 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJump Start or False Start? A Theoretical and Empirical Evaluation of LLM-initialized Bandits
Apr 02, 2026The recent advancement of Large Language Models (LLMs) offers new opportunities to generate user preference data to warm-start bandits. Recent studies on contextual bandits with LLM initialization (CBLI) have shown that these synthetic priors can significantly lower early regret. However, these findings assume that LLM-generated choices are reasonably aligned with actual user preferences. In this paper, we systematically examine how LLM-generated preferences perform when random and label-flipping noise is injected into the synthetic training data. For aligned domains, we find that warm-starting remains effective up to 30% corruption, loses its advantage around 40%, and degrades performance beyond 50%. When there is systematic misalignment, even without added noise, LLM-generated priors can lead to higher regret than a cold-start bandit. To explain these behaviors, we develop a theoretical analysis that decomposes the effect of random label noise and systematic misalignment on the prior error driving the bandit's regret, and derive a sufficient condition under which LLM-based warm starts are provably better than a cold-start bandit. We validate these results across multiple conjoint datasets and LLMs, showing that estimated alignment reliably tracks when warm-starting improves or degrades recommendation quality.
Privacy-Preserving Vertical K-Means Clustering
Apr 10, 2025



Clustering is a fundamental data processing task used for grouping records based on one or more features. In the vertically partitioned setting, data is distributed among entities, with each holding only a subset of those features. A key challenge in this scenario is that computing distances between records requires access to all distributed features, which may be privacy-sensitive and cannot be directly shared with other parties. The goal is to compute the joint clusters while preserving the privacy of each entity's dataset. Existing solutions using secret sharing or garbled circuits implement privacy-preserving variants of Lloyd's algorithm but incur high communication costs, scaling as O(nkt), where n is the number of data points, k the number of clusters, and t the number of rounds. These methods become impractical for large datasets or several parties, limiting their use to LAN settings only. On the other hand, a different line of solutions rely on differential privacy (DP) to outsource the local features of the parties to a central server. However, they often significantly degrade the utility of the clustering outcome due to excessive noise. In this work, we propose a novel solution based on homomorphic encryption and DP, reducing communication complexity to O(n+kt). In our method, parties securely outsource their features once, allowing a computing party to perform clustering operations under encryption. DP is applied only to the clusters' centroids, ensuring privacy with minimal impact on utility. Our solution clusters 100,000 two-dimensional points into five clusters using only 73MB of communication, compared to 101GB for existing works, and completes in just under 3 minutes on a 100Mbps network, whereas existing works take over 1 day. This makes our solution practical even for WAN deployments, all while maintaining accuracy comparable to plaintext k-means algorithms.
Jump Starting Bandits with LLM-Generated Prior Knowledge
Jun 27, 2024



We present substantial evidence demonstrating the benefits of integrating Large Language Models (LLMs) with a Contextual Multi-Armed Bandit framework. Contextual bandits have been widely used in recommendation systems to generate personalized suggestions based on user-specific contexts. We show that LLMs, pre-trained on extensive corpora rich in human knowledge and preferences, can simulate human behaviours well enough to jump-start contextual multi-armed bandits to reduce online learning regret. We propose an initialization algorithm for contextual bandits by prompting LLMs to produce a pre-training dataset of approximate human preferences for the bandit. This significantly reduces online learning regret and data-gathering costs for training such models. Our approach is validated empirically through two sets of experiments with different bandit setups: one which utilizes LLMs to serve as an oracle and a real-world experiment utilizing data from a conjoint survey experiment.
Counterfactual Explanations for Multivariate Time-Series without Training Datasets
May 28, 2024



Machine learning (ML) methods have experienced significant growth in the past decade, yet their practical application in high-impact real-world domains has been hindered by their opacity. When ML methods are responsible for making critical decisions, stakeholders often require insights into how to alter these decisions. Counterfactual explanations (CFEs) have emerged as a solution, offering interpretations of opaque ML models and providing a pathway to transition from one decision to another. However, most existing CFE methods require access to the model's training dataset, few methods can handle multivariate time-series, and none can handle multivariate time-series without training datasets. These limitations can be formidable in many scenarios. In this paper, we present CFWoT, a novel reinforcement-learning-based CFE method that generates CFEs when training datasets are unavailable. CFWoT is model-agnostic and suitable for both static and multivariate time-series datasets with continuous and discrete features. Users have the flexibility to specify non-actionable, immutable, and preferred features, as well as causal constraints which CFWoT guarantees will be respected. We demonstrate the performance of CFWoT against four baselines on several datasets and find that, despite not having access to a training dataset, CFWoT finds CFEs that make significantly fewer and significantly smaller changes to the input time-series. These properties make CFEs more actionable, as the magnitude of change required to alter an outcome is vastly reduced.
Back to the Basics: Bayesian extensions of IRT outperform neural networks for proficiency estimation
May 21, 2016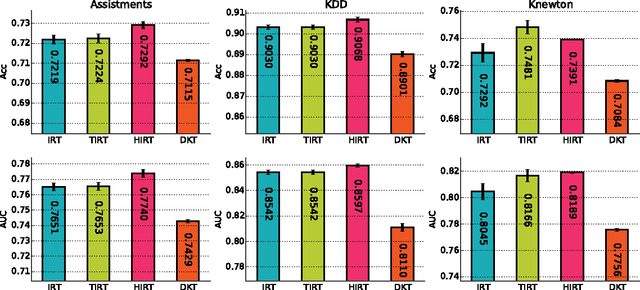

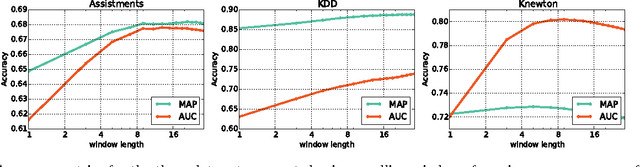
Estimating student proficiency is an important task for computer based learning systems. We compare a family of IRT-based proficiency estimation methods to Deep Knowledge Tracing (DKT), a recently proposed recurrent neural network model with promising initial results. We evaluate how well each model predicts a student's future response given previous responses using two publicly available and one proprietary data set. We find that IRT-based methods consistently matched or outperformed DKT across all data sets at the finest level of content granularity that was tractable for them to be trained on. A hierarchical extension of IRT that captured item grouping structure performed best overall. When data sets included non-trivial autocorrelations in student response patterns, a temporal extension of IRT improved performance over standard IRT while the RNN-based method did not. We conclude that IRT-based models provide a simpler, better-performing alternative to existing RNN-based models of student interaction data while also affording more interpretability and guarantees due to their formulation as Bayesian probabilistic models.