 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe impact of MRI image quality on statistical and predictive analysis on voxel based morphology
Nov 02, 2024


Image Quality of MRI brain scans is strongly influenced by within scanner head movements and the resulting image artifacts alter derived measures like brain volume and cortical thickness. Automated image quality assessment is key to controlling for confounding effects of poor image quality. In this study, we systematically test for the influence of image quality on univariate statistics and machine learning classification. We analyzed group effects of sex/gender on local brain volume and made predictions of sex/gender using logistic regression, while correcting for brain size. From three large publicly available datasets, two age and sex-balanced samples were derived to test the generalizability of the effect for pooled sample sizes of n=760 and n=1094. Results of the Bonferroni corrected t-tests over 3747 gray matter features showed a strong influence of low-quality data on the ability to find significant sex/gender differences for the smaller sample. Increasing sample size and more so image quality showed a stark increase in detecting significant effects in univariate group comparisons. For the classification of sex/gender using logistic regression, both increasing sample size and image quality had a marginal effect on the Area under the Receiver Operating Characteristic Curve for most datasets and subsamples. Our results suggest a more stringent quality control for univariate approaches than for multivariate classification with a leaning towards higher quality for classical group statistics and bigger sample sizes for machine learning applications in neuroimaging.
Impact of Leakage on Data Harmonization in Machine Learning Pipelines in Class Imbalance Across Sites
Oct 25, 2024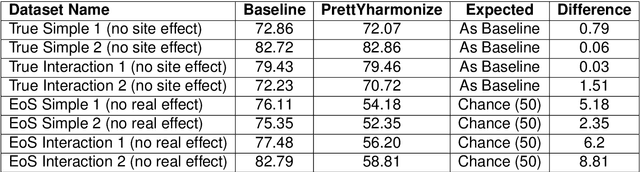
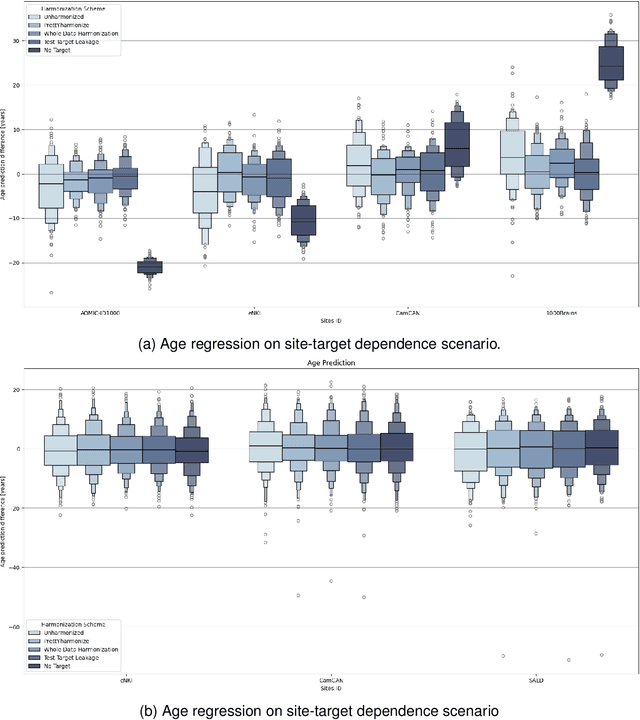
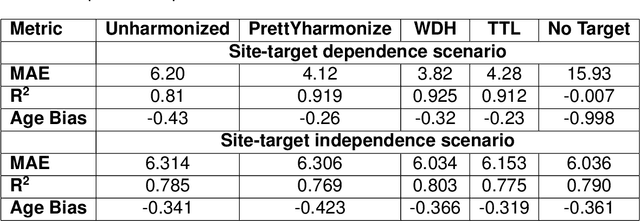
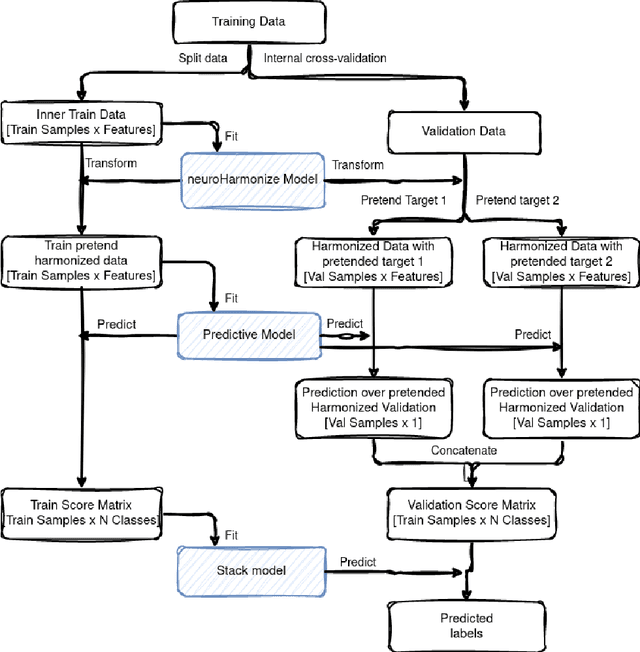
Machine learning (ML) models benefit from large datasets. Collecting data in biomedical domains is costly and challenging, hence, combining datasets has become a common practice. However, datasets obtained under different conditions could present undesired site-specific variability. Data harmonization methods aim to remove site-specific variance while retaining biologically relevant information. This study evaluates the effectiveness of popularly used ComBat-based methods for harmonizing data in scenarios where the class balance is not equal across sites. We find that these methods struggle with data leakage issues. To overcome this problem, we propose a novel approach PrettYharmonize, designed to harmonize data by pretending the target labels. We validate our approach using controlled datasets designed to benchmark the utility of harmonization. Finally, using real-world MRI and clinical data, we compare leakage-prone methods with PrettYharmonize and show that it achieves comparable performance while avoiding data leakage, particularly in site-target-dependence scenarios.
Extreme Learning Machine design for dealing with unrepresentative features
Dec 04, 2019



Extreme Learning Machines (ELMs) have become a popular tool in the field of Artificial Intelligence due to their very high training speed and generalization capabilities. Another advantage is that they have a single hyper-parameter that must be tuned up: the number of hidden nodes. Most traditional approaches dictate that this parameter should be chosen smaller than the number of available training samples in order to avoid over-fitting. In fact, it has been proved that choosing the number of hidden nodes equal to the number of training samples yields a perfect training classification with probability 1 (w.r.t. the random parameter initialization). In this article we argue that in spite of this, in some cases it may be beneficial to choose a much larger number of hidden nodes, depending on certain properties of the data. We explain why this happens and show some examples to illustrate how the model behaves. In addition, we present a pruning algorithm to cope with the additional computational burden associated to the enlarged ELM. Experimental results using electroencephalography (EEG) signals show an improvement in performance with respect to traditional ELM approaches, while diminishing the extra computing time associated to the use of large architectures.