 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Sensitivity Improves Human-Machine Visual Alignment
Apr 15, 2026Modern machine learning models typically represent inputs as fixed points in a high-dimensional embedding space. While this approach has been proven powerful for a wide range of downstream tasks, it fundamentally differs from the way humans process information. Because humans are constantly adapting to their environment, they represent objects and their relationships in a highly context-sensitive manner. To address this gap, we propose a method for context-sensitive similarity computation from neural network embeddings, applied to modeling a triplet odd-one-out task with an anchor image serving as simultaneous context. Modeling context enables us to achieve up to a 15% improvement in odd-one-out accuracy over a context-insensitive model. We find that this improvement is consistent across both original and "human-aligned" vision foundation models.
EgoToM: Benchmarking Theory of Mind Reasoning from Egocentric Videos
Mar 28, 2025

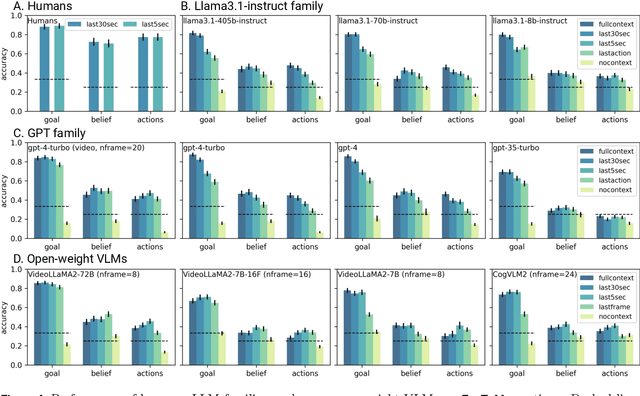

We introduce EgoToM, a new video question-answering benchmark that extends Theory-of-Mind (ToM) evaluation to egocentric domains. Using a causal ToM model, we generate multi-choice video QA instances for the Ego4D dataset to benchmark the ability to predict a camera wearer's goals, beliefs, and next actions. We study the performance of both humans and state of the art multimodal large language models (MLLMs) on these three interconnected inference problems. Our evaluation shows that MLLMs achieve close to human-level accuracy on inferring goals from egocentric videos. However, MLLMs (including the largest ones we tested with over 100B parameters) fall short of human performance when inferring the camera wearers' in-the-moment belief states and future actions that are most consistent with the unseen video future. We believe that our results will shape the future design of an important class of egocentric digital assistants which are equipped with a reasonable model of the user's internal mental states.
A Too-Good-to-be-True Prior to Reduce Shortcut Reliance
Feb 12, 2021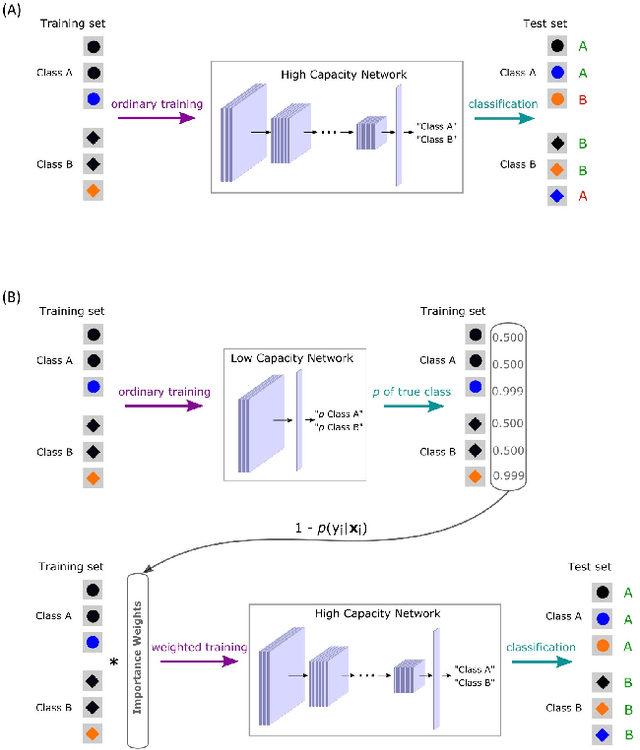


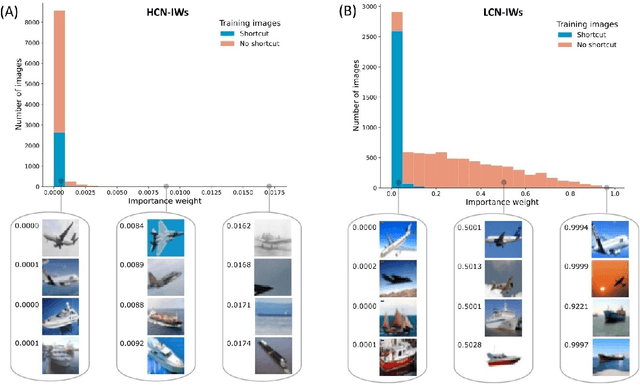
Despite their impressive performance in object recognition and other tasks under standard testing conditions, deep convolutional neural networks (DCNNs) often fail to generalize to out-of-distribution (o.o.d.) samples. One cause for this shortcoming is that modern architectures tend to rely on "shortcuts" - superficial features that correlate with categories without capturing deeper invariants that hold across contexts. Real-world concepts often possess a complex structure that can vary superficially across contexts, which can make the most intuitive and promising solutions in one context not generalize to others. One potential way to improve o.o.d. generalization is to assume simple solutions are unlikely to be valid across contexts and downweight them, which we refer to as the too-good-to-be-true prior. We implement this inductive bias in a two-stage approach that uses predictions from a low-capacity network (LCN) to inform the training of a high-capacity network (HCN). Since the shallow architecture of the LCN can only learn surface relationships, which includes shortcuts, we downweight training items for the HCN that the LCN can master, thereby encouraging the HCN to rely on deeper invariant features that should generalize broadly. Using a modified version of the CIFAR-10 dataset in which we introduced shortcuts, we found that the two-stage LCN-HCN approach reduced reliance on shortcuts and facilitated o.o.d. generalization.
Enriching ImageNet with Human Similarity Judgments and Psychological Embeddings
Nov 22, 2020


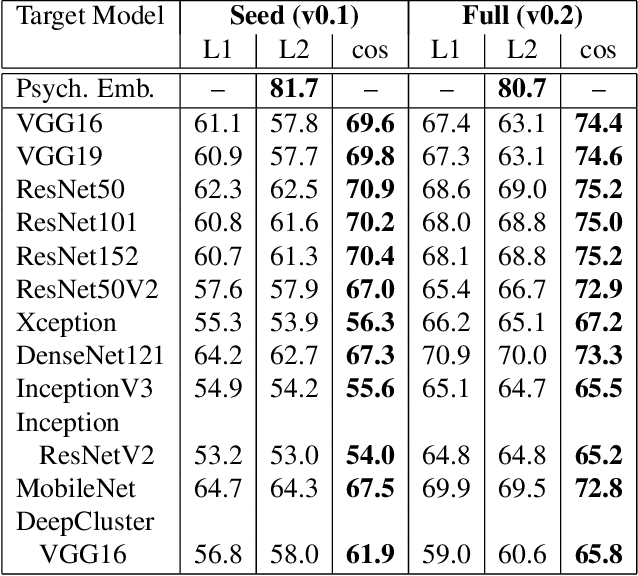
Advances in object recognition flourished in part because of the availability of high-quality datasets and associated benchmarks. However, these benchmarks---such as ILSVRC---are relatively task-specific, focusing predominately on predicting class labels. We introduce a publicly-available dataset that embodies the task-general capabilities of human perception and reasoning. The Human Similarity Judgments extension to ImageNet (ImageNet-HSJ) is composed of human similarity judgments that supplement the ILSVRC validation set. The new dataset supports a range of task and performance metrics, including the evaluation of unsupervised learning algorithms. We demonstrate two methods of assessment: using the similarity judgments directly and using a psychological embedding trained on the similarity judgments. This embedding space contains an order of magnitude more points (i.e., images) than previous efforts based on human judgments. Scaling to the full 50,000 image set was made possible through a selective sampling process that used variational Bayesian inference and model ensembles to sample aspects of the embedding space that were most uncertain. This methodological innovation not only enables scaling, but should also improve the quality of solutions by focusing sampling where it is needed. To demonstrate the utility of ImageNet-HSJ, we used the similarity ratings and the embedding space to evaluate how well several popular models conform to human similarity judgments. One finding is that more complex models that perform better on task-specific benchmarks do not better conform to human semantic judgments. In addition to the human similarity judgments, pre-trained psychological embeddings and code for inferring variational embeddings are made publicly available. Collectively, ImageNet-HSJ assets support the appraisal of internal representations and the development of more human-like models.
Transforming Neural Network Visual Representations to Predict Human Judgments of Similarity
Oct 13, 2020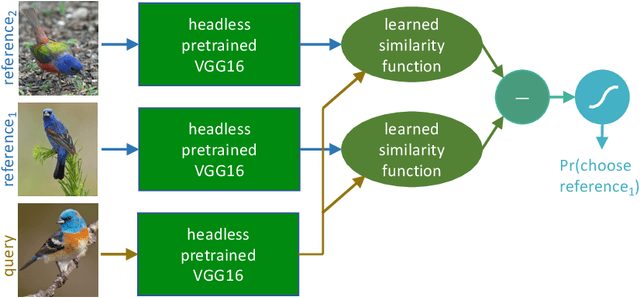
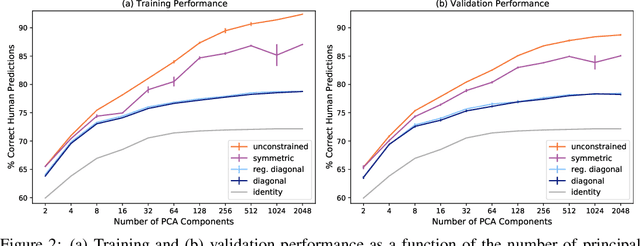
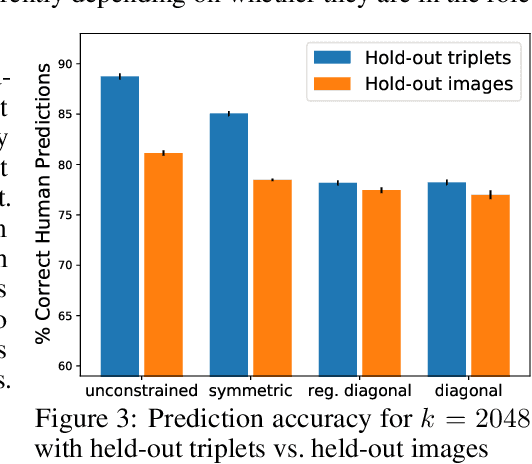
Deep-learning vision models have shown intriguing similarities and differences with respect to human vision. We investigate how to bring machine visual representations into better alignment with human representations. Human representations are often inferred from behavioral evidence such as the selection of an image most similar to a query image. We find that with appropriate linear transformations of deep embeddings, we can improve prediction of human binary choice on a data set of bird images from 72% at baseline to 89%. We hypothesized that deep embeddings have redundant, high (4096) dimensional representations; however, reducing the rank of these representations results in a loss of explanatory power. We hypothesized that the dilation transformation of representations explored in past research is too restrictive, and indeed we found that model explanatory power can be significantly improved with a more expressive linear transform. Most surprising and exciting, we found that, consistent with classic psychological literature, human similarity judgments are asymmetric: the similarity of X to Y is not necessarily equal to the similarity of Y to X, and allowing models to express this asymmetry improves explanatory power.
The perceptual boost of visual attention is task-dependent in naturalistic settings
Feb 22, 2020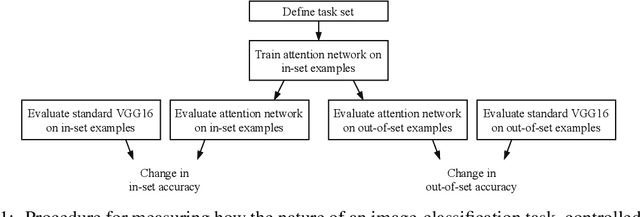
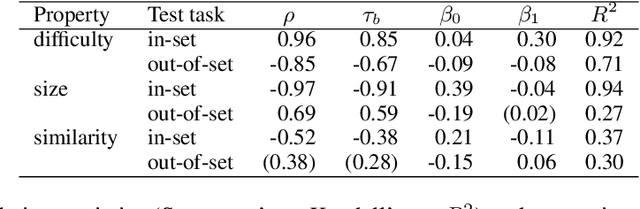
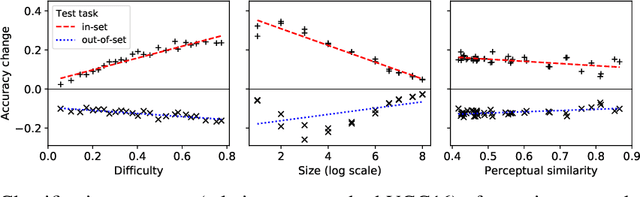
Attentional modulation of neural representations is known to enhance processing of task-relevant visual information. Is the resulting perceptual boost task-dependent in naturalistic settings? We aim to answer this with a large-scale computational experiment. First we design a series of visual tasks, each consisting of classifying images from a particular task set (group of image categories). The nature of a given task is determined by which categories are included in the task set. Then on each task we compare the accuracy of an attention-augmented neural network to that of an attention-free counterpart. We show that, all else being equal, the performance impact of attention is stronger with increasing task-set difficulty, weaker with increasing task-set size, and weaker with increasing perceptual similarity within a task set.
The Costs and Benefits of Goal-Directed Attention in Deep Convolutional Neural Networks
Feb 06, 2020


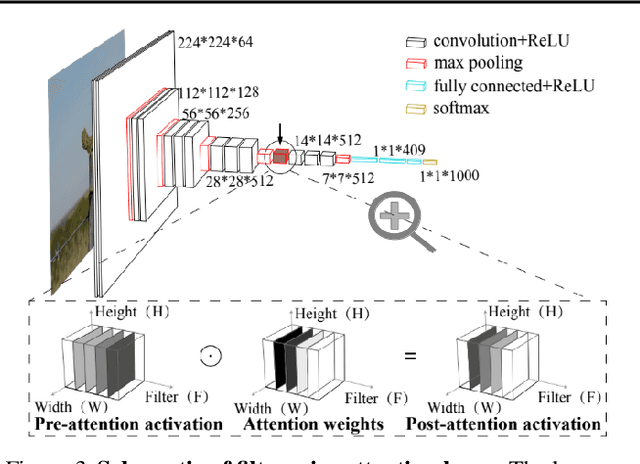
Attention in machine learning is largely bottom-up, whereas people also deploy top-down, goal-directed attention. Motivated by neuroscience research, we evaluated a plug-and-play, top-down attention layer that is easily added to existing deep convolutional neural networks (DCNNs). In object recognition tasks, increasing top-down attention has benefits (increasing hit rates) and costs (increasing false alarm rates). At a moderate level, attention improves sensitivity (i.e., increases $d^\prime$) at only a moderate increase in bias for tasks involving standard images, blended images, and natural adversarial images. These theoretical results suggest that top-down attention can effectively reconfigure general-purpose DCNNs to better suit the current task goal. We hope our results continue the fruitful dialog between neuroscience and machine learning.
Learning as the Unsupervised Alignment of Conceptual Systems
Jun 21, 2019


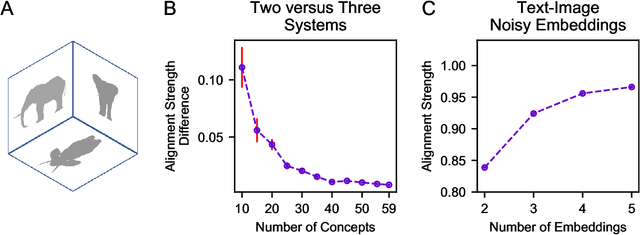
Concept induction requires the extraction and naming of concepts from noisy perceptual experience. For supervised approaches, as the number of concepts grows, so does the number of required training examples. Philosophers, psychologists, and computer scientists, have long recognized that children can learn to label objects without being explicitly taught. In a series of computational experiments, we highlight how information in the environment can be used to build and align conceptual systems. Unlike supervised learning, the learning problem becomes easier the more concepts and systems there are to master. The key insight is that each concept has a unique signature within one conceptual system (e.g., images) that is recapitulated in other systems (e.g., text or audio). As predicted, children's early concepts form readily aligned systems.
Learning to Generate Images with Perceptual Similarity Metrics
Jan 24, 2017
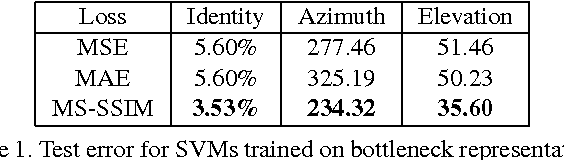
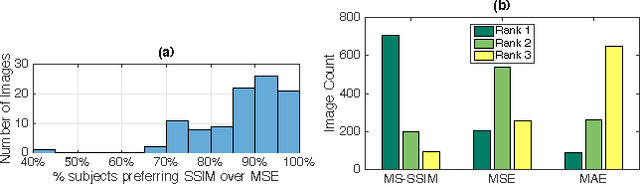
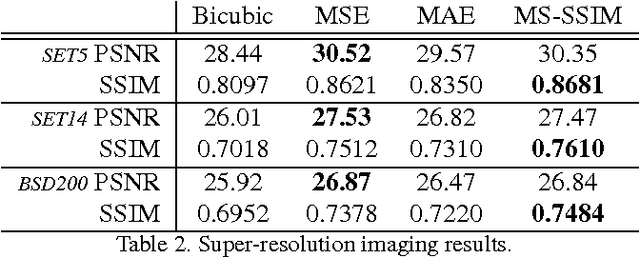
Deep networks are increasingly being applied to problems involving image synthesis, e.g., generating images from textual descriptions and reconstructing an input image from a compact representation. Supervised training of image-synthesis networks typically uses a pixel-wise loss (PL) to indicate the mismatch between a generated image and its corresponding target image. We propose instead to use a loss function that is better calibrated to human perceptual judgments of image quality: the multiscale structural-similarity score (MS-SSIM). Because MS-SSIM is differentiable, it is easily incorporated into gradient-descent learning. We compare the consequences of using MS-SSIM versus PL loss on training deterministic and stochastic autoencoders. For three different architectures, we collected human judgments of the quality of image reconstructions. Observers reliably prefer images synthesized by MS-SSIM-optimized models over those synthesized by PL-optimized models, for two distinct PL measures ($\ell_1$ and $\ell_2$ distances). We also explore the effect of training objective on image encoding and analyze conditions under which perceptually-optimized representations yield better performance on image classification. Finally, we demonstrate the superiority of perceptually-optimized networks for super-resolution imaging. Just as computer vision has advanced through the use of convolutional architectures that mimic the structure of the mammalian visual system, we argue that significant additional advances can be made in modeling images through the use of training objectives that are well aligned to characteristics of human perception.