 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Generative Selection for Best-of-N
Feb 02, 2026Scaling test-time compute via parallel sampling can substantially improve LLM reasoning, but is often limited by Best-of-N selection quality. Generative selection methods, such as GenSelect, address this bottleneck, yet strong selection performance remains largely limited to large models. We show that small reasoning models can acquire strong GenSelect capabilities through targeted reinforcement learning. To this end, we synthesize selection tasks from large-scale math and code instruction datasets by filtering to instances with both correct and incorrect candidate solutions, and train 1.7B-parameter models with DAPO to reward correct selections. Across math (AIME24, AIME25, HMMT25) and code (LiveCodeBench) reasoning benchmarks, our models consistently outperform prompting and majority-voting baselines, often approaching or exceeding much larger models. Moreover, these gains generalize to selecting outputs from stronger models despite training only on outputs from weaker models. Overall, our results establish reinforcement learning as a scalable way to unlock strong generative selection in small models, enabling efficient test-time scaling.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
Nemotron-Math: Efficient Long-Context Distillation of Mathematical Reasoning from Multi-Mode Supervision
Dec 17, 2025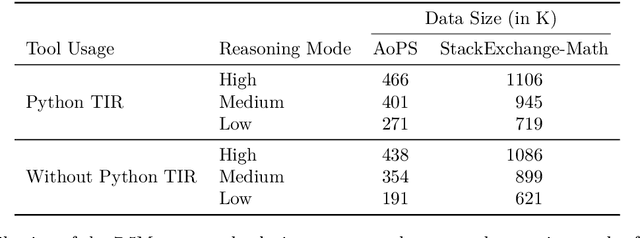
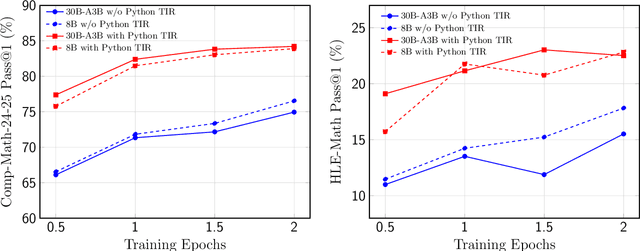

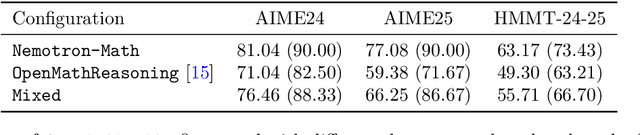
High-quality mathematical reasoning supervision requires diverse reasoning styles, long-form traces, and effective tool integration, capabilities that existing datasets provide only in limited form. Leveraging the multi-mode generation ability of gpt-oss-120b, we introduce Nemotron-Math, a large-scale mathematical reasoning dataset containing 7.5M solution traces across high, medium, and low reasoning modes, each available both with and without Python tool-integrated reasoning (TIR). The dataset integrates 85K curated AoPS problems with 262K community-sourced StackExchange-Math problems, combining structured competition tasks with diverse real-world mathematical queries. We conduct controlled evaluations to assess the dataset quality. Nemotron-Math consistently outperforms the original OpenMathReasoning on matched AoPS problems. Incorporating StackExchange-Math substantially improves robustness and generalization, especially on HLE-Math, while preserving accuracy on math competition benchmarks. To support efficient long-context training, we develop a sequential bucketed strategy that accelerates 128K context-length fine-tuning by 2--3$\times$ without significant accuracy loss. Overall, Nemotron-Math enables state-of-the-art performance, including 100\% maj@16 accuracy on AIME 2024 and 2025 with Python TIR.
Scaling Generative Verifiers For Natural Language Mathematical Proof Verification And Selection
Nov 17, 2025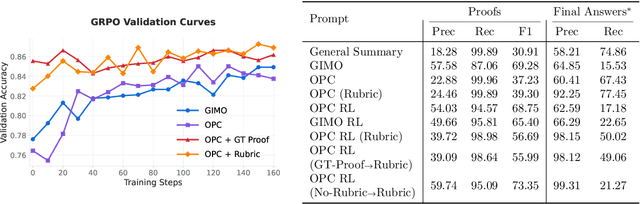
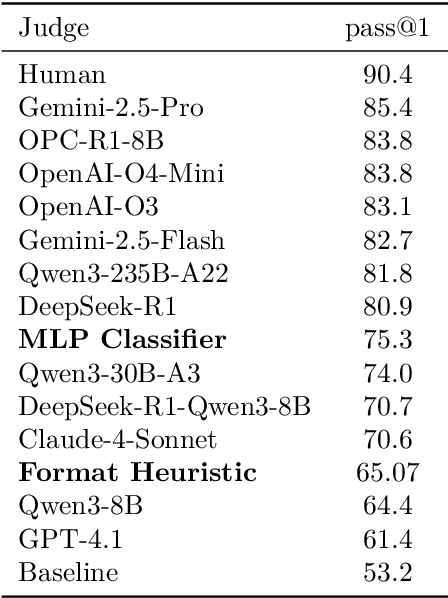
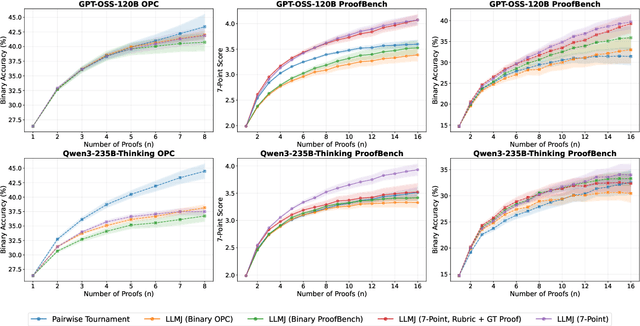

Large language models have achieved remarkable success on final-answer mathematical problems, largely due to the ease of applying reinforcement learning with verifiable rewards. However, the reasoning underlying these solutions is often flawed. Advancing to rigorous proof-based mathematics requires reliable proof verification capabilities. We begin by analyzing multiple evaluation setups and show that focusing on a single benchmark can lead to brittle or misleading conclusions. To address this, we evaluate both proof-based and final-answer reasoning to obtain a more reliable measure of model performance. We then scale two major generative verification methods (GenSelect and LLM-as-a-Judge) to millions of tokens and identify their combination as the most effective framework for solution verification and selection. We further show that the choice of prompt for LLM-as-a-Judge significantly affects the model's performance, but reinforcement learning can reduce this sensitivity. However, despite improving proof-level metrics, reinforcement learning does not enhance final-answer precision, indicating that current models often reward stylistic or procedural correctness rather than mathematical validity. Our results establish practical guidelines for designing and evaluating scalable proof-verification and selection systems.
Advantage Shaping as Surrogate Reward Maximization: Unifying Pass@K Policy Gradients
Oct 27, 2025This note reconciles two seemingly distinct approaches to policy gradient optimization for the Pass@K objective in reinforcement learning with verifiable rewards: (1) direct REINFORCE-style methods, and (2) advantage-shaping techniques that directly modify GRPO. We show that these are two sides of the same coin. By reverse-engineering existing advantage-shaping algorithms, we reveal that they implicitly optimize surrogate rewards. We specifically interpret practical ``hard-example up-weighting'' modifications to GRPO as reward-level regularization. Conversely, starting from surrogate reward objectives, we provide a simple recipe for deriving both existing and new advantage-shaping methods. This perspective provides a lens for RLVR policy gradient optimization beyond our original motivation of Pass@K.
Leveraging Online Olympiad-Level Math Problems for LLMs Training and Contamination-Resistant Evaluation
Jan 24, 2025Advances in Large Language Models (LLMs) have sparked interest in their ability to solve Olympiad-level math problems. However, the training and evaluation of these models are constrained by the limited size and quality of available datasets, as creating large-scale data for such advanced problems requires extensive effort from human experts. In addition, current benchmarks are prone to contamination, leading to unreliable evaluations. In this paper, we present an automated pipeline that leverages the rich resources of the Art of Problem Solving (AoPS) forum, which predominantly features Olympiad-level problems and community-driven solutions. Using open-source LLMs, we develop a method to extract question-answer pairs from the forum, resulting in AoPS-Instruct, a dataset of more than 600,000 high-quality QA pairs. Our experiments demonstrate that fine-tuning LLMs on AoPS-Instruct improves their reasoning abilities across various benchmarks. Moreover, we build an automatic pipeline that introduces LiveAoPSBench, an evolving evaluation set with timestamps, derived from the latest forum data, providing a contamination-resistant benchmark for assessing LLM performance. Notably, we observe a significant decline in LLM performance over time, suggesting their success on older examples may stem from pre-training exposure rather than true reasoning ability. Our work presents a scalable approach to creating and maintaining large-scale, high-quality datasets for advanced math reasoning, offering valuable insights into the capabilities and limitations of LLMs in this domain. Our benchmark and code is available at https://github.com/DSL-Lab/aops
From Graph Diffusion to Graph Classification
Nov 26, 2024



Generative models such as diffusion models have achieved remarkable success in state-of-the-art image and text tasks. Recently, score-based diffusion models have extended their success beyond image generation, showing competitive performance with discriminative methods in image {\em classification} tasks~\cite{zimmermann2021score}. However, their application to classification in the {\em graph} domain, which presents unique challenges such as complex topologies, remains underexplored. We show how graph diffusion models can be applied for graph classification. We find that to achieve competitive classification accuracy, score-based graph diffusion models should be trained with a novel training objective that is tailored to graph classification. In experiments with a sampling-based inference method, our discriminative training objective achieves state-of-the-art graph classification accuracy.
Leveraging Environment Interaction for Automated PDDL Generation and Planning with Large Language Models
Jul 17, 2024

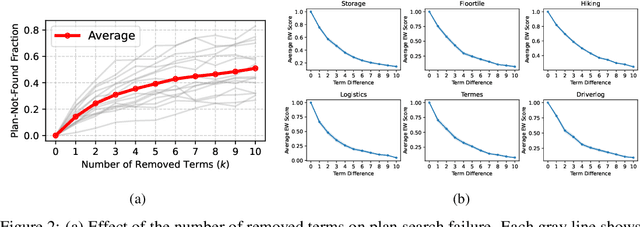
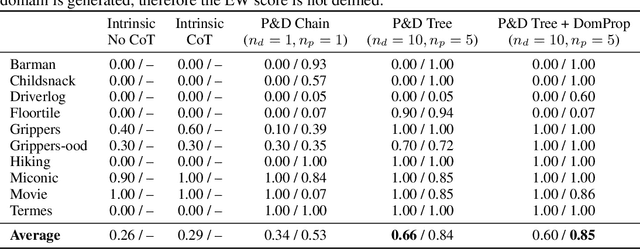
Large Language Models (LLMs) have shown remarkable performance in various natural language tasks, but they often struggle with planning problems that require structured reasoning. To address this limitation, the conversion of planning problems into the Planning Domain Definition Language (PDDL) has been proposed as a potential solution, enabling the use of automated planners. However, generating accurate PDDL files typically demands human inputs or correction, which can be time-consuming and costly. In this paper, we propose a novel approach that leverages LLMs and environment feedback to automatically generate PDDL domain and problem description files without the need for human intervention. Our method introduces an iterative refinement process that generates multiple problem PDDL candidates and progressively refines the domain PDDL based on feedback obtained from interacting with the environment. To guide the refinement process, we develop an Exploration Walk (EW) metric, which provides rich feedback signals for LLMs to update the PDDL file. We evaluate our approach on PDDL environments. We achieve an average task solve rate of 66% compared to a 29% solve rate by GPT-4's intrinsic planning with chain-of-thought prompting. Our work enables the automated modeling of planning environments using LLMs and environment feedback, eliminating the need for human intervention in the PDDL generation process and paving the way for more reliable LLM agents in challenging problems.
Memorization Capacity of Multi-Head Attention in Transformers
Jun 03, 2023In this paper, we investigate the memorization capabilities of multi-head attention in Transformers, motivated by the central role attention plays in these models. Under a mild linear independence assumption on the input data, we present a theoretical analysis demonstrating that an $H$-head attention layer with a context size $n$, dimension $d$, and $O(Hd^2)$ parameters can memorize $O(Hn)$ examples. We conduct experiments that verify our assumptions on the image classification task using Vision Transformer. To validate our theoretical findings, we perform synthetic experiments and show a linear relationship between memorization capacity and the number of attention heads.