 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaViC: Adapting Large Vision-Language Models to Visually-Aware Conversational Recommendation
Mar 30, 2025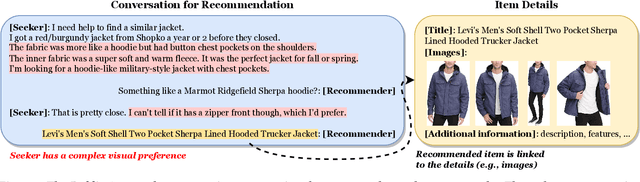
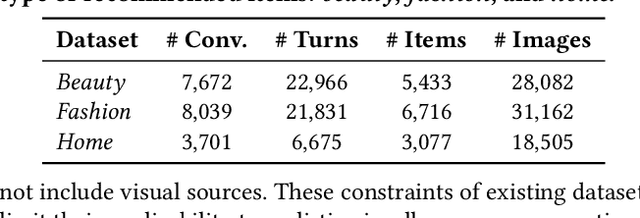
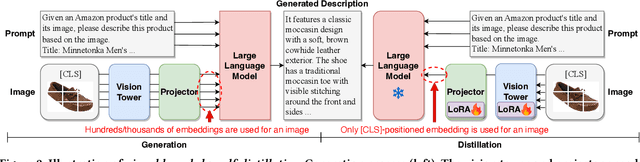
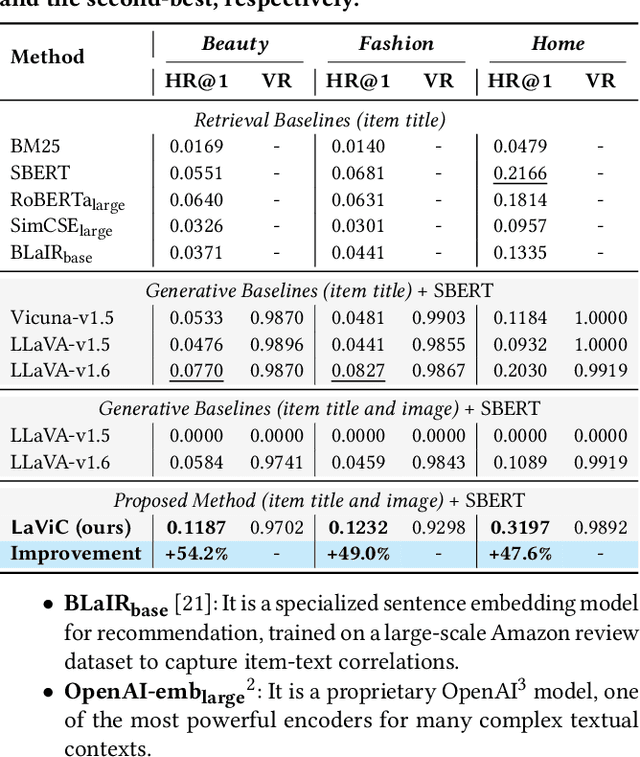
Conversational recommender systems engage users in dialogues to refine their needs and provide more personalized suggestions. Although textual information suffices for many domains, visually driven categories such as fashion or home decor potentially require detailed visual information related to color, style, or design. To address this challenge, we propose LaViC (Large Vision-Language Conversational Recommendation Framework), a novel approach that integrates compact image representations into dialogue-based recommendation systems. LaViC leverages a large vision-language model in a two-stage process: (1) visual knowledge self-distillation, which condenses product images from hundreds of tokens into a small set of visual tokens in a self-distillation manner, significantly reducing computational overhead, and (2) recommendation prompt tuning, which enables the model to incorporate both dialogue context and distilled visual tokens, providing a unified mechanism for capturing textual and visual features. To support rigorous evaluation of visually-aware conversational recommendation, we construct a new dataset by aligning Reddit conversations with Amazon product listings across multiple visually oriented categories (e.g., fashion, beauty, and home). This dataset covers realistic user queries and product appearances in domains where visual details are crucial. Extensive experiments demonstrate that LaViC significantly outperforms text-only conversational recommendation methods and open-source vision-language baselines. Moreover, LaViC achieves competitive or superior accuracy compared to prominent proprietary baselines (e.g., GPT-3.5-turbo, GPT-4o-mini, and GPT-4o), demonstrating the necessity of explicitly using visual data for capturing product attributes and showing the effectiveness of our vision-language integration. Our code and dataset are available at https://github.com/jeon185/LaViC.
Calibration-Disentangled Learning and Relevance-Prioritized Reranking for Calibrated Sequential Recommendation
Aug 04, 2024Calibrated recommendation, which aims to maintain personalized proportions of categories within recommendations, is crucial in practical scenarios since it enhances user satisfaction by reflecting diverse interests. However, achieving calibration in a sequential setting (i.e., calibrated sequential recommendation) is challenging due to the need to adapt to users' evolving preferences. Previous methods typically leverage reranking algorithms to calibrate recommendations after training a model without considering the effect of calibration and do not effectively tackle the conflict between relevance and calibration during the reranking process. In this work, we propose LeapRec (Calibration-Disentangled Learning and Relevance-Prioritized Reranking), a novel approach for the calibrated sequential recommendation that addresses these challenges. LeapRec consists of two phases, model training phase and reranking phase. In the training phase, a backbone model is trained using our proposed calibration-disentangled learning-to-rank loss, which optimizes personalized rankings while integrating calibration considerations. In the reranking phase, relevant items are prioritized at the top of the list, with items needed for calibration following later to address potential conflicts between relevance and calibration. Through extensive experiments on four real-world datasets, we show that LeapRec consistently outperforms previous methods in the calibrated sequential recommendation. Our code is available at https://github.com/jeon185/LeapRec.
Imagery as Inquiry: Exploring A Multimodal Dataset for Conversational Recommendation
May 23, 2024We introduce a multimodal dataset where users express preferences through images. These images encompass a broad spectrum of visual expressions ranging from landscapes to artistic depictions. Users request recommendations for books or music that evoke similar feelings to those captured in the images, and recommendations are endorsed by the community through upvotes. This dataset supports two recommendation tasks: title generation and multiple-choice selection. Our experiments with large foundation models reveal their limitations in these tasks. Particularly, vision-language models show no significant advantage over language-only counterparts that use descriptions, which we hypothesize is due to underutilized visual capabilities. To better harness these abilities, we propose the chain-of-imagery prompting, which results in notable improvements. We release our code and datasets.
Accurate Cold-start Bundle Recommendation via Popularity-based Coalescence and Curriculum Heating
Oct 09, 2023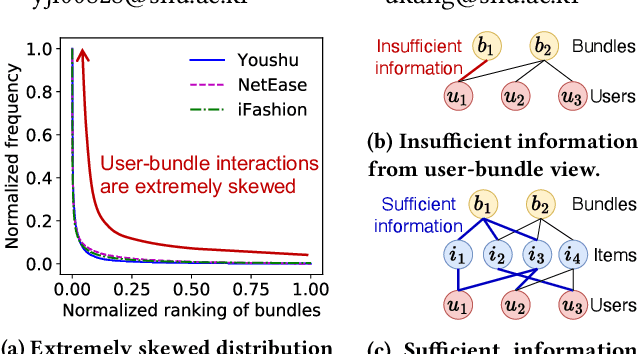



How can we accurately recommend cold-start bundles to users? The cold-start problem in bundle recommendation is critical in practical scenarios since new bundles are continuously created for various marketing purposes. Despite its importance, no previous studies have addressed cold-start bundle recommendation. Moreover, existing methods for cold-start item recommendation overly rely on historical information, even for unpopular bundles, failing to tackle the primary challenge of the highly skewed distribution of bundle interactions. In this work, we propose CoHeat (Popularity-based Coalescence and Curriculum Heating), an accurate approach for the cold-start bundle recommendation. CoHeat tackles the highly skewed distribution of bundle interactions by incorporating both historical and affiliation information based on the bundle's popularity when estimating the user-bundle relationship. Furthermore, CoHeat effectively learns latent representations by exploiting curriculum learning and contrastive learning. CoHeat demonstrates superior performance in cold-start bundle recommendation, achieving up to 193% higher nDCG@20 compared to the best competitor.
Accurate Action Recommendation for Smart Home via Two-Level Encoders and Commonsense Knowledge
Aug 12, 2022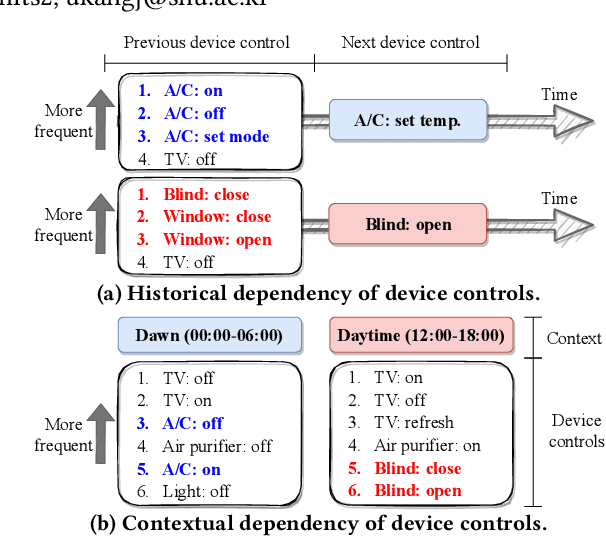
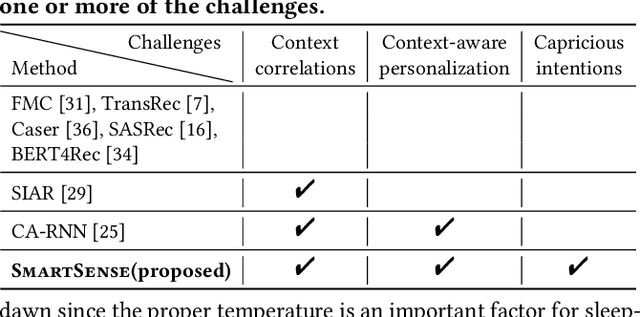
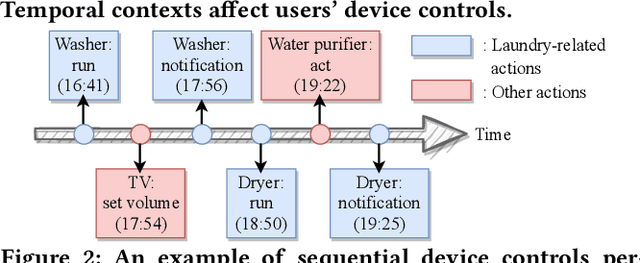
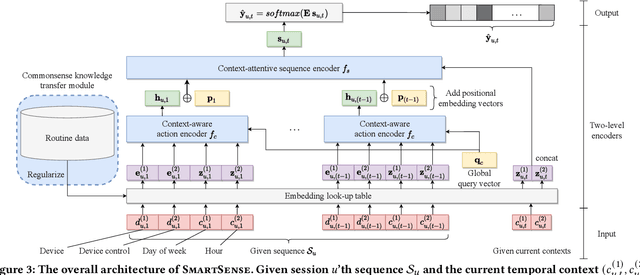
How can we accurately recommend actions for users to control their devices at home? Action recommendation for smart home has attracted increasing attention due to its potential impact on the markets of virtual assistants and Internet of Things (IoT). However, designing an effective action recommender system for smart home is challenging because it requires handling context correlations, considering both queried contexts and previous histories of users, and dealing with capricious intentions in history. In this work, we propose SmartSense, an accurate action recommendation method for smart home. For individual action, SmartSense summarizes its device control and its temporal contexts in a self-attentive manner, to reflect the importance of the correlation between them. SmartSense then summarizes sequences of users considering queried contexts in a query-attentive manner to extract the query-related patterns from the sequential actions. SmartSense also transfers the commonsense knowledge from routine data to better handle intentions in action sequences. As a result, SmartSense addresses all three main challenges of action recommendation for smart home, and achieves the state-of-the-art performance giving up to 9.8% higher mAP@1 than the best competitor.
Accurate Node Feature Estimation with Structured Variational Graph Autoencoder
Jun 09, 2022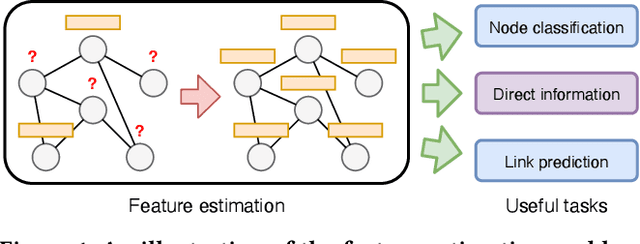
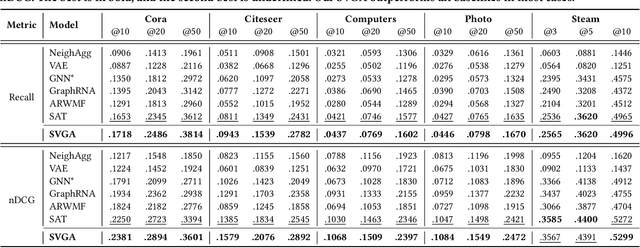
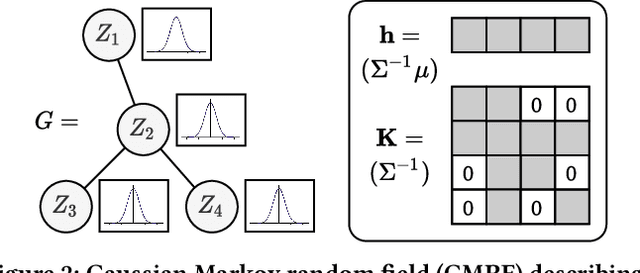
Given a graph with partial observations of node features, how can we estimate the missing features accurately? Feature estimation is a crucial problem for analyzing real-world graphs whose features are commonly missing during the data collection process. Accurate estimation not only provides diverse information of nodes but also supports the inference of graph neural networks that require the full observation of node features. However, designing an effective approach for estimating high-dimensional features is challenging, since it requires an estimator to have large representation power, increasing the risk of overfitting. In this work, we propose SVGA (Structured Variational Graph Autoencoder), an accurate method for feature estimation. SVGA applies strong regularization to the distribution of latent variables by structured variational inference, which models the prior of variables as Gaussian Markov random field based on the graph structure. As a result, SVGA combines the advantages of probabilistic inference and graph neural networks, achieving state-of-the-art performance in real datasets.
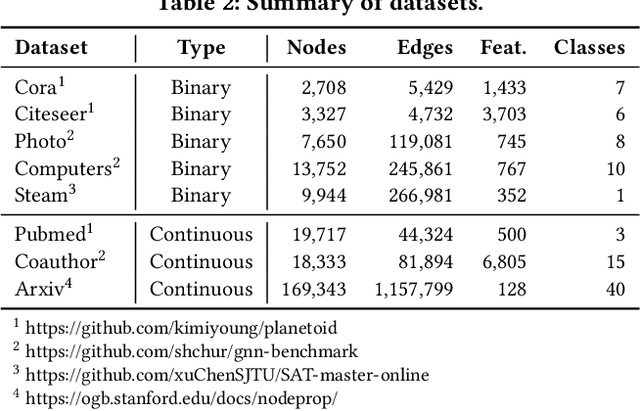
Ensemble Multi-Source Domain Adaptation with Pseudolabels
Sep 29, 2020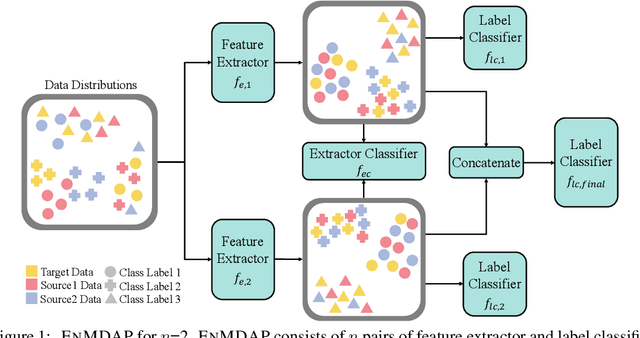
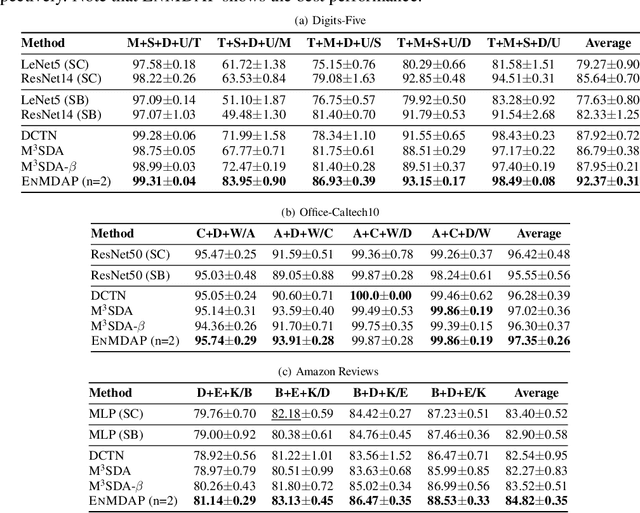
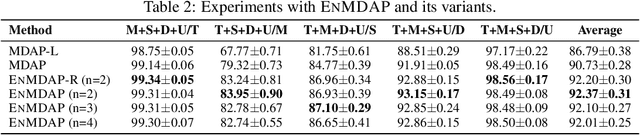
Given multiple source datasets with labels, how can we train a target model with no labeled data? Multi-source domain adaptation (MSDA) aims to train a model using multiple source datasets different from a target dataset in the absence of target data labels. MSDA is a crucial problem applicable to many practical cases where labels for the target data are unavailable due to privacy issues. Existing MSDA frameworks are limited since they align data without considering conditional distributions p(x|y) of each domain. They also miss a lot of target label information by not considering the target label at all and relying on only one feature extractor. In this paper, we propose Ensemble Multi-source Domain Adaptation with Pseudolabels (EnMDAP), a novel method for multi-source domain adaptation. EnMDAP exploits label-wise moment matching to align conditional distributions p(x|y), using pseudolabels for the unavailable target labels, and introduces ensemble learning theme by using multiple feature extractors for accurate domain adaptation. Extensive experiments show that EnMDAP provides the state-of-the-art performance for multi-source domain adaptation tasks in both of image domains and text domains.
Data Context Adaptation for Accurate Recommendation with Additional Information
Aug 22, 2019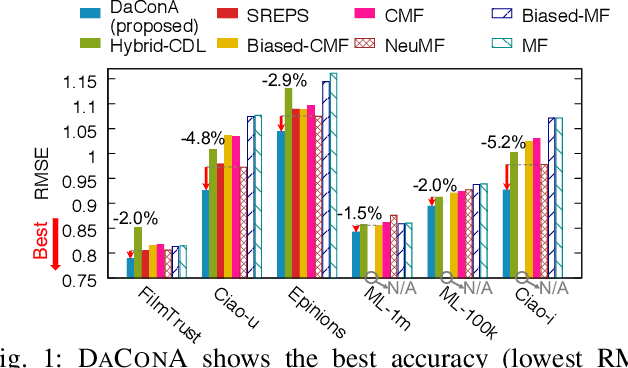
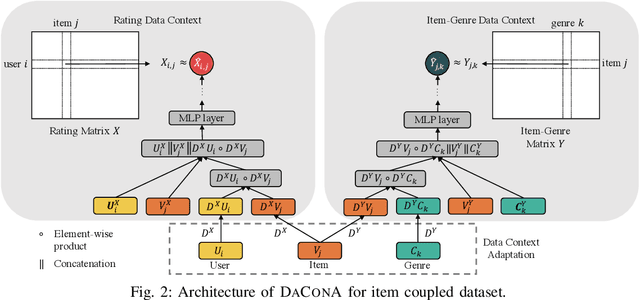
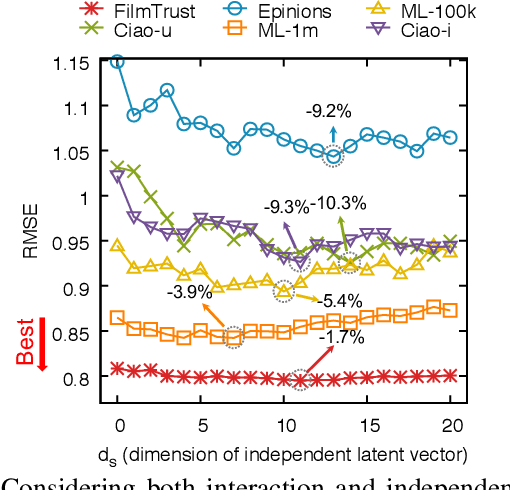
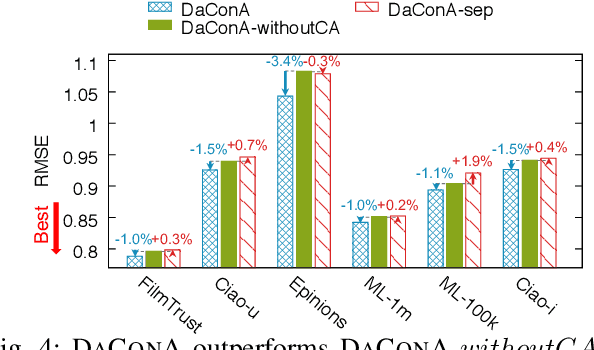
Given a sparse rating matrix and an auxiliary matrix of users or items, how can we accurately predict missing ratings considering different data contexts of entities? Many previous studies proved that utilizing the additional information with rating data is helpful to improve the performance. However, existing methods are limited in that 1) they ignore the fact that data contexts of rating and auxiliary matrices are different, 2) they have restricted capability of expressing independence information of users or items, and 3) they assume the relation between a user and an item is linear. We propose DaConA, a neural network based method for recommendation with a rating matrix and an auxiliary matrix. DaConA is designed with the following three main ideas. First, we propose a data context adaptation layer to extract pertinent features for different data contexts. Second, DaConA represents each entity with latent interaction vector and latent independence vector. Unlike previous methods, both of the two vectors are not limited in size. Lastly, while previous matrix factorization based methods predict missing values through the inner-product of latent vectors, DaConA learns a non-linear function of them via a neural network. We show that DaConA is a generalized algorithm including the standard matrix factorization and the collective matrix factorization as special cases. Through comprehensive experiments on real-world datasets, we show that DaConA provides the state-of-the-art accuracy.