 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Environment Interaction for Automated PDDL Generation and Planning with Large Language Models
Jul 17, 2024

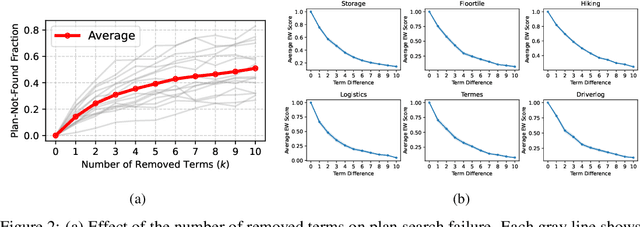
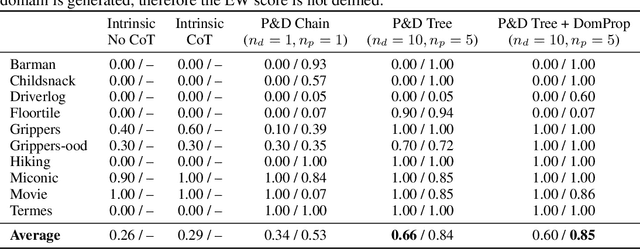
Large Language Models (LLMs) have shown remarkable performance in various natural language tasks, but they often struggle with planning problems that require structured reasoning. To address this limitation, the conversion of planning problems into the Planning Domain Definition Language (PDDL) has been proposed as a potential solution, enabling the use of automated planners. However, generating accurate PDDL files typically demands human inputs or correction, which can be time-consuming and costly. In this paper, we propose a novel approach that leverages LLMs and environment feedback to automatically generate PDDL domain and problem description files without the need for human intervention. Our method introduces an iterative refinement process that generates multiple problem PDDL candidates and progressively refines the domain PDDL based on feedback obtained from interacting with the environment. To guide the refinement process, we develop an Exploration Walk (EW) metric, which provides rich feedback signals for LLMs to update the PDDL file. We evaluate our approach on PDDL environments. We achieve an average task solve rate of 66% compared to a 29% solve rate by GPT-4's intrinsic planning with chain-of-thought prompting. Our work enables the automated modeling of planning environments using LLMs and environment feedback, eliminating the need for human intervention in the PDDL generation process and paving the way for more reliable LLM agents in challenging problems.
Counterfactual Explanations for Multivariate Time-Series without Training Datasets
May 28, 2024Machine learning (ML) methods have experienced significant growth in the past decade, yet their practical application in high-impact real-world domains has been hindered by their opacity. When ML methods are responsible for making critical decisions, stakeholders often require insights into how to alter these decisions. Counterfactual explanations (CFEs) have emerged as a solution, offering interpretations of opaque ML models and providing a pathway to transition from one decision to another. However, most existing CFE methods require access to the model's training dataset, few methods can handle multivariate time-series, and none can handle multivariate time-series without training datasets. These limitations can be formidable in many scenarios. In this paper, we present CFWoT, a novel reinforcement-learning-based CFE method that generates CFEs when training datasets are unavailable. CFWoT is model-agnostic and suitable for both static and multivariate time-series datasets with continuous and discrete features. Users have the flexibility to specify non-actionable, immutable, and preferred features, as well as causal constraints which CFWoT guarantees will be respected. We demonstrate the performance of CFWoT against four baselines on several datasets and find that, despite not having access to a training dataset, CFWoT finds CFEs that make significantly fewer and significantly smaller changes to the input time-series. These properties make CFEs more actionable, as the magnitude of change required to alter an outcome is vastly reduced.
Causal Inference from Small High-dimensional Datasets
May 19, 2022


Many methods have been proposed to estimate treatment effects with observational data. Often, the choice of the method considers the application's characteristics, such as type of treatment and outcome, confounding effect, and the complexity of the data. These methods implicitly assume that the sample size is large enough to train such models, especially the neural network-based estimators. What if this is not the case? In this work, we propose Causal-Batle, a methodology to estimate treatment effects in small high-dimensional datasets in the presence of another high-dimensional dataset in the same feature space. We adopt an approach that brings transfer learning techniques into causal inference. Our experiments show that such an approach helps to bring stability to neural network-based methods and improve the treatment effect estimates in small high-dimensional datasets.
M3E2: Multi-gate Mixture-of-experts for Multi-treatment Effect Estimation
Dec 14, 2021
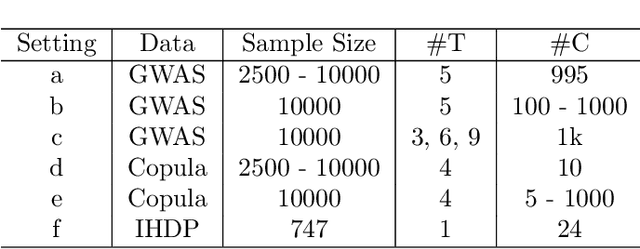
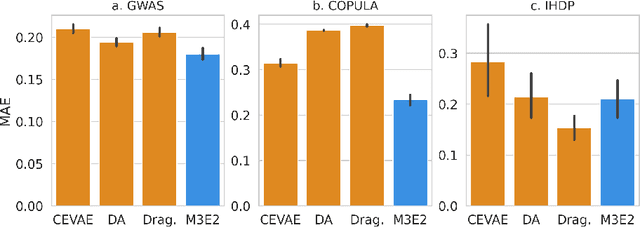

This work proposes the M3E2, a multi-task learning neural network model to estimate the effect of multiple treatments. In contrast to existing methods, M3E2 is robust to multiple treatment effects applied simultaneously to the same unit, continuous and binary treatments, and many covariates. We compared M3E2 with three baselines in three synthetic benchmark datasets: two with multiple treatments and one with one treatment. Our analysis showed that our method has superior performance, making more assertive estimations of the true treatment effects. The code is available at github.com/raquelaoki/M3E2.
Heterogeneous Multi-task Learning with Expert Diversity
Jun 20, 2021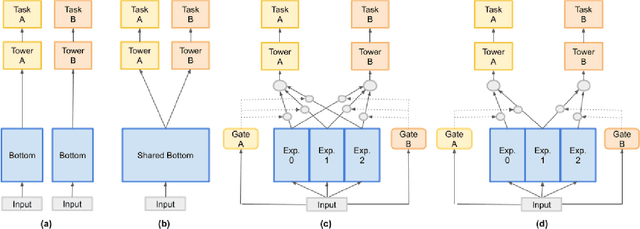
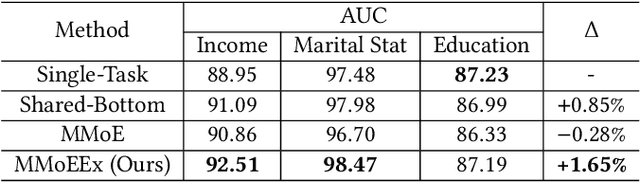
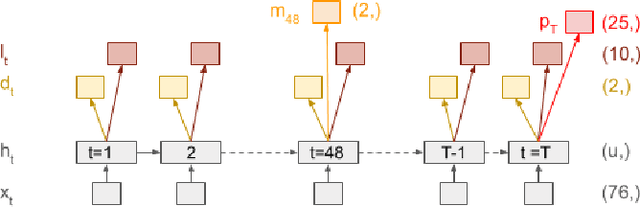
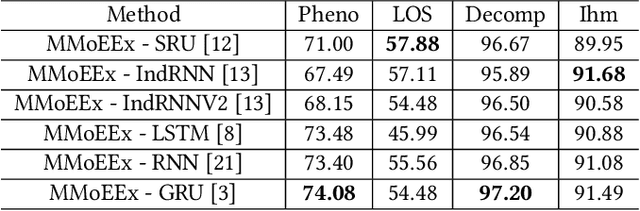
Predicting multiple heterogeneous biological and medical targets is a challenge for traditional deep learning models. In contrast to single-task learning, in which a separate model is trained for each target, multi-task learning (MTL) optimizes a single model to predict multiple related targets simultaneously. To address this challenge, we propose the Multi-gate Mixture-of-Experts with Exclusivity (MMoEEx). Our work aims to tackle the heterogeneous MTL setting, in which the same model optimizes multiple tasks with different characteristics. Such a scenario can overwhelm current MTL approaches due to the challenges in balancing shared and task-specific representations and the need to optimize tasks with competing optimization paths. Our method makes two key contributions: first, we introduce an approach to induce more diversity among experts, thus creating representations more suitable for highly imbalanced and heterogenous MTL learning; second, we adopt a two-step optimization [6, 11] approach to balancing the tasks at the gradient level. We validate our method on three MTL benchmark datasets, including Medical Information Mart for Intensive Care (MIMIC-III) and PubChem BioAssay (PCBA).
ParKCa: Causal Inference with Partially Known Causes
Mar 17, 2020
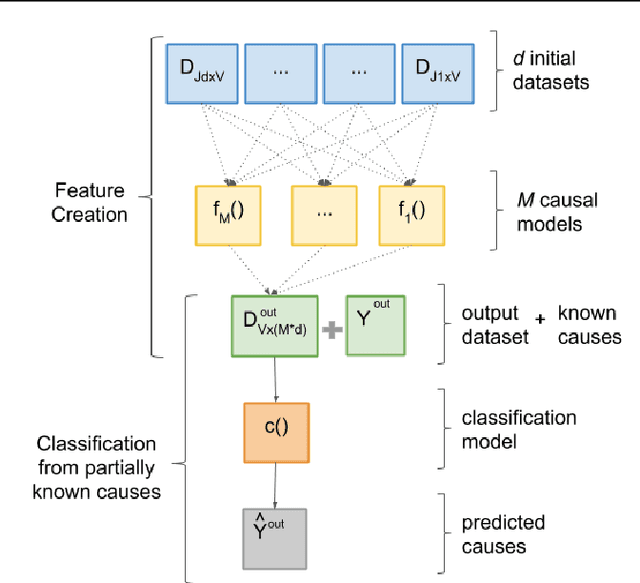


Causal Inference methods based on observational data are an alternative for applications where collecting the counterfactual data or realizing a more standard experiment is not possible. In this work, our goal is to combine several observational causal inference methods to learn new causes in applications where some causes are well known. We validate the proposed method on The Cancer Genome Atlas (TCGA) dataset to identify genes that potentially cause metastasis.