 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Reviews to Dialogues: Active Synthesis for Zero-Shot LLM-based Conversational Recommender System
Apr 21, 2025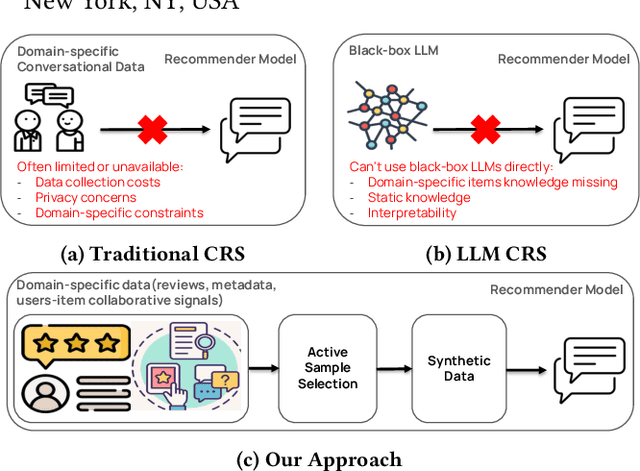
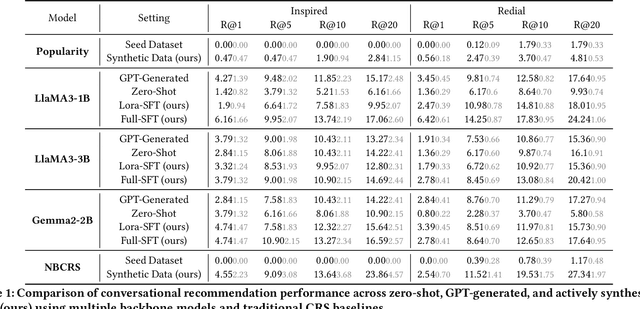
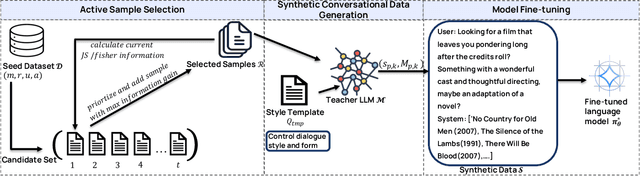
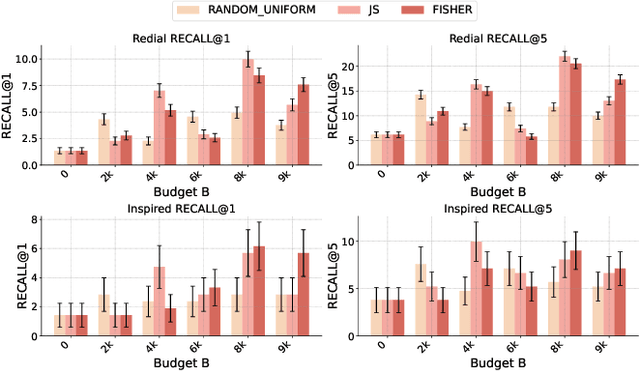
Conversational recommender systems (CRS) typically require extensive domain-specific conversational datasets, yet high costs, privacy concerns, and data-collection challenges severely limit their availability. Although Large Language Models (LLMs) demonstrate strong zero-shot recommendation capabilities, practical applications often favor smaller, internally managed recommender models due to scalability, interpretability, and data privacy constraints, especially in sensitive or rapidly evolving domains. However, training these smaller models effectively still demands substantial domain-specific conversational data, which remains challenging to obtain. To address these limitations, we propose an active data augmentation framework that synthesizes conversational training data by leveraging black-box LLMs guided by active learning techniques. Specifically, our method utilizes publicly available non-conversational domain data, including item metadata, user reviews, and collaborative signals, as seed inputs. By employing active learning strategies to select the most informative seed samples, our approach efficiently guides LLMs to generate synthetic, semantically coherent conversational interactions tailored explicitly to the target domain. Extensive experiments validate that conversational data generated by our proposed framework significantly improves the performance of LLM-based CRS models, effectively addressing the challenges of building CRS in no- or low-resource scenarios.
Collaborative Retrieval for Large Language Model-based Conversational Recommender Systems
Feb 19, 2025
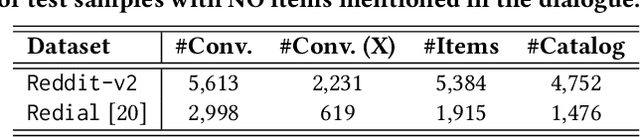
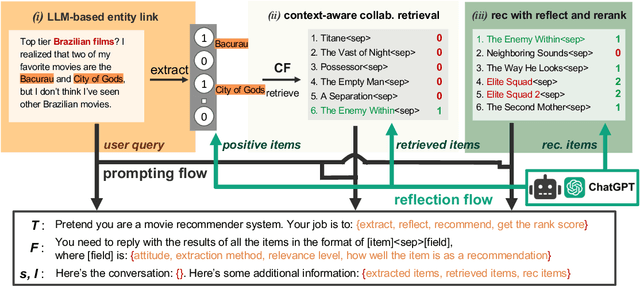

Conversational recommender systems (CRS) aim to provide personalized recommendations via interactive dialogues with users. While large language models (LLMs) enhance CRS with their superior understanding of context-aware user preferences, they typically struggle to leverage behavioral data, which have proven to be important for classical collaborative filtering (CF)-based approaches. For this reason, we propose CRAG, Collaborative Retrieval Augmented Generation for LLM-based CRS. To the best of our knowledge, CRAG is the first approach that combines state-of-the-art LLMs with CF for conversational recommendations. Our experiments on two publicly available movie conversational recommendation datasets, i.e., a refined Reddit dataset (which we name Reddit-v2) as well as the Redial dataset, demonstrate the superior item coverage and recommendation performance of CRAG, compared to several CRS baselines. Moreover, we observe that the improvements are mainly due to better recommendation accuracy on recently released movies. The code and data are available at https://github.com/yaochenzhu/CRAG.
Reindex-Then-Adapt: Improving Large Language Models for Conversational Recommendation
May 20, 2024Large language models (LLMs) are revolutionizing conversational recommender systems by adeptly indexing item content, understanding complex conversational contexts, and generating relevant item titles. However, controlling the distribution of recommended items remains a challenge. This leads to suboptimal performance due to the failure to capture rapidly changing data distributions, such as item popularity, on targeted conversational recommendation platforms. In conversational recommendation, LLMs recommend items by generating the titles (as multiple tokens) autoregressively, making it difficult to obtain and control the recommendations over all items. Thus, we propose a Reindex-Then-Adapt (RTA) framework, which converts multi-token item titles into single tokens within LLMs, and then adjusts the probability distributions over these single-token item titles accordingly. The RTA framework marries the benefits of both LLMs and traditional recommender systems (RecSys): understanding complex queries as LLMs do; while efficiently controlling the recommended item distributions in conversational recommendations as traditional RecSys do. Our framework demonstrates improved accuracy metrics across three different conversational recommendation datasets and two adaptation settings
Is Cosine-Similarity of Embeddings Really About Similarity?
Mar 08, 2024
Cosine-similarity is the cosine of the angle between two vectors, or equivalently the dot product between their normalizations. A popular application is to quantify semantic similarity between high-dimensional objects by applying cosine-similarity to a learned low-dimensional feature embedding. This can work better but sometimes also worse than the unnormalized dot-product between embedded vectors in practice. To gain insight into this empirical observation, we study embeddings derived from regularized linear models, where closed-form solutions facilitate analytical insights. We derive analytically how cosine-similarity can yield arbitrary and therefore meaningless `similarities.' For some linear models the similarities are not even unique, while for others they are implicitly controlled by the regularization. We discuss implications beyond linear models: a combination of different regularizations are employed when learning deep models; these have implicit and unintended effects when taking cosine-similarities of the resulting embeddings, rendering results opaque and possibly arbitrary. Based on these insights, we caution against blindly using cosine-similarity and outline alternatives.
* 9 pages
Large Language Models as Zero-Shot Conversational Recommenders
Aug 19, 2023



In this paper, we present empirical studies on conversational recommendation tasks using representative large language models in a zero-shot setting with three primary contributions. (1) Data: To gain insights into model behavior in "in-the-wild" conversational recommendation scenarios, we construct a new dataset of recommendation-related conversations by scraping a popular discussion website. This is the largest public real-world conversational recommendation dataset to date. (2) Evaluation: On the new dataset and two existing conversational recommendation datasets, we observe that even without fine-tuning, large language models can outperform existing fine-tuned conversational recommendation models. (3) Analysis: We propose various probing tasks to investigate the mechanisms behind the remarkable performance of large language models in conversational recommendation. We analyze both the large language models' behaviors and the characteristics of the datasets, providing a holistic understanding of the models' effectiveness, limitations and suggesting directions for the design of future conversational recommenders
On the Regularization of Autoencoders
Oct 21, 2021
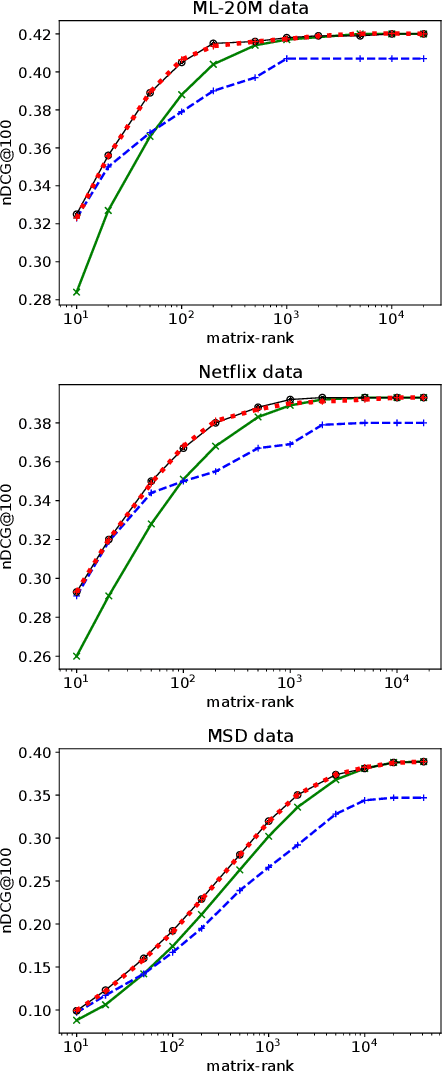
While much work has been devoted to understanding the implicit (and explicit) regularization of deep nonlinear networks in the supervised setting, this paper focuses on unsupervised learning, i.e., autoencoders are trained with the objective of reproducing the output from the input. We extend recent results [Jin et al. 2021] on unconstrained linear models and apply them to (1) nonlinear autoencoders and (2) constrained linear autoencoders, obtaining the following two results: first, we show that the unsupervised setting by itself induces strong additional regularization, i.e., a severe reduction in the model-capacity of the learned autoencoder: we derive that a deep nonlinear autoencoder cannot fit the training data more accurately than a linear autoencoder does if both models have the same dimensionality in their last hidden layer (and under a few additional assumptions). Our second contribution is concerned with the low-rank EDLAE model [Steck 2020], which is a linear autoencoder with a constraint on the diagonal of the learned low-rank parameter-matrix for improved generalization: we derive a closed-form approximation to the optimum of its non-convex training-objective, and empirically demonstrate that it is an accurate approximation across all model-ranks in our experiments on three well-known data sets.
Markov Random Fields for Collaborative Filtering
Oct 21, 2019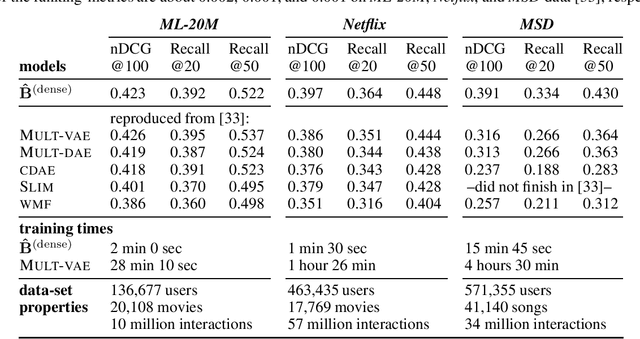
In this paper, we model the dependencies among the items that are recommended to a user in a collaborative-filtering problem via a Gaussian Markov Random Field (MRF). We build upon Besag's auto-normal parameterization and pseudo-likelihood, which not only enables computationally efficient learning, but also connects the areas of MRFs and sparse inverse covariance estimation with autoencoders and neighborhood models, two successful approaches in collaborative filtering. We propose a novel approximation for learning sparse MRFs, where the trade-off between recommendation-accuracy and training-time can be controlled. At only a small fraction of the training-time compared to various baselines, including deep nonlinear models, the proposed approach achieved competitive ranking-accuracy on all three well-known data-sets used in our experiments, and notably a 20% gain in accuracy on the data-set with the largest number of items.
* 9 pages
Embarrassingly Shallow Autoencoders for Sparse Data
May 08, 2019
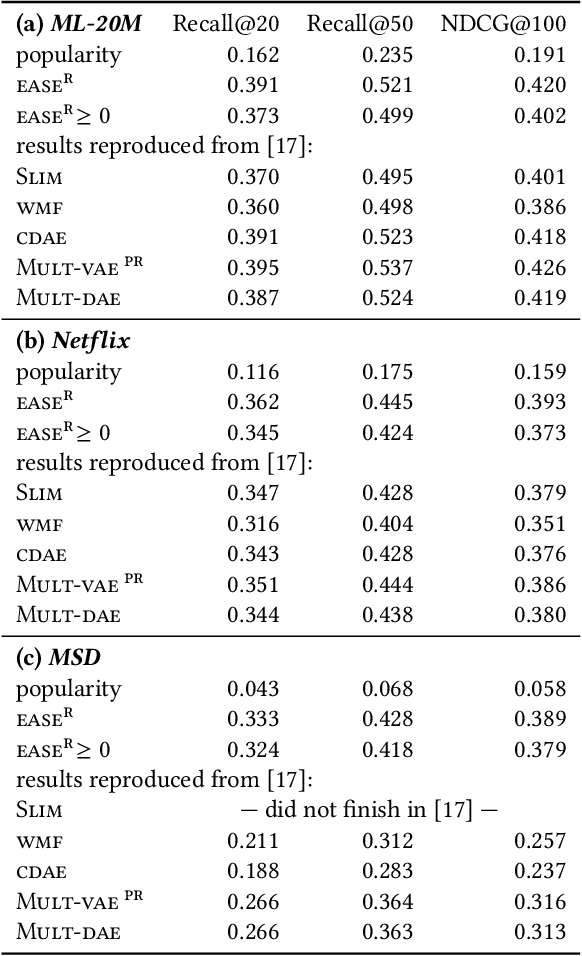
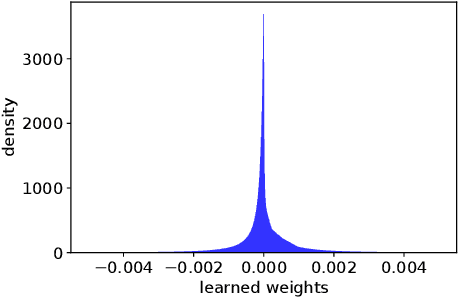

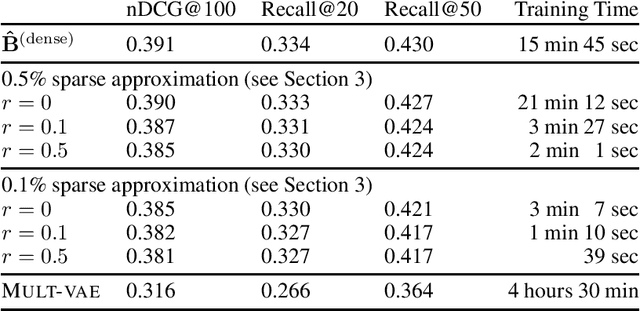
Combining simple elements from the literature, we define a linear model that is geared toward sparse data, in particular implicit feedback data for recommender systems. We show that its training objective has a closed-form solution, and discuss the resulting conceptual insights. Surprisingly, this simple model achieves better ranking accuracy than various state-of-the-art collaborative-filtering approaches, including deep non-linear models, on most of the publicly available data-sets used in our experiments.
Collaborative Filtering via High-Dimensional Regression
Apr 30, 2019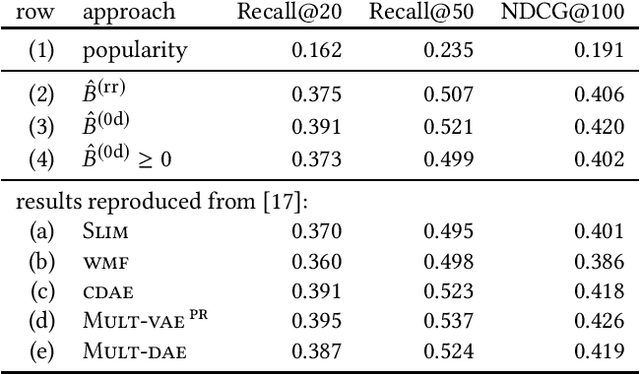
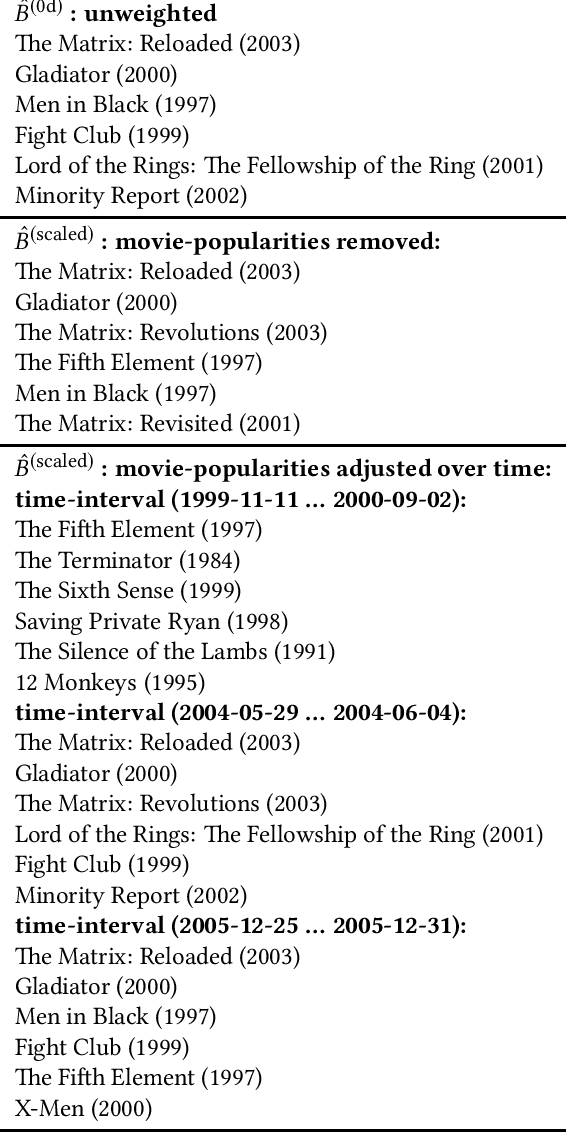
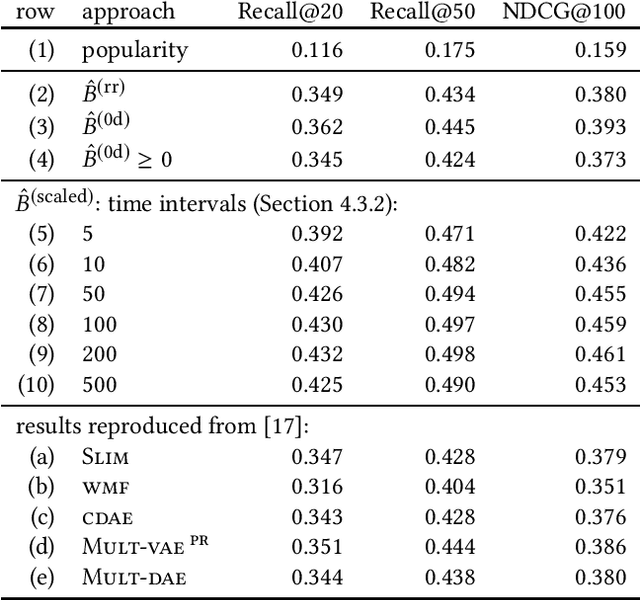
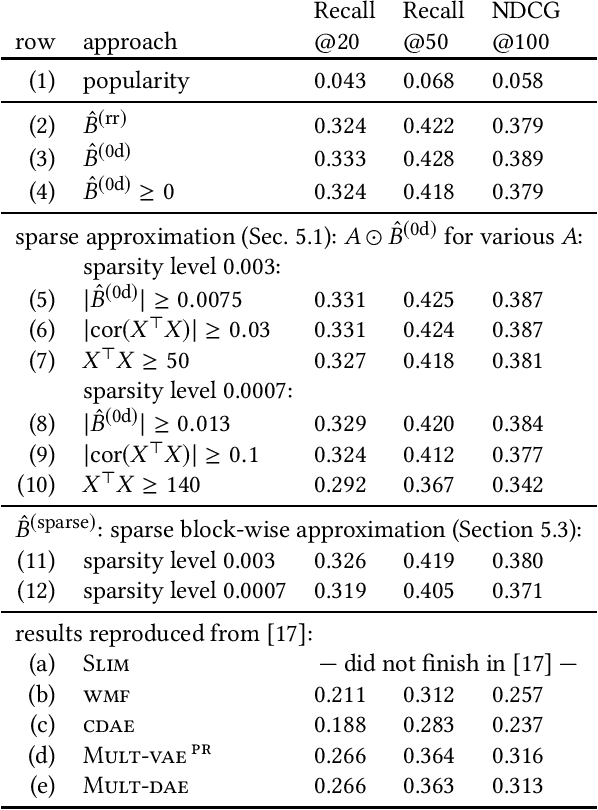
While the SLIM approach obtained high ranking-accuracy in many experiments in the literature, it is also known for its high computational cost of learning its parameters from data. For this reason, we focus in this paper on variants of high-dimensional regression problems that have closed-form solutions. Moreover, we motivate a re-scaling rather than a re-weighting approach for dealing with biases regarding item-popularities in the data. We also discuss properties of the sparse solution, and outline a computationally efficient approximation. In experiments on three publicly available data sets, we observed not only extremely reduced training times, but also significantly improved ranking accuracy compared to SLIM. Surprisingly, various state-of-the-art models, including deep non-linear autoencoders, were also outperformed on two of the three data sets in our experiments, in particular for recommendations with highly personalized relevance.
On the Use of Skeletons when Learning in Bayesian Networks
Jan 16, 2013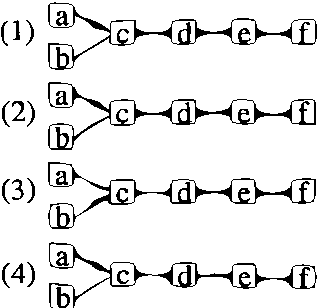

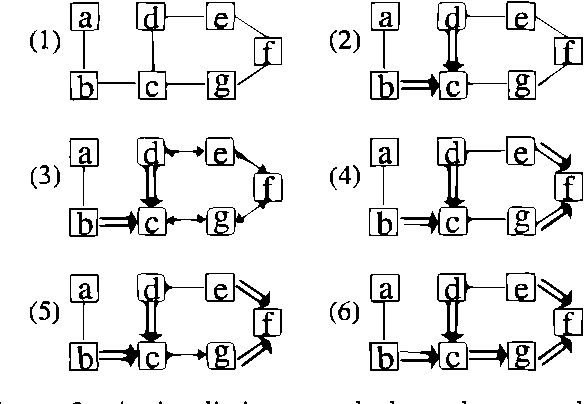
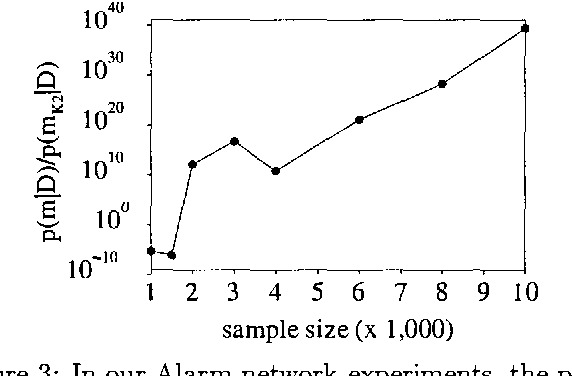
In this paper, we present a heuristic operator which aims at simultaneously optimizing the orientations of all the edges in an intermediate Bayesian network structure during the search process. This is done by alternating between the space of directed acyclic graphs (DAGs) and the space of skeletons. The found orientations of the edges are based on a scoring function rather than on induced conditional independences. This operator can be used as an extension to commonly employed search strategies. It is evaluated in experiments with artificial and real-world data.