 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCinéaste: A Fine-grained Contextual Movie Question Answering Benchmark
Sep 17, 2025While recent advancements in vision-language models have improved video understanding, diagnosing their capacity for deep, narrative comprehension remains a challenge. Existing benchmarks often test short-clip recognition or use template-based questions, leaving a critical gap in evaluating fine-grained reasoning over long-form narrative content. To address these gaps, we introduce $\mathsf{Cin\acute{e}aste}$, a comprehensive benchmark for long-form movie understanding. Our dataset comprises 3,119 multiple-choice question-answer pairs derived from 1,805 scenes across 200 diverse movies, spanning five novel fine-grained contextual reasoning categories. We use GPT-4o to generate diverse, context-rich questions by integrating visual descriptions, captions, scene titles, and summaries, which require deep narrative understanding. To ensure high-quality evaluation, our pipeline incorporates a two-stage filtering process: Context-Independence filtering ensures questions require video context, while Contextual Veracity filtering validates factual consistency against the movie content, mitigating hallucinations. Experiments show that existing MLLMs struggle on $\mathsf{Cin\acute{e}aste}$; our analysis reveals that long-range temporal reasoning is a primary bottleneck, with the top open-source model achieving only 63.15\% accuracy. This underscores significant challenges in fine-grained contextual understanding and the need for advancements in long-form movie comprehension.
Is Cosine-Similarity of Embeddings Really About Similarity?
Mar 08, 2024
Cosine-similarity is the cosine of the angle between two vectors, or equivalently the dot product between their normalizations. A popular application is to quantify semantic similarity between high-dimensional objects by applying cosine-similarity to a learned low-dimensional feature embedding. This can work better but sometimes also worse than the unnormalized dot-product between embedded vectors in practice. To gain insight into this empirical observation, we study embeddings derived from regularized linear models, where closed-form solutions facilitate analytical insights. We derive analytically how cosine-similarity can yield arbitrary and therefore meaningless `similarities.' For some linear models the similarities are not even unique, while for others they are implicitly controlled by the regularization. We discuss implications beyond linear models: a combination of different regularizations are employed when learning deep models; these have implicit and unintended effects when taking cosine-similarities of the resulting embeddings, rendering results opaque and possibly arbitrary. Based on these insights, we caution against blindly using cosine-similarity and outline alternatives.
* 9 pages
T-SKIRT: Online Estimation of Student Proficiency in an Adaptive Learning System
Feb 14, 2017

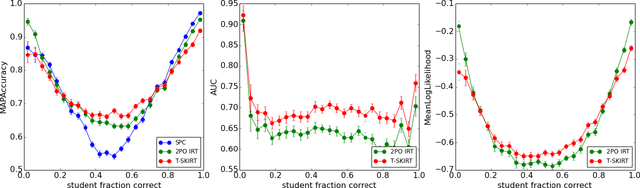
We develop T-SKIRT: a temporal, structured-knowledge, IRT-based method for predicting student responses online. By explicitly accounting for student learning and employing a structured, multidimensional representation of student proficiencies, the model outperforms standard IRT-based methods on an online response prediction task when applied to real responses collected from students interacting with diverse pools of educational content.
Back to the Basics: Bayesian extensions of IRT outperform neural networks for proficiency estimation
May 21, 2016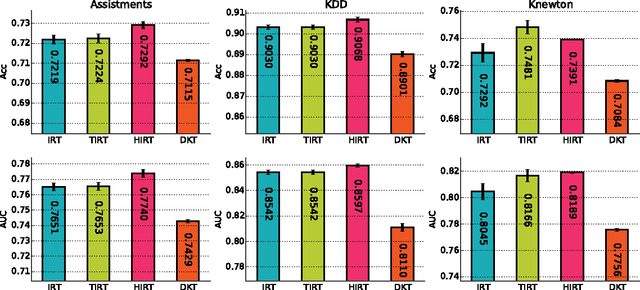

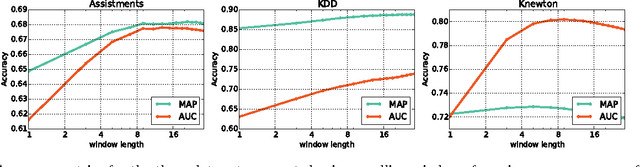
Estimating student proficiency is an important task for computer based learning systems. We compare a family of IRT-based proficiency estimation methods to Deep Knowledge Tracing (DKT), a recently proposed recurrent neural network model with promising initial results. We evaluate how well each model predicts a student's future response given previous responses using two publicly available and one proprietary data set. We find that IRT-based methods consistently matched or outperformed DKT across all data sets at the finest level of content granularity that was tractable for them to be trained on. A hierarchical extension of IRT that captured item grouping structure performed best overall. When data sets included non-trivial autocorrelations in student response patterns, a temporal extension of IRT improved performance over standard IRT while the RNN-based method did not. We conclude that IRT-based models provide a simpler, better-performing alternative to existing RNN-based models of student interaction data while also affording more interpretability and guarantees due to their formulation as Bayesian probabilistic models.