 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgenticTagger: Structured Item Representation for Recommendation with LLM Agents
Feb 05, 2026High-quality representations are a core requirement for effective recommendation. In this work, we study the problem of LLM-based descriptor generation, i.e., keyphrase-like natural language item representation generation frameworks with minimal constraints on downstream applications. We propose AgenticTagger, a framework that queries LLMs for representing items with sequences of text descriptors. However, open-ended generation provides little control over the generation space, leading to high cardinality, low-performance descriptors that renders downstream modeling challenging. To this end, AgenticTagger features two core stages: (1) a vocabulary building stage where a set of hierarchical, low-cardinality, and high-quality descriptors is identified, and (2) a vocabulary assignment stage where LLMs assign in-vocabulary descriptors to items. To effectively and efficiently ground vocabulary in the item corpus of interest, we design a multi-agent reflection mechanism where an architect LLM iteratively refines the vocabulary guided by parallelized feedback from annotator LLMs that validates the vocabulary against item data. Experiments on public and private data show AgenticTagger brings consistent improvements across diverse recommendation scenarios, including generative and term-based retrieval, ranking, and controllability-oriented, critique-based recommendation.
PACEvolve: Enabling Long-Horizon Progress-Aware Consistent Evolution
Jan 15, 2026Large Language Models (LLMs) have emerged as powerful operators for evolutionary search, yet the design of efficient search scaffolds remains ad hoc. While promising, current LLM-in-the-loop systems lack a systematic approach to managing the evolutionary process. We identify three distinct failure modes: Context Pollution, where experiment history biases future candidate generation; Mode Collapse, where agents stagnate in local minima due to poor exploration-exploitation balance; and Weak Collaboration, where rigid crossover strategies fail to leverage parallel search trajectories effectively. We introduce Progress-Aware Consistent Evolution (PACEvolve), a framework designed to robustly govern the agent's context and search dynamics, to address these challenges. PACEvolve combines hierarchical context management (HCM) with pruning to address context pollution; momentum-based backtracking (MBB) to escape local minima; and a self-adaptive sampling policy that unifies backtracking and crossover for dynamic search coordination (CE), allowing agents to balance internal refinement with cross-trajectory collaboration. We demonstrate that PACEvolve provides a systematic path to consistent, long-horizon self-improvement, achieving state-of-the-art results on LLM-SR and KernelBench, while discovering solutions surpassing the record on Modded NanoGPT.
LaViC: Adapting Large Vision-Language Models to Visually-Aware Conversational Recommendation
Mar 30, 2025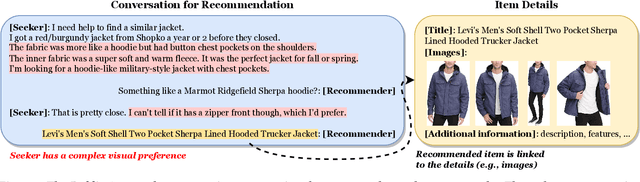
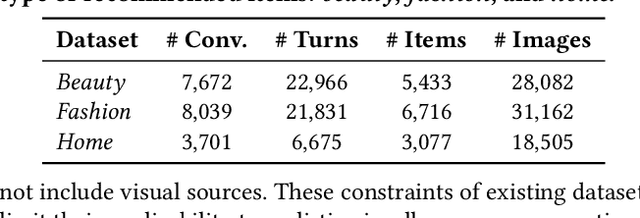
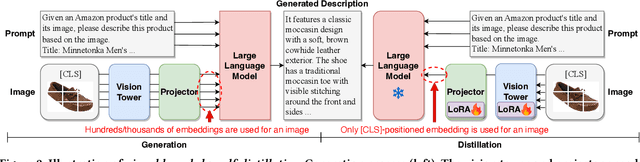
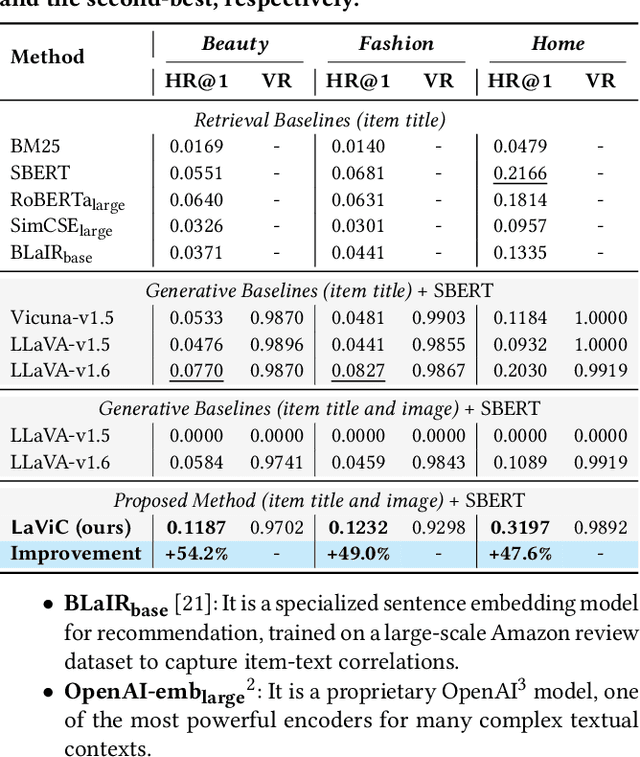
Conversational recommender systems engage users in dialogues to refine their needs and provide more personalized suggestions. Although textual information suffices for many domains, visually driven categories such as fashion or home decor potentially require detailed visual information related to color, style, or design. To address this challenge, we propose LaViC (Large Vision-Language Conversational Recommendation Framework), a novel approach that integrates compact image representations into dialogue-based recommendation systems. LaViC leverages a large vision-language model in a two-stage process: (1) visual knowledge self-distillation, which condenses product images from hundreds of tokens into a small set of visual tokens in a self-distillation manner, significantly reducing computational overhead, and (2) recommendation prompt tuning, which enables the model to incorporate both dialogue context and distilled visual tokens, providing a unified mechanism for capturing textual and visual features. To support rigorous evaluation of visually-aware conversational recommendation, we construct a new dataset by aligning Reddit conversations with Amazon product listings across multiple visually oriented categories (e.g., fashion, beauty, and home). This dataset covers realistic user queries and product appearances in domains where visual details are crucial. Extensive experiments demonstrate that LaViC significantly outperforms text-only conversational recommendation methods and open-source vision-language baselines. Moreover, LaViC achieves competitive or superior accuracy compared to prominent proprietary baselines (e.g., GPT-3.5-turbo, GPT-4o-mini, and GPT-4o), demonstrating the necessity of explicitly using visual data for capturing product attributes and showing the effectiveness of our vision-language integration. Our code and dataset are available at https://github.com/jeon185/LaViC.
ActionPiece: Contextually Tokenizing Action Sequences for Generative Recommendation
Feb 19, 2025Generative recommendation (GR) is an emerging paradigm where user actions are tokenized into discrete token patterns and autoregressively generated as predictions. However, existing GR models tokenize each action independently, assigning the same fixed tokens to identical actions across all sequences without considering contextual relationships. This lack of context-awareness can lead to suboptimal performance, as the same action may hold different meanings depending on its surrounding context. To address this issue, we propose ActionPiece to explicitly incorporate context when tokenizing action sequences. In ActionPiece, each action is represented as a set of item features, which serve as the initial tokens. Given the action sequence corpora, we construct the vocabulary by merging feature patterns as new tokens, based on their co-occurrence frequency both within individual sets and across adjacent sets. Considering the unordered nature of feature sets, we further introduce set permutation regularization, which produces multiple segmentations of action sequences with the same semantics. Experiments on public datasets demonstrate that ActionPiece consistently outperforms existing action tokenization methods, improving NDCG@$10$ by $6.00\%$ to $12.82\%$.
Multi-modal Generative Models in Recommendation System
Sep 17, 2024



Many recommendation systems limit user inputs to text strings or behavior signals such as clicks and purchases, and system outputs to a list of products sorted by relevance. With the advent of generative AI, users have come to expect richer levels of interactions. In visual search, for example, a user may provide a picture of their desired product along with a natural language modification of the content of the picture (e.g., a dress like the one shown in the picture but in red color). Moreover, users may want to better understand the recommendations they receive by visualizing how the product fits their use case, e.g., with a representation of how a garment might look on them, or how a furniture item might look in their room. Such advanced levels of interaction require recommendation systems that are able to discover both shared and complementary information about the product across modalities, and visualize the product in a realistic and informative way. However, existing systems often treat multiple modalities independently: text search is usually done by comparing the user query to product titles and descriptions, while visual search is typically done by comparing an image provided by the customer to product images. We argue that future recommendation systems will benefit from a multi-modal understanding of the products that leverages the rich information retailers have about both customers and products to come up with the best recommendations. In this chapter we review recommendation systems that use multiple data modalities simultaneously.
Large Language Model Driven Recommendation
Aug 20, 2024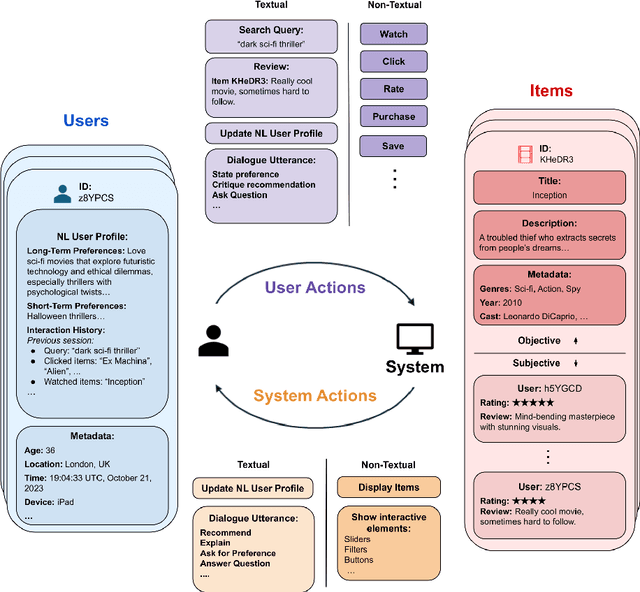
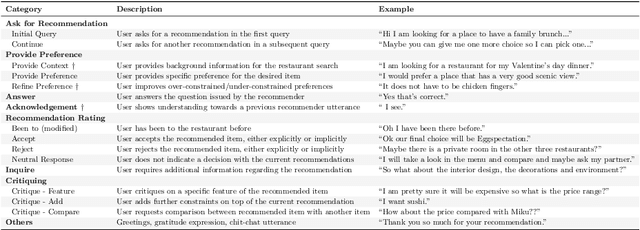
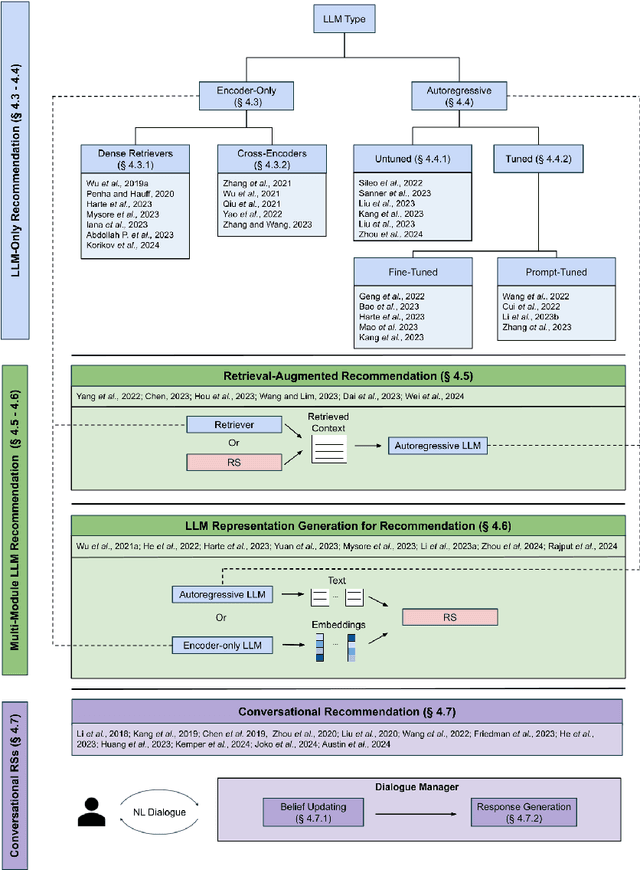

While previous chapters focused on recommendation systems (RSs) based on standardized, non-verbal user feedback such as purchases, views, and clicks -- the advent of LLMs has unlocked the use of natural language (NL) interactions for recommendation. This chapter discusses how LLMs' abilities for general NL reasoning present novel opportunities to build highly personalized RSs -- which can effectively connect nuanced and diverse user preferences to items, potentially via interactive dialogues. To begin this discussion, we first present a taxonomy of the key data sources for language-driven recommendation, covering item descriptions, user-system interactions, and user profiles. We then proceed to fundamental techniques for LLM recommendation, reviewing the use of encoder-only and autoregressive LLM recommendation in both tuned and untuned settings. Afterwards, we move to multi-module recommendation architectures in which LLMs interact with components such as retrievers and RSs in multi-stage pipelines. This brings us to architectures for conversational recommender systems (CRSs), in which LLMs facilitate multi-turn dialogues where each turn presents an opportunity not only to make recommendations, but also to engage with the user in interactive preference elicitation, critiquing, and question-answering.
Auto-Encoding or Auto-Regression? A Reality Check on Causality of Self-Attention-Based Sequential Recommenders
Jun 04, 2024

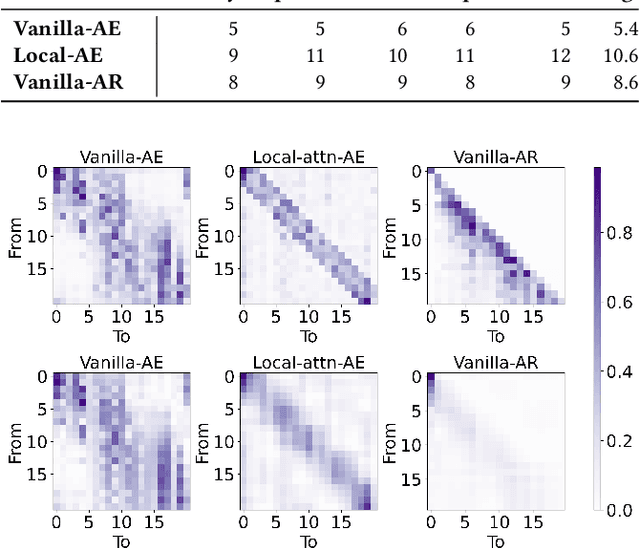

The comparison between Auto-Encoding (AE) and Auto-Regression (AR) has become an increasingly important topic with recent advances in sequential recommendation. At the heart of this discussion lies the comparison of BERT4Rec and SASRec, which serve as representative AE and AR models for self-attentive sequential recommenders. Yet the conclusion of this debate remains uncertain due to: (1) the lack of fair and controlled environments for experiments and evaluations; and (2) the presence of numerous confounding factors w.r.t. feature selection, modeling choices and optimization algorithms. In this work, we aim to answer this question by conducting a series of controlled experiments. We start by tracing the AE/AR debate back to its origin through a systematic re-evaluation of SASRec and BERT4Rec, discovering that AR models generally surpass AE models in sequential recommendation. In addition, we find that AR models further outperforms AE models when using a customized design space that includes additional features, modeling approaches and optimization techniques. Furthermore, the performance advantage of AR models persists in the broader HuggingFace transformer ecosystems. Lastly, we provide potential explanations and insights into AE/AR performance from two key perspectives: low-rank approximation and inductive bias. We make our code and data available at https://github.com/yueqirex/ModSAR
Reindex-Then-Adapt: Improving Large Language Models for Conversational Recommendation
May 20, 2024Large language models (LLMs) are revolutionizing conversational recommender systems by adeptly indexing item content, understanding complex conversational contexts, and generating relevant item titles. However, controlling the distribution of recommended items remains a challenge. This leads to suboptimal performance due to the failure to capture rapidly changing data distributions, such as item popularity, on targeted conversational recommendation platforms. In conversational recommendation, LLMs recommend items by generating the titles (as multiple tokens) autoregressively, making it difficult to obtain and control the recommendations over all items. Thus, we propose a Reindex-Then-Adapt (RTA) framework, which converts multi-token item titles into single tokens within LLMs, and then adjusts the probability distributions over these single-token item titles accordingly. The RTA framework marries the benefits of both LLMs and traditional recommender systems (RecSys): understanding complex queries as LLMs do; while efficiently controlling the recommended item distributions in conversational recommendations as traditional RecSys do. Our framework demonstrates improved accuracy metrics across three different conversational recommendation datasets and two adaptation settings
A Review of Modern Recommender Systems Using Generative Models
Mar 31, 2024

Traditional recommender systems (RS) have used user-item rating histories as their primary data source, with collaborative filtering being one of the principal methods. However, generative models have recently developed abilities to model and sample from complex data distributions, including not only user-item interaction histories but also text, images, and videos - unlocking this rich data for novel recommendation tasks. Through this comprehensive and multi-disciplinary survey, we aim to connect the key advancements in RS using Generative Models (Gen-RecSys), encompassing: a foundational overview of interaction-driven generative models; the application of large language models (LLM) for generative recommendation, retrieval, and conversational recommendation; and the integration of multimodal models for processing and generating image and video content in RS. Our holistic perspective allows us to highlight necessary paradigms for evaluating the impact and harm of Gen-RecSys and identify open challenges. A more up-to-date version of the papers is maintained at: https://github.com/yasdel/LLM-RecSys.
Evaluating Large Language Models as Generative User Simulators for Conversational Recommendation
Mar 25, 2024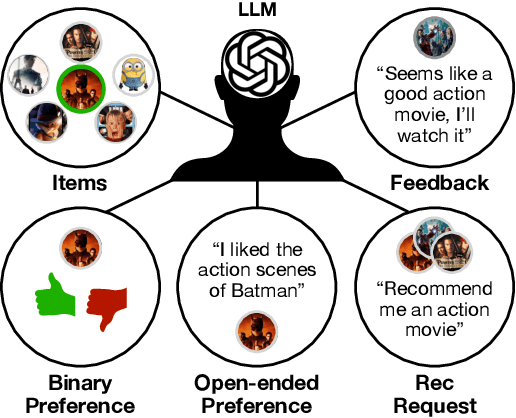
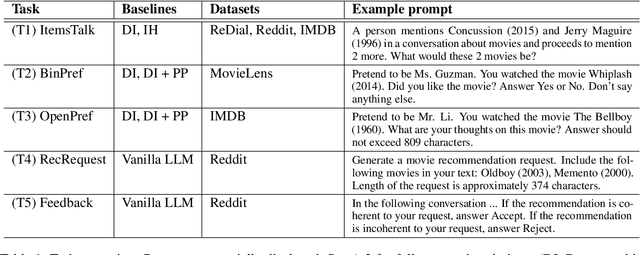
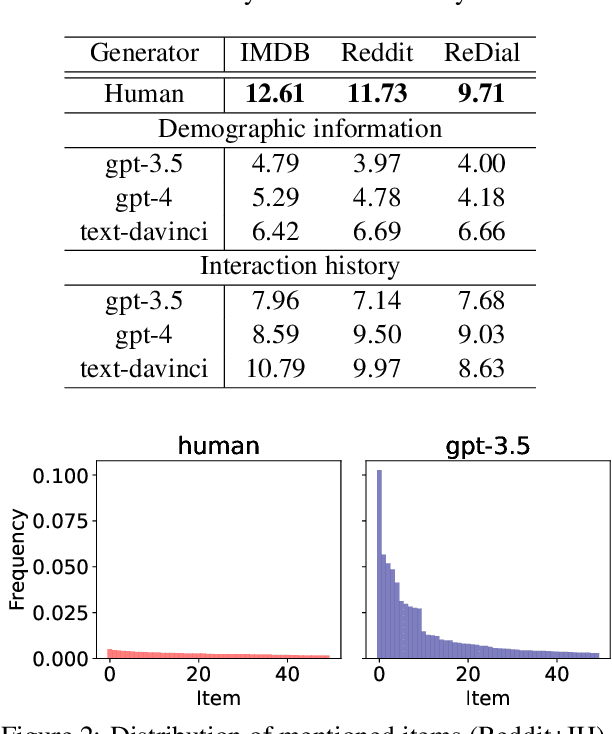
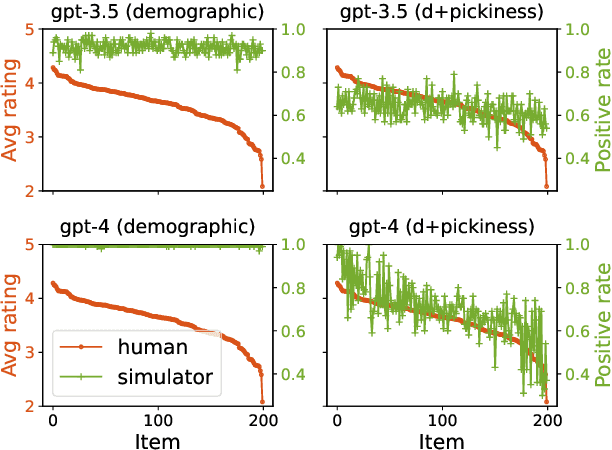
Synthetic users are cost-effective proxies for real users in the evaluation of conversational recommender systems. Large language models show promise in simulating human-like behavior, raising the question of their ability to represent a diverse population of users. We introduce a new protocol to measure the degree to which language models can accurately emulate human behavior in conversational recommendation. This protocol is comprised of five tasks, each designed to evaluate a key property that a synthetic user should exhibit: choosing which items to talk about, expressing binary preferences, expressing open-ended preferences, requesting recommendations, and giving feedback. Through evaluation of baseline simulators, we demonstrate these tasks effectively reveal deviations of language models from human behavior, and offer insights on how to reduce the deviations with model selection and prompting strategies.