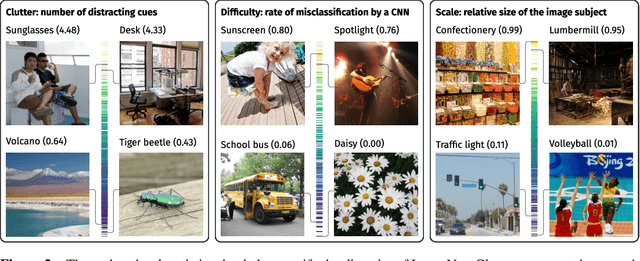
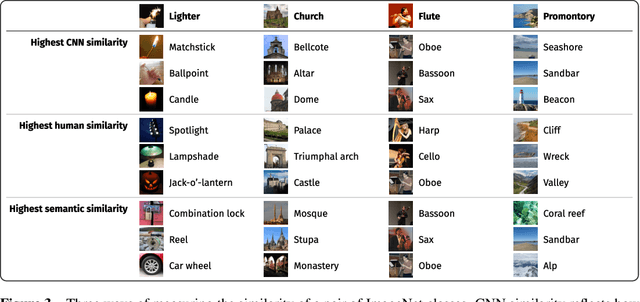
Top-down attention allows neural networks, both artificial and biological, to focus on the information most relevant for a given task. This is known to enhance performance in visual perception. But it remains unclear how attention brings about its perceptual boost, especially when it comes to naturalistic settings like recognising an object in an everyday scene. What aspects of a visual task does attention help to deal with? We aim to answer this with a computational experiment based on a general framework called task-oriented ablation design. First we define a broad range of visual tasks and identify six factors that underlie task variability. Then on each task we compare the performance of two neural networks, one with top-down attention and one without. These comparisons reveal the task-dependence of attention's perceptual boost, giving a clearer idea of the role attention plays. Whereas many existing cognitive accounts link attention to stimulus-level variables, such as visual clutter and object scale, we find greater explanatory power in system-level variables that capture the interaction between the model, the distribution of training data and the task format. This finding suggests a shift in how attention is studied could be fruitful. We make publicly available our code and results, along with statistics relevant to ImageNet-based experiments beyond this one. Our contribution serves to support the development of more human-like vision models and the design of more informative machine-learning experiments.
A Too-Good-to-be-True Prior to Reduce Shortcut Reliance
Feb 12, 2021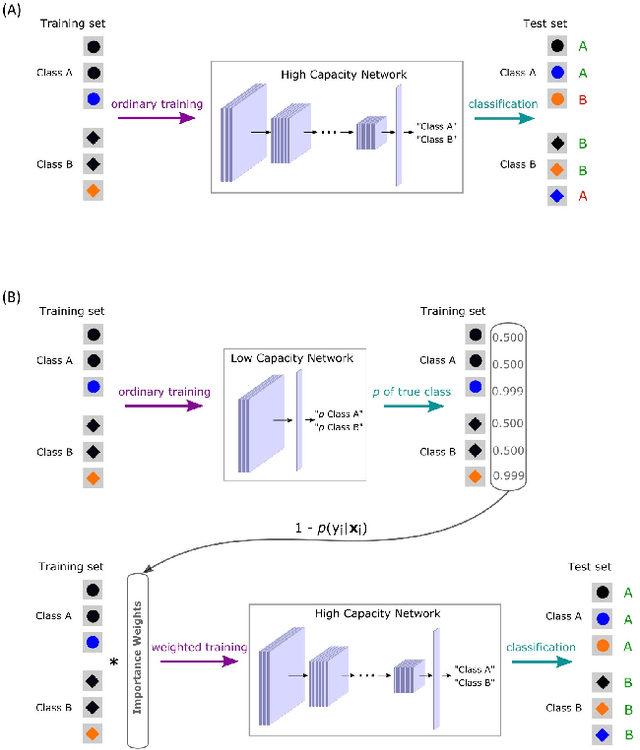


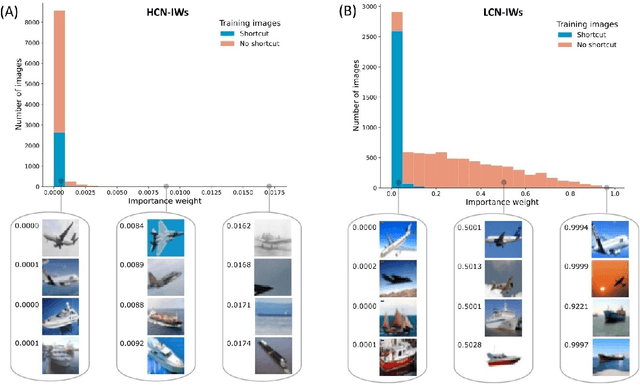
Despite their impressive performance in object recognition and other tasks under standard testing conditions, deep convolutional neural networks (DCNNs) often fail to generalize to out-of-distribution (o.o.d.) samples. One cause for this shortcoming is that modern architectures tend to rely on "shortcuts" - superficial features that correlate with categories without capturing deeper invariants that hold across contexts. Real-world concepts often possess a complex structure that can vary superficially across contexts, which can make the most intuitive and promising solutions in one context not generalize to others. One potential way to improve o.o.d. generalization is to assume simple solutions are unlikely to be valid across contexts and downweight them, which we refer to as the too-good-to-be-true prior. We implement this inductive bias in a two-stage approach that uses predictions from a low-capacity network (LCN) to inform the training of a high-capacity network (HCN). Since the shallow architecture of the LCN can only learn surface relationships, which includes shortcuts, we downweight training items for the HCN that the LCN can master, thereby encouraging the HCN to rely on deeper invariant features that should generalize broadly. Using a modified version of the CIFAR-10 dataset in which we introduced shortcuts, we found that the two-stage LCN-HCN approach reduced reliance on shortcuts and facilitated o.o.d. generalization.
The perceptual boost of visual attention is task-dependent in naturalistic settings
Feb 22, 2020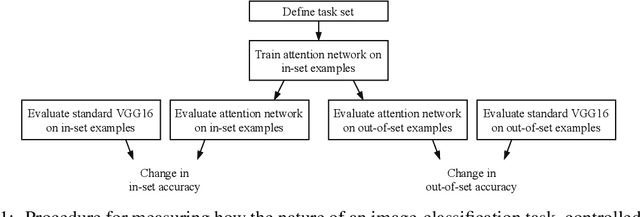
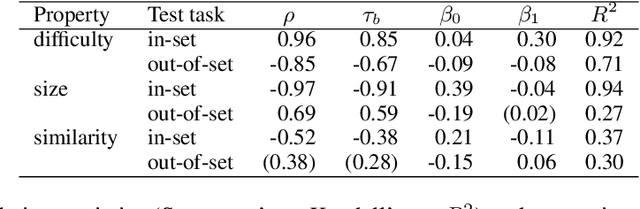
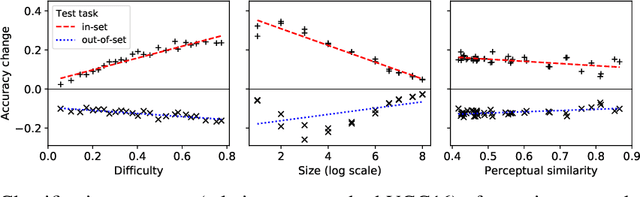
Attentional modulation of neural representations is known to enhance processing of task-relevant visual information. Is the resulting perceptual boost task-dependent in naturalistic settings? We aim to answer this with a large-scale computational experiment. First we design a series of visual tasks, each consisting of classifying images from a particular task set (group of image categories). The nature of a given task is determined by which categories are included in the task set. Then on each task we compare the accuracy of an attention-augmented neural network to that of an attention-free counterpart. We show that, all else being equal, the performance impact of attention is stronger with increasing task-set difficulty, weaker with increasing task-set size, and weaker with increasing perceptual similarity within a task set.
The Costs and Benefits of Goal-Directed Attention in Deep Convolutional Neural Networks
Feb 06, 2020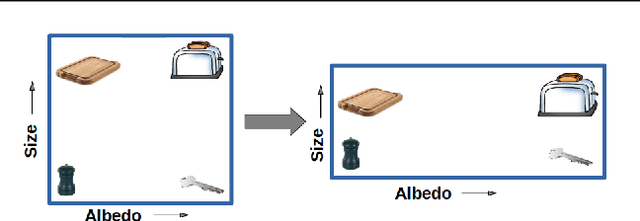


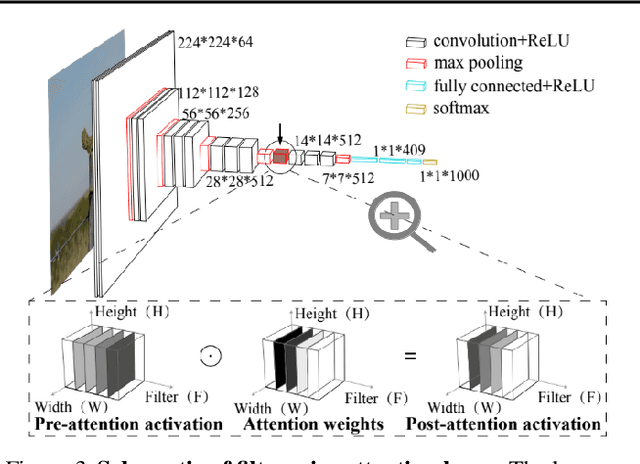
Attention in machine learning is largely bottom-up, whereas people also deploy top-down, goal-directed attention. Motivated by neuroscience research, we evaluated a plug-and-play, top-down attention layer that is easily added to existing deep convolutional neural networks (DCNNs). In object recognition tasks, increasing top-down attention has benefits (increasing hit rates) and costs (increasing false alarm rates). At a moderate level, attention improves sensitivity (i.e., increases $d^\prime$) at only a moderate increase in bias for tasks involving standard images, blended images, and natural adversarial images. These theoretical results suggest that top-down attention can effectively reconfigure general-purpose DCNNs to better suit the current task goal. We hope our results continue the fruitful dialog between neuroscience and machine learning.