 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming Neural Network Visual Representations to Predict Human Judgments of Similarity
Paper and Code
Oct 13, 2020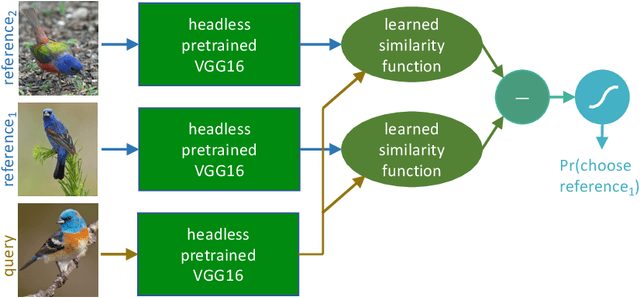
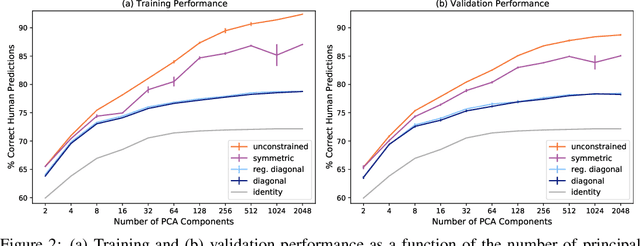
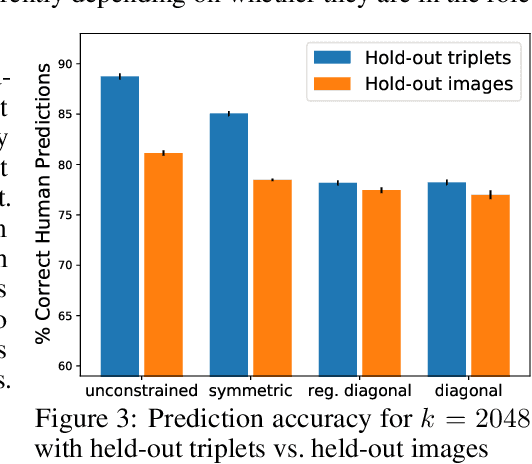
Deep-learning vision models have shown intriguing similarities and differences with respect to human vision. We investigate how to bring machine visual representations into better alignment with human representations. Human representations are often inferred from behavioral evidence such as the selection of an image most similar to a query image. We find that with appropriate linear transformations of deep embeddings, we can improve prediction of human binary choice on a data set of bird images from 72% at baseline to 89%. We hypothesized that deep embeddings have redundant, high (4096) dimensional representations; however, reducing the rank of these representations results in a loss of explanatory power. We hypothesized that the dilation transformation of representations explored in past research is too restrictive, and indeed we found that model explanatory power can be significantly improved with a more expressive linear transform. Most surprising and exciting, we found that, consistent with classic psychological literature, human similarity judgments are asymmetric: the similarity of X to Y is not necessarily equal to the similarity of Y to X, and allowing models to express this asymmetry improves explanatory power.