 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion-wise stacking ensembles for estimating brain-age using MRI
Jan 17, 2025



Predictive modeling using structural magnetic resonance imaging (MRI) data is a prominent approach to study brain-aging. Machine learning algorithms and feature extraction methods have been employed to improve predictions and explore healthy and accelerated aging e.g. neurodegenerative and psychiatric disorders. The high-dimensional MRI data pose challenges to building generalizable and interpretable models as well as for data privacy. Common practices are resampling or averaging voxels within predefined parcels, which reduces anatomical specificity and biological interpretability as voxels within a region may differently relate to aging. Effectively, naive fusion by averaging can result in information loss and reduced accuracy. We present a conceptually novel two-level stacking ensemble (SE) approach. The first level comprises regional models for predicting individuals' age based on voxel-wise information, fused by a second-level model yielding final predictions. Eight data fusion scenarios were explored using as input Gray matter volume (GMV) estimates from four datasets covering the adult lifespan. Performance, measured using mean absolute error (MAE), R2, correlation and prediction bias, showed that SE outperformed the region-wise averages. The best performance was obtained when first-level regional predictions were obtained as out-of-sample predictions on the application site with second-level models trained on independent and site-specific data (MAE=4.75 vs baseline regional mean GMV MAE=5.68). Performance improved as more datasets were used for training. First-level predictions showed improved and more robust aging signal providing new biological insights and enhanced data privacy. Overall, the SE improves accuracy compared to the baseline while preserving or enhancing data privacy.
The impact of MRI image quality on statistical and predictive analysis on voxel based morphology
Nov 02, 2024


Image Quality of MRI brain scans is strongly influenced by within scanner head movements and the resulting image artifacts alter derived measures like brain volume and cortical thickness. Automated image quality assessment is key to controlling for confounding effects of poor image quality. In this study, we systematically test for the influence of image quality on univariate statistics and machine learning classification. We analyzed group effects of sex/gender on local brain volume and made predictions of sex/gender using logistic regression, while correcting for brain size. From three large publicly available datasets, two age and sex-balanced samples were derived to test the generalizability of the effect for pooled sample sizes of n=760 and n=1094. Results of the Bonferroni corrected t-tests over 3747 gray matter features showed a strong influence of low-quality data on the ability to find significant sex/gender differences for the smaller sample. Increasing sample size and more so image quality showed a stark increase in detecting significant effects in univariate group comparisons. For the classification of sex/gender using logistic regression, both increasing sample size and image quality had a marginal effect on the Area under the Receiver Operating Characteristic Curve for most datasets and subsamples. Our results suggest a more stringent quality control for univariate approaches than for multivariate classification with a leaning towards higher quality for classical group statistics and bigger sample sizes for machine learning applications in neuroimaging.
Impact of Leakage on Data Harmonization in Machine Learning Pipelines in Class Imbalance Across Sites
Oct 25, 2024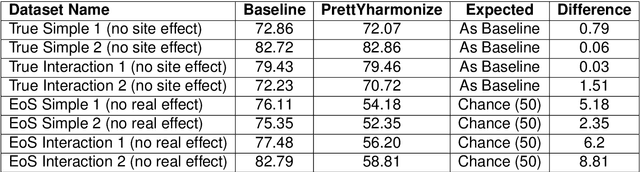
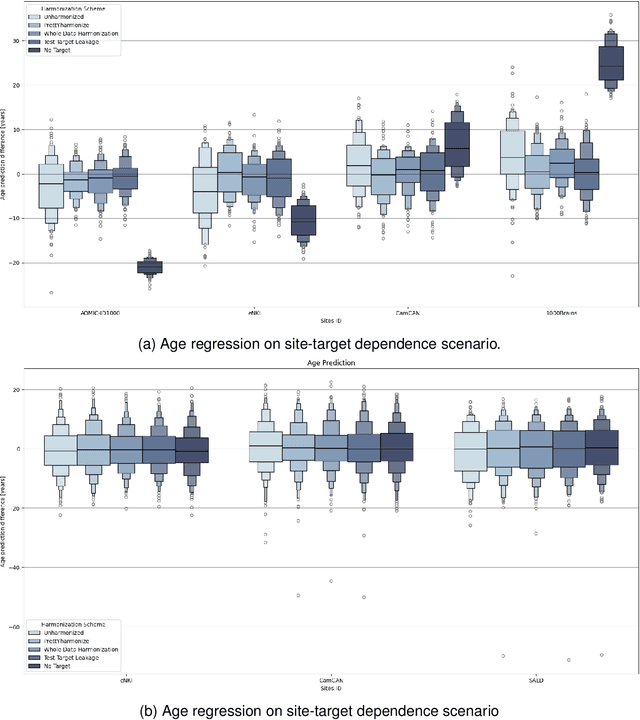
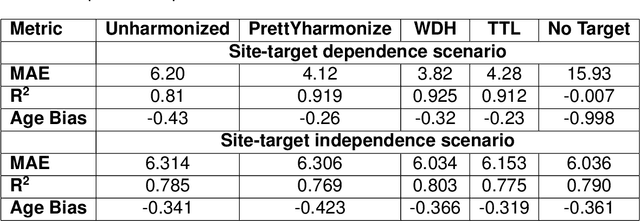
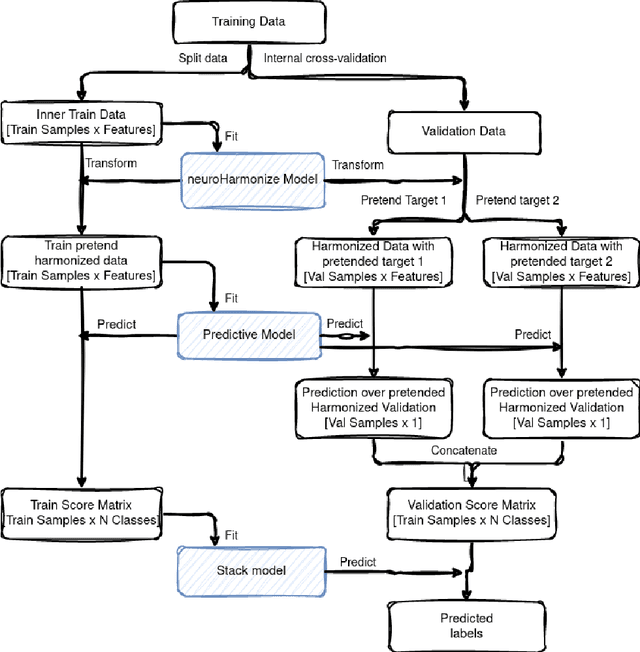
Machine learning (ML) models benefit from large datasets. Collecting data in biomedical domains is costly and challenging, hence, combining datasets has become a common practice. However, datasets obtained under different conditions could present undesired site-specific variability. Data harmonization methods aim to remove site-specific variance while retaining biologically relevant information. This study evaluates the effectiveness of popularly used ComBat-based methods for harmonizing data in scenarios where the class balance is not equal across sites. We find that these methods struggle with data leakage issues. To overcome this problem, we propose a novel approach PrettYharmonize, designed to harmonize data by pretending the target labels. We validate our approach using controlled datasets designed to benchmark the utility of harmonization. Finally, using real-world MRI and clinical data, we compare leakage-prone methods with PrettYharmonize and show that it achieves comparable performance while avoiding data leakage, particularly in site-target-dependence scenarios.
Large language models surpass human experts in predicting neuroscience results
Mar 14, 2024Scientific discoveries often hinge on synthesizing decades of research, a task that potentially outstrips human information processing capacities. Large language models (LLMs) offer a solution. LLMs trained on the vast scientific literature could potentially integrate noisy yet interrelated findings to forecast novel results better than human experts. To evaluate this possibility, we created BrainBench, a forward-looking benchmark for predicting neuroscience results. We find that LLMs surpass experts in predicting experimental outcomes. BrainGPT, an LLM we tuned on the neuroscience literature, performed better yet. Like human experts, when LLMs were confident in their predictions, they were more likely to be correct, which presages a future where humans and LLMs team together to make discoveries. Our approach is not neuroscience-specific and is transferable to other knowledge-intensive endeavors.
Empirical Comparison between Cross-Validation and Mutation-Validation in Model Selection
Nov 23, 2023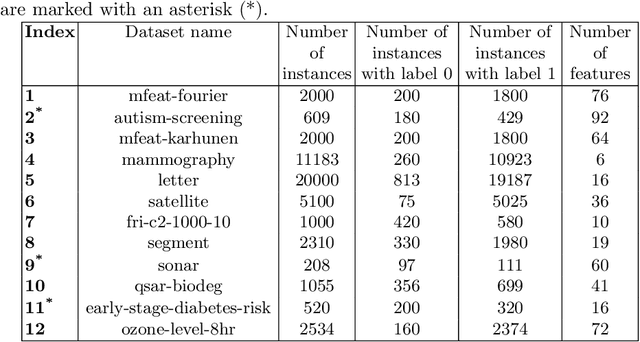
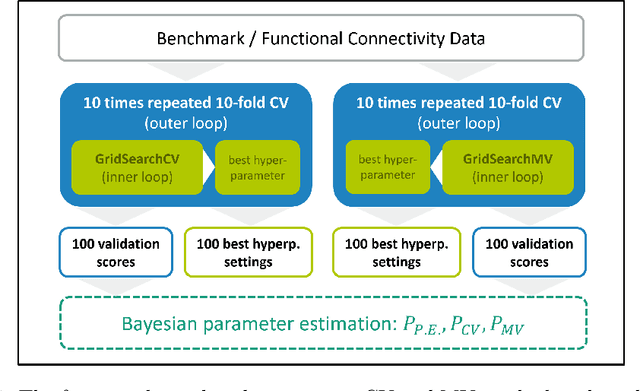
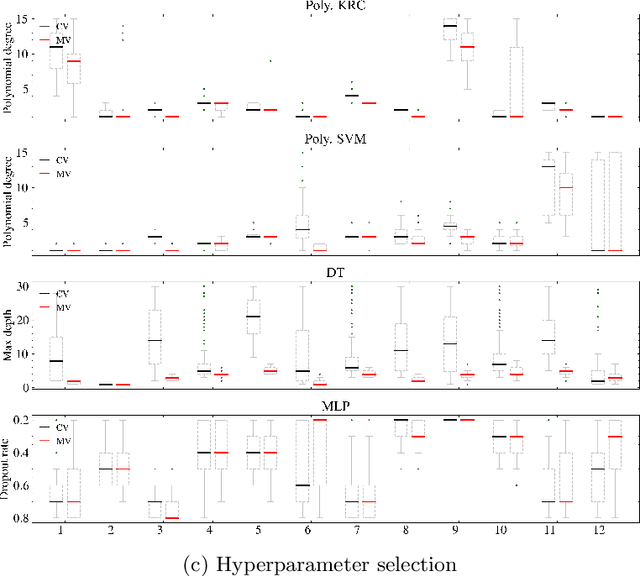
Mutation validation (MV) is a recently proposed approach for model selection, garnering significant interest due to its unique characteristics and potential benefits compared to the widely used cross-validation (CV) method. In this study, we empirically compared MV and $k$-fold CV using benchmark and real-world datasets. By employing Bayesian tests, we compared generalization estimates yielding three posterior probabilities: practical equivalence, CV superiority, and MV superiority. We also evaluated the differences in the capacity of the selected models and computational efficiency. We found that both MV and CV select models with practically equivalent generalization performance across various machine learning algorithms and the majority of benchmark datasets. MV exhibited advantages in terms of selecting simpler models and lower computational costs. However, in some cases MV selected overly simplistic models leading to underfitting and showed instability in hyperparameter selection. These limitations of MV became more evident in the evaluation of a real-world neuroscientific task of predicting sex at birth using brain functional connectivity.
On Leakage in Machine Learning Pipelines
Nov 07, 2023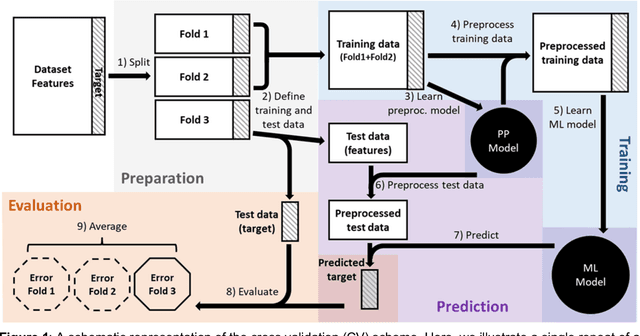
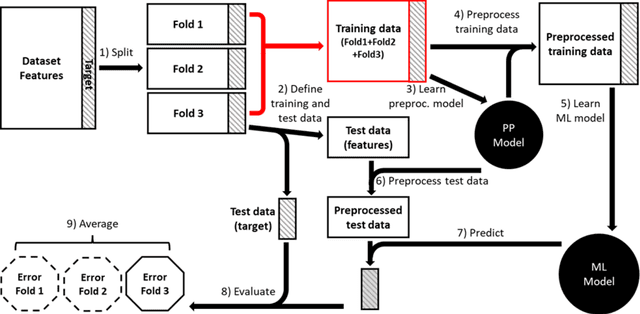
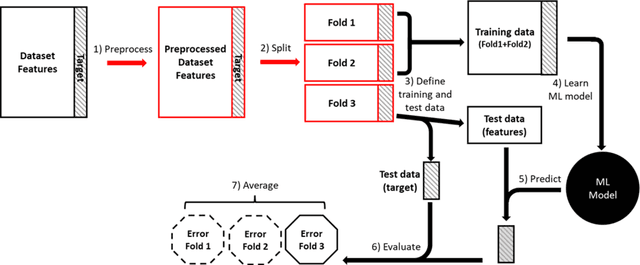
Machine learning (ML) provides powerful tools for predictive modeling. ML's popularity stems from the promise of sample-level prediction with applications across a variety of fields from physics and marketing to healthcare. However, if not properly implemented and evaluated, ML pipelines may contain leakage typically resulting in overoptimistic performance estimates and failure to generalize to new data. This can have severe negative financial and societal implications. Our aim is to expand understanding associated with causes leading to leakage when designing, implementing, and evaluating ML pipelines. Illustrated by concrete examples, we provide a comprehensive overview and discussion of various types of leakage that may arise in ML pipelines.
Julearn: an easy-to-use library for leakage-free evaluation and inspection of ML models
Oct 19, 2023The fast-paced development of machine learning (ML) methods coupled with its increasing adoption in research poses challenges for researchers without extensive training in ML. In neuroscience, for example, ML can help understand brain-behavior relationships, diagnose diseases, and develop biomarkers using various data sources like magnetic resonance imaging and electroencephalography. The primary objective of ML is to build models that can make accurate predictions on unseen data. Researchers aim to prove the existence of such generalizable models by evaluating performance using techniques such as cross-validation (CV), which uses systematic subsampling to estimate the generalization performance. Choosing a CV scheme and evaluating an ML pipeline can be challenging and, if used improperly, can lead to overestimated results and incorrect interpretations. We created julearn, an open-source Python library, that allow researchers to design and evaluate complex ML pipelines without encountering in common pitfalls. In this manuscript, we present the rationale behind julearn's design, its core features, and showcase three examples of previously-published research projects that can be easily implemented using this novel library. Julearn aims to simplify the entry into the ML world by providing an easy-to-use environment with built in guards against some of the most common ML pitfalls. With its design, unique features and simple interface, it poses as a useful Python-based library for research projects.
Confound-leakage: Confound Removal in Machine Learning Leads to Leakage
Oct 17, 2022Machine learning (ML) approaches to data analysis are now widely adopted in many fields including epidemiology and medicine. To apply these approaches, confounds must first be removed as is commonly done by featurewise removal of their variance by linear regression before applying ML. Here, we show this common approach to confound removal biases ML models, leading to misleading results. Specifically, this common deconfounding approach can leak information such that what are null or moderate effects become amplified to near-perfect prediction when nonlinear ML approaches are subsequently applied. We identify and evaluate possible mechanisms for such confound-leakage and provide practical guidance to mitigate its negative impact. We demonstrate the real-world importance of confound-leakage by analyzing a clinical dataset where accuracy is overestimated for predicting attention deficit hyperactivity disorder (ADHD) with depression as a confound. Our results have wide-reaching implications for implementation and deployment of ML workflows and beg caution against na\"ive use of standard confound removal approaches.
Predictive Data Calibration for Linear Correlation Significance Testing
Aug 15, 2022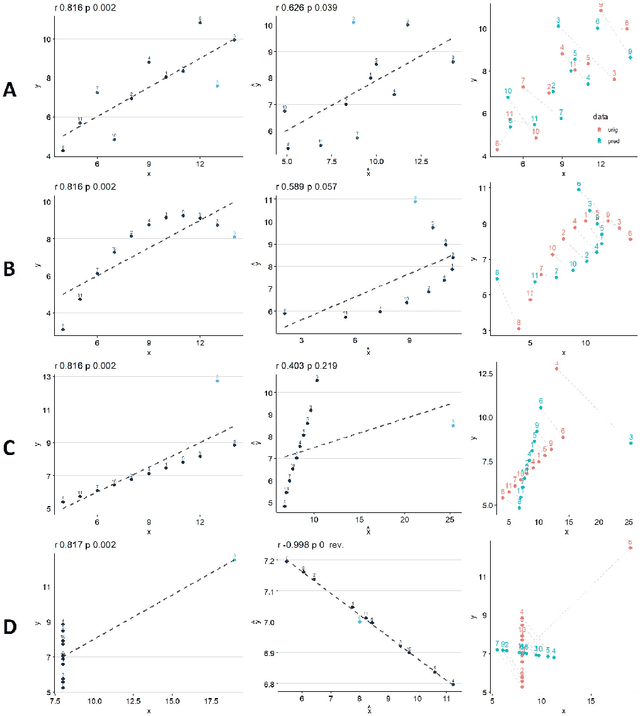
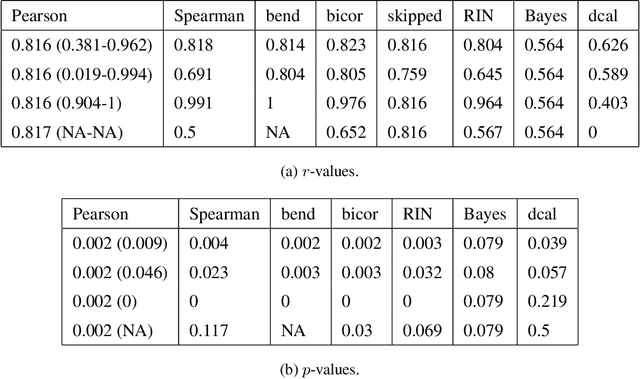
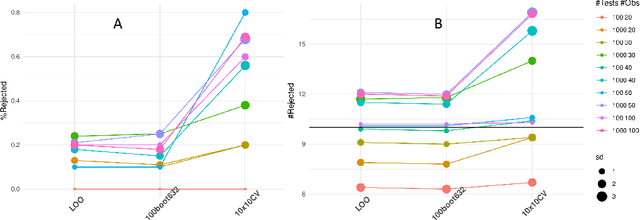
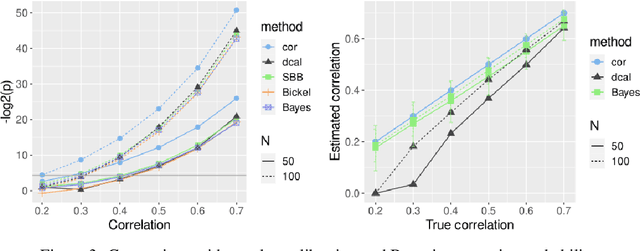
Inferring linear relationships lies at the heart of many empirical investigations. A measure of linear dependence should correctly evaluate the strength of the relationship as well as qualify whether it is meaningful for the population. Pearson's correlation coefficient (PCC), the \textit{de-facto} measure for bivariate relationships, is known to lack in both regards. The estimated strength $r$ maybe wrong due to limited sample size, and nonnormality of data. In the context of statistical significance testing, erroneous interpretation of a $p$-value as posterior probability leads to Type I errors -- a general issue with significance testing that extends to PCC. Such errors are exacerbated when testing multiple hypotheses simultaneously. To tackle these issues, we propose a machine-learning-based predictive data calibration method which essentially conditions the data samples on the expected linear relationship. Calculating PCC using calibrated data yields a calibrated $p$-value that can be interpreted as posterior probability together with a calibrated $r$ estimate, a desired outcome not provided by other methods. Furthermore, the ensuing independent interpretation of each test might eliminate the need for multiple testing correction. We provide empirical evidence favouring the proposed method using several simulations and application to real-world data.
A Too-Good-to-be-True Prior to Reduce Shortcut Reliance
Feb 12, 2021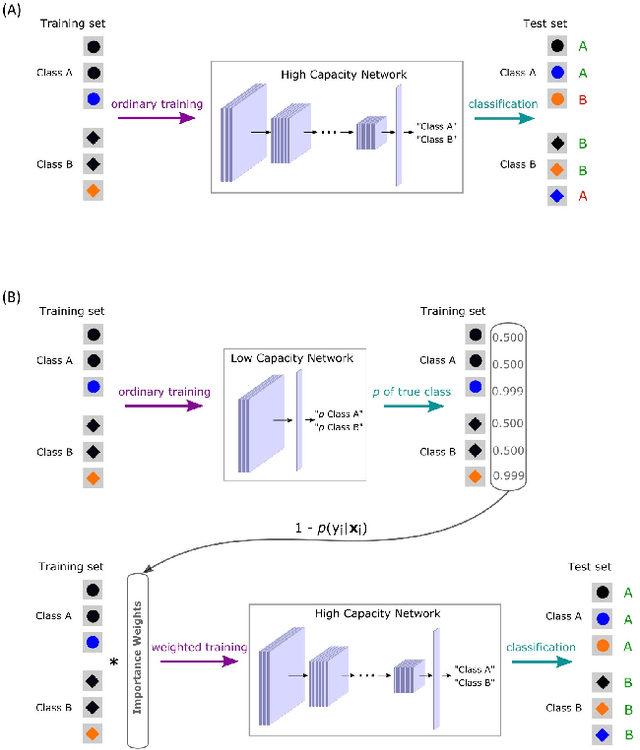


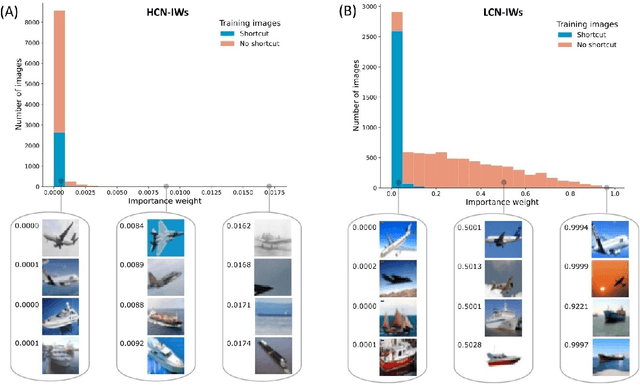
Despite their impressive performance in object recognition and other tasks under standard testing conditions, deep convolutional neural networks (DCNNs) often fail to generalize to out-of-distribution (o.o.d.) samples. One cause for this shortcoming is that modern architectures tend to rely on "shortcuts" - superficial features that correlate with categories without capturing deeper invariants that hold across contexts. Real-world concepts often possess a complex structure that can vary superficially across contexts, which can make the most intuitive and promising solutions in one context not generalize to others. One potential way to improve o.o.d. generalization is to assume simple solutions are unlikely to be valid across contexts and downweight them, which we refer to as the too-good-to-be-true prior. We implement this inductive bias in a two-stage approach that uses predictions from a low-capacity network (LCN) to inform the training of a high-capacity network (HCN). Since the shallow architecture of the LCN can only learn surface relationships, which includes shortcuts, we downweight training items for the HCN that the LCN can master, thereby encouraging the HCN to rely on deeper invariant features that should generalize broadly. Using a modified version of the CIFAR-10 dataset in which we introduced shortcuts, we found that the two-stage LCN-HCN approach reduced reliance on shortcuts and facilitated o.o.d. generalization.