 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll in One: A Unified Synthetic Data Pipeline for Multimodal Video Understanding
Apr 14, 2026Training multimodal large language models (MLLMs) for video understanding requires large-scale annotated data spanning diverse tasks such as object counting, question answering, and segmentation. However, collecting and annotating multimodal video data in real-world is costly, slow, and inherently limited in diversity and coverage. To address this challenge, we propose a unified synthetic data generation pipeline capable of automatically producing unlimited multimodal video data with rich and diverse supervision. Our framework supports multiple task formats within a single pipeline, enabling scalable and consistent data creation across tasks. To further enhance reasoning ability, we introduce a VQA-based fine-tuning strategy that trains models to answer structured questions about visual content rather than relying solely on captions or simple instructions. This formulation encourages deeper visual grounding and reasoning. We evaluate our approach in three challenging tasks: video object counting, video-based visual question answering, and video object segmentation. Experimental results demonstrate that models trained predominantly on synthetic data generalize effectively to real-world datasets, often outperforming traditionally trained counterparts. Our findings highlight the potential of unified synthetic data pipelines as a scalable alternative to expensive real-world annotation for multimodal video understanding.
TrajLoom: Dense Future Trajectory Generation from Video
Mar 23, 2026Predicting future motion is crucial in video understanding and controllable video generation. Dense point trajectories are a compact, expressive motion representation, but modeling their future evolution from observed video remains challenging. We propose a framework that predicts future trajectories and visibility from past trajectories and video context. Our method has three components: (1) Grid-Anchor Offset Encoding, which reduces location-dependent bias by representing each point as an offset from its pixel-center anchor; (2) TrajLoom-VAE, which learns a compact spatiotemporal latent space for dense trajectories with masked reconstruction and a spatiotemporal consistency regularizer; and (3) TrajLoom-Flow, which generates future trajectories in latent space via flow matching, with boundary cues and on-policy K-step fine-tuning for stable sampling. We also introduce TrajLoomBench, a unified benchmark spanning real and synthetic videos with a standardized setup aligned with video-generation benchmarks. Compared with state-of-the-art methods, our approach extends the prediction horizon from 24 to 81 frames while improving motion realism and stability across datasets. The predicted trajectories directly support downstream video generation and editing. Code, model checkpoints, and datasets are available at https://trajloom.github.io/.
Stable Velocity: A Variance Perspective on Flow Matching
Feb 05, 2026While flow matching is elegant, its reliance on single-sample conditional velocities leads to high-variance training targets that destabilize optimization and slow convergence. By explicitly characterizing this variance, we identify 1) a high-variance regime near the prior, where optimization is challenging, and 2) a low-variance regime near the data distribution, where conditional and marginal velocities nearly coincide. Leveraging this insight, we propose Stable Velocity, a unified framework that improves both training and sampling. For training, we introduce Stable Velocity Matching (StableVM), an unbiased variance-reduction objective, along with Variance-Aware Representation Alignment (VA-REPA), which adaptively strengthen auxiliary supervision in the low-variance regime. For inference, we show that dynamics in the low-variance regime admit closed-form simplifications, enabling Stable Velocity Sampling (StableVS), a finetuning-free acceleration. Extensive experiments on ImageNet $256\times256$ and large pretrained text-to-image and text-to-video models, including SD3.5, Flux, Qwen-Image, and Wan2.2, demonstrate consistent improvements in training efficiency and more than $2\times$ faster sampling within the low-variance regime without degrading sample quality. Our code is available at https://github.com/linYDTHU/StableVelocity.
Point transformer for protein structural heterogeneity analysis using CryoEM
Jan 26, 2026Structural dynamics of macromolecules is critical to their structural-function relationship. Cryogenic electron microscopy (CryoEM) provides snapshots of vitrified protein at different compositional and conformational states, and the structural heterogeneity of proteins can be characterized through computational analysis of the images. For protein systems with multiple degrees of freedom, it is still challenging to disentangle and interpret the different modes of dynamics. Here, by implementing Point Transformer, a self-attention network designed for point cloud analysis, we are able to improve the performance of heterogeneity analysis on CryoEM data, and characterize the dynamics of highly complex protein systems in a more human-interpretable way.
Scaling Generative Verifiers For Natural Language Mathematical Proof Verification And Selection
Nov 17, 2025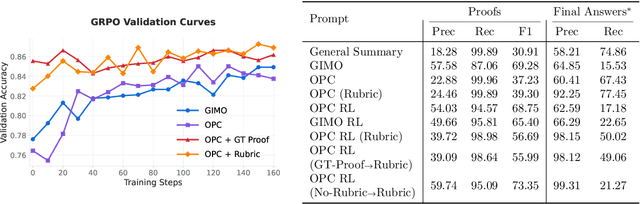
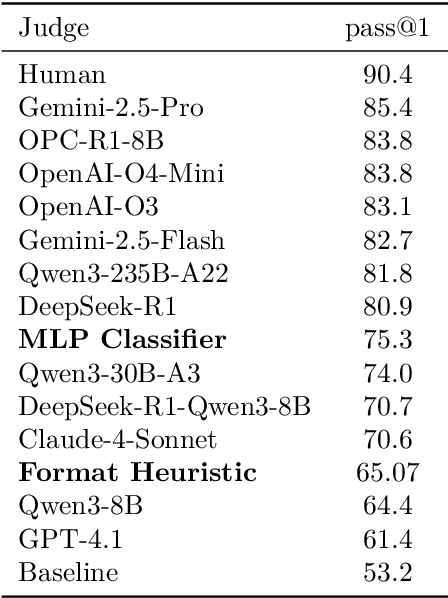
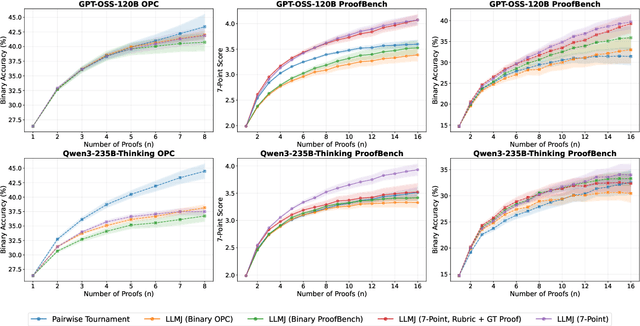

Large language models have achieved remarkable success on final-answer mathematical problems, largely due to the ease of applying reinforcement learning with verifiable rewards. However, the reasoning underlying these solutions is often flawed. Advancing to rigorous proof-based mathematics requires reliable proof verification capabilities. We begin by analyzing multiple evaluation setups and show that focusing on a single benchmark can lead to brittle or misleading conclusions. To address this, we evaluate both proof-based and final-answer reasoning to obtain a more reliable measure of model performance. We then scale two major generative verification methods (GenSelect and LLM-as-a-Judge) to millions of tokens and identify their combination as the most effective framework for solution verification and selection. We further show that the choice of prompt for LLM-as-a-Judge significantly affects the model's performance, but reinforcement learning can reduce this sensitivity. However, despite improving proof-level metrics, reinforcement learning does not enhance final-answer precision, indicating that current models often reward stylistic or procedural correctness rather than mathematical validity. Our results establish practical guidelines for designing and evaluating scalable proof-verification and selection systems.
ControlEchoSynth: Boosting Ejection Fraction Estimation Models via Controlled Video Diffusion
Aug 25, 2025



Synthetic data generation represents a significant advancement in boosting the performance of machine learning (ML) models, particularly in fields where data acquisition is challenging, such as echocardiography. The acquisition and labeling of echocardiograms (echo) for heart assessment, crucial in point-of-care ultrasound (POCUS) settings, often encounter limitations due to the restricted number of echo views available, typically captured by operators with varying levels of experience. This study proposes a novel approach for enhancing clinical diagnosis accuracy by synthetically generating echo views. These views are conditioned on existing, real views of the heart, focusing specifically on the estimation of ejection fraction (EF), a critical parameter traditionally measured from biplane apical views. By integrating a conditional generative model, we demonstrate an improvement in EF estimation accuracy, providing a comparative analysis with traditional methods. Preliminary results indicate that our synthetic echoes, when used to augment existing datasets, not only enhance EF estimation but also show potential in advancing the development of more robust, accurate, and clinically relevant ML models. This approach is anticipated to catalyze further research in synthetic data applications, paving the way for innovative solutions in medical imaging diagnostics.
Score Augmentation for Diffusion Models
Aug 11, 2025Diffusion models have achieved remarkable success in generative modeling. However, this study confirms the existence of overfitting in diffusion model training, particularly in data-limited regimes. To address this challenge, we propose Score Augmentation (ScoreAug), a novel data augmentation framework specifically designed for diffusion models. Unlike conventional augmentation approaches that operate on clean data, ScoreAug applies transformations to noisy data, aligning with the inherent denoising mechanism of diffusion. Crucially, ScoreAug further requires the denoiser to predict the augmentation of the original target. This design establishes an equivariant learning objective, enabling the denoiser to learn scores across varied denoising spaces, thereby realizing what we term score augmentation. We also theoretically analyze the relationship between scores in different spaces under general transformations. In experiments, we extensively validate ScoreAug on multiple benchmarks including CIFAR-10, FFHQ, AFHQv2, and ImageNet, with results demonstrating significant performance improvements over baselines. Notably, ScoreAug effectively mitigates overfitting across diverse scenarios, such as varying data scales and model capacities, while exhibiting stable convergence properties. Another advantage of ScoreAug over standard data augmentation lies in its ability to circumvent data leakage issues under certain conditions. Furthermore, we show that ScoreAug can be synergistically combined with traditional data augmentation techniques to achieve additional performance gains.
TrajFlow: Multi-modal Motion Prediction via Flow Matching
Jun 10, 2025Efficient and accurate motion prediction is crucial for ensuring safety and informed decision-making in autonomous driving, particularly under dynamic real-world conditions that necessitate multi-modal forecasts. We introduce TrajFlow, a novel flow matching-based motion prediction framework that addresses the scalability and efficiency challenges of existing generative trajectory prediction methods. Unlike conventional generative approaches that employ i.i.d. sampling and require multiple inference passes to capture diverse outcomes, TrajFlow predicts multiple plausible future trajectories in a single pass, significantly reducing computational overhead while maintaining coherence across predictions. Moreover, we propose a ranking loss based on the Plackett-Luce distribution to improve uncertainty estimation of predicted trajectories. Additionally, we design a self-conditioning training technique that reuses the model's own predictions to construct noisy inputs during a second forward pass, thereby improving generalization and accelerating inference. Extensive experiments on the large-scale Waymo Open Motion Dataset (WOMD) demonstrate that TrajFlow achieves state-of-the-art performance across various key metrics, underscoring its effectiveness for safety-critical autonomous driving applications. The code and other details are available on the project website https://traj-flow.github.io/.
StreamSplat: Towards Online Dynamic 3D Reconstruction from Uncalibrated Video Streams
Jun 10, 2025Real-time reconstruction of dynamic 3D scenes from uncalibrated video streams is crucial for numerous real-world applications. However, existing methods struggle to jointly address three key challenges: 1) processing uncalibrated inputs in real time, 2) accurately modeling dynamic scene evolution, and 3) maintaining long-term stability and computational efficiency. To this end, we introduce StreamSplat, the first fully feed-forward framework that transforms uncalibrated video streams of arbitrary length into dynamic 3D Gaussian Splatting (3DGS) representations in an online manner, capable of recovering scene dynamics from temporally local observations. We propose two key technical innovations: a probabilistic sampling mechanism in the static encoder for 3DGS position prediction, and a bidirectional deformation field in the dynamic decoder that enables robust and efficient dynamic modeling. Extensive experiments on static and dynamic benchmarks demonstrate that StreamSplat consistently outperforms prior works in both reconstruction quality and dynamic scene modeling, while uniquely supporting online reconstruction of arbitrarily long video streams. Code and models are available at https://github.com/nickwzk/StreamSplat.
Neural MJD: Neural Non-Stationary Merton Jump Diffusion for Time Series Prediction
Jun 05, 2025While deep learning methods have achieved strong performance in time series prediction, their black-box nature and inability to explicitly model underlying stochastic processes often limit their generalization to non-stationary data, especially in the presence of abrupt changes. In this work, we introduce Neural MJD, a neural network based non-stationary Merton jump diffusion (MJD) model. Our model explicitly formulates forecasting as a stochastic differential equation (SDE) simulation problem, combining a time-inhomogeneous It\^o diffusion to capture non-stationary stochastic dynamics with a time-inhomogeneous compound Poisson process to model abrupt jumps. To enable tractable learning, we introduce a likelihood truncation mechanism that caps the number of jumps within small time intervals and provide a theoretical error bound for this approximation. Additionally, we propose an Euler-Maruyama with restart solver, which achieves a provably lower error bound in estimating expected states and reduced variance compared to the standard solver. Experiments on both synthetic and real-world datasets demonstrate that Neural MJD consistently outperforms state-of-the-art deep learning and statistical learning methods.