 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Filtering via High-Dimensional Regression
Paper and Code
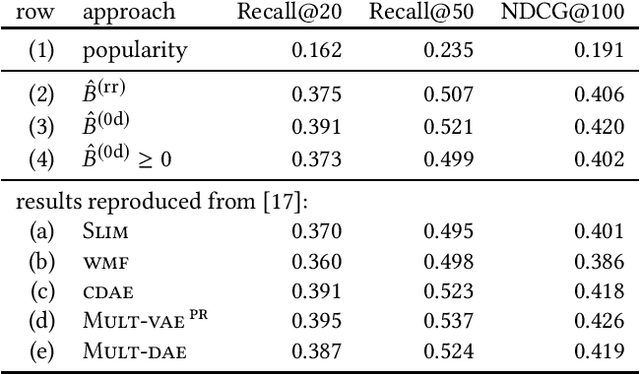
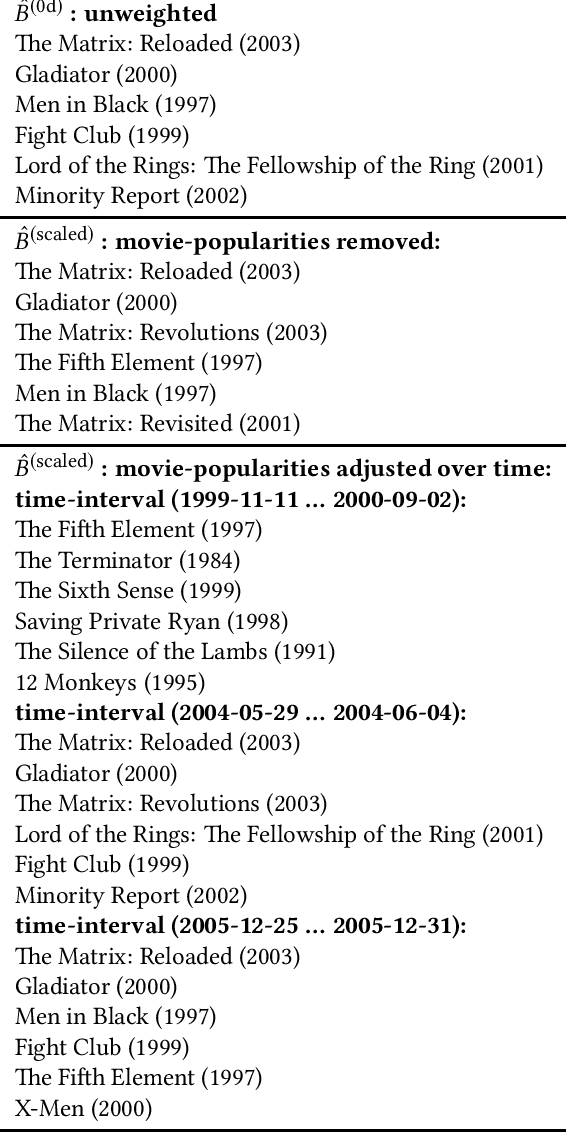
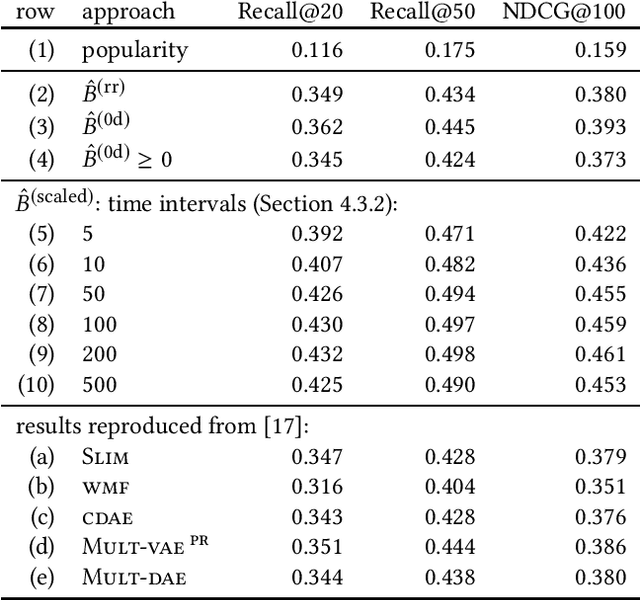
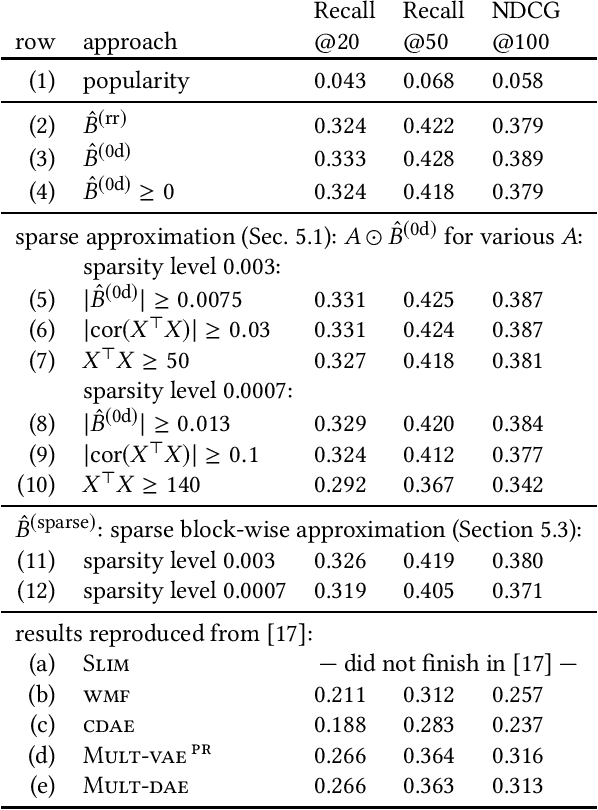
While the SLIM approach obtained high ranking-accuracy in many experiments in the literature, it is also known for its high computational cost of learning its parameters from data. For this reason, we focus in this paper on variants of high-dimensional regression problems that have closed-form solutions. Moreover, we motivate a re-scaling rather than a re-weighting approach for dealing with biases regarding item-popularities in the data. We also discuss properties of the sparse solution, and outline a computationally efficient approximation. In experiments on three publicly available data sets, we observed not only extremely reduced training times, but also significantly improved ranking accuracy compared to SLIM. Surprisingly, various state-of-the-art models, including deep non-linear autoencoders, were also outperformed on two of the three data sets in our experiments, in particular for recommendations with highly personalized relevance.