 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMATCHA: Can Multi-Agent Collaboration Build a Trustworthy Conversational Recommender?
Apr 26, 2025



In this paper, we propose a multi-agent collaboration framework called MATCHA for conversational recommendation system, leveraging large language models (LLMs) to enhance personalization and user engagement. Users can request recommendations via free-form text and receive curated lists aligned with their interests, preferences, and constraints. Our system introduces specialized agents for intent analysis, candidate generation, ranking, re-ranking, explainability, and safeguards. These agents collaboratively improve recommendations accuracy, diversity, and safety. On eight metrics, our model achieves superior or comparable performance to the current state-of-the-art. Through comparisons with six baseline models, our approach addresses key challenges in conversational recommendation systems for game recommendations, including: (1) handling complex, user-specific requests, (2) enhancing personalization through multi-agent collaboration, (3) empirical evaluation and deployment, and (4) ensuring safe and trustworthy interactions.
OMuleT: Orchestrating Multiple Tools for Practicable Conversational Recommendation
Nov 28, 2024



In this paper, we present a systematic effort to design, evaluate, and implement a realistic conversational recommender system (CRS). The objective of our system is to allow users to input free-form text to request recommendations, and then receive a list of relevant and diverse items. While previous work on synthetic queries augments large language models (LLMs) with 1-3 tools, we argue that a more extensive toolbox is necessary to effectively handle real user requests. As such, we propose a novel approach that equips LLMs with over 10 tools, providing them access to the internal knowledge base and API calls used in production. We evaluate our model on a dataset of real users and show that it generates relevant, novel, and diverse recommendations compared to vanilla LLMs. Furthermore, we conduct ablation studies to demonstrate the effectiveness of using the full range of tools in our toolbox. We share our designs and lessons learned from deploying the system for internal alpha release. Our contribution is the addressing of all four key aspects of a practicable CRS: (1) real user requests, (2) augmenting LLMs with a wide variety of tools, (3) extensive evaluation, and (4) deployment insights.
Forecasting Live Chat Intent from Browsing History
Aug 07, 2024Customers reach out to online live chat agents with various intents, such as asking about product details or requesting a return. In this paper, we propose the problem of predicting user intent from browsing history and address it through a two-stage approach. The first stage classifies a user's browsing history into high-level intent categories. Here, we represent each browsing history as a text sequence of page attributes and use the ground-truth class labels to fine-tune pretrained Transformers. The second stage provides a large language model (LLM) with the browsing history and predicted intent class to generate fine-grained intents. For automatic evaluation, we use a separate LLM to judge the similarity between generated and ground-truth intents, which closely aligns with human judgments. Our two-stage approach yields significant performance gains compared to generating intents without the classification stage.
Calibration-Disentangled Learning and Relevance-Prioritized Reranking for Calibrated Sequential Recommendation
Aug 04, 2024Calibrated recommendation, which aims to maintain personalized proportions of categories within recommendations, is crucial in practical scenarios since it enhances user satisfaction by reflecting diverse interests. However, achieving calibration in a sequential setting (i.e., calibrated sequential recommendation) is challenging due to the need to adapt to users' evolving preferences. Previous methods typically leverage reranking algorithms to calibrate recommendations after training a model without considering the effect of calibration and do not effectively tackle the conflict between relevance and calibration during the reranking process. In this work, we propose LeapRec (Calibration-Disentangled Learning and Relevance-Prioritized Reranking), a novel approach for the calibrated sequential recommendation that addresses these challenges. LeapRec consists of two phases, model training phase and reranking phase. In the training phase, a backbone model is trained using our proposed calibration-disentangled learning-to-rank loss, which optimizes personalized rankings while integrating calibration considerations. In the reranking phase, relevant items are prioritized at the top of the list, with items needed for calibration following later to address potential conflicts between relevance and calibration. Through extensive experiments on four real-world datasets, we show that LeapRec consistently outperforms previous methods in the calibrated sequential recommendation. Our code is available at https://github.com/jeon185/LeapRec.
Imagery as Inquiry: Exploring A Multimodal Dataset for Conversational Recommendation
May 23, 2024We introduce a multimodal dataset where users express preferences through images. These images encompass a broad spectrum of visual expressions ranging from landscapes to artistic depictions. Users request recommendations for books or music that evoke similar feelings to those captured in the images, and recommendations are endorsed by the community through upvotes. This dataset supports two recommendation tasks: title generation and multiple-choice selection. Our experiments with large foundation models reveal their limitations in these tasks. Particularly, vision-language models show no significant advantage over language-only counterparts that use descriptions, which we hypothesize is due to underutilized visual capabilities. To better harness these abilities, we propose the chain-of-imagery prompting, which results in notable improvements. We release our code and datasets.
Evaluating Large Language Models as Generative User Simulators for Conversational Recommendation
Mar 25, 2024
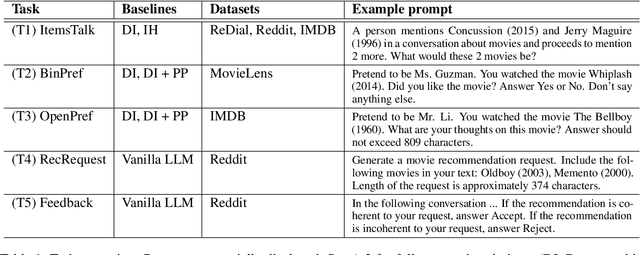
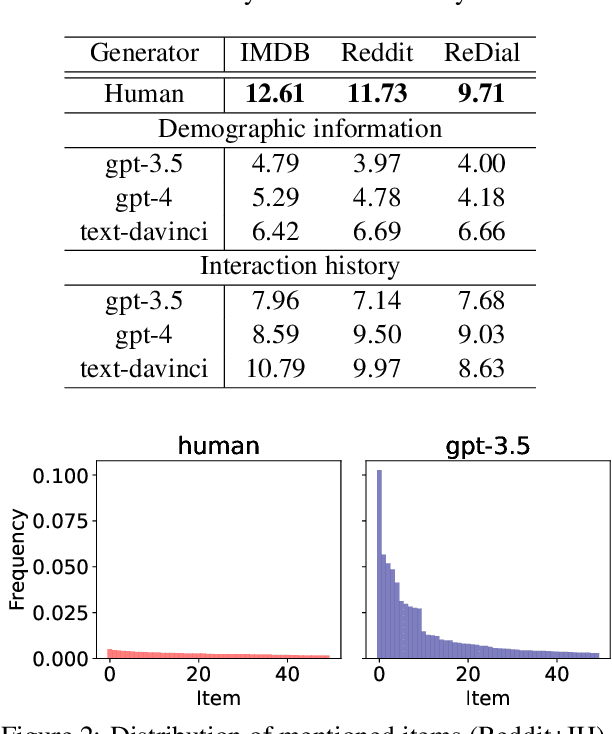
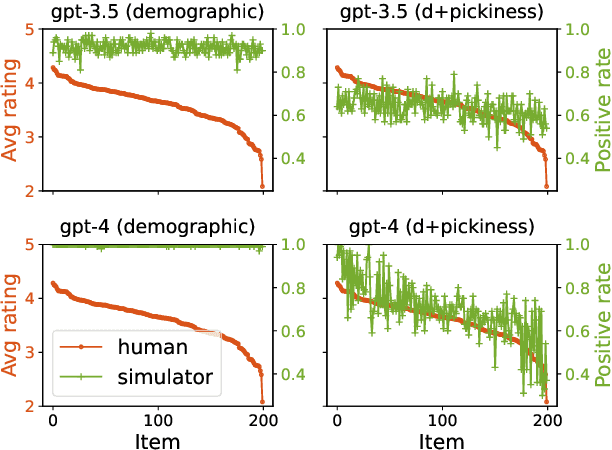
Synthetic users are cost-effective proxies for real users in the evaluation of conversational recommender systems. Large language models show promise in simulating human-like behavior, raising the question of their ability to represent a diverse population of users. We introduce a new protocol to measure the degree to which language models can accurately emulate human behavior in conversational recommendation. This protocol is comprised of five tasks, each designed to evaluate a key property that a synthetic user should exhibit: choosing which items to talk about, expressing binary preferences, expressing open-ended preferences, requesting recommendations, and giving feedback. Through evaluation of baseline simulators, we demonstrate these tasks effectively reveal deviations of language models from human behavior, and offer insights on how to reduce the deviations with model selection and prompting strategies.
How Much and When Do We Need Higher-order Information in Hypergraphs? A Case Study on Hyperedge Prediction
Jan 31, 2020
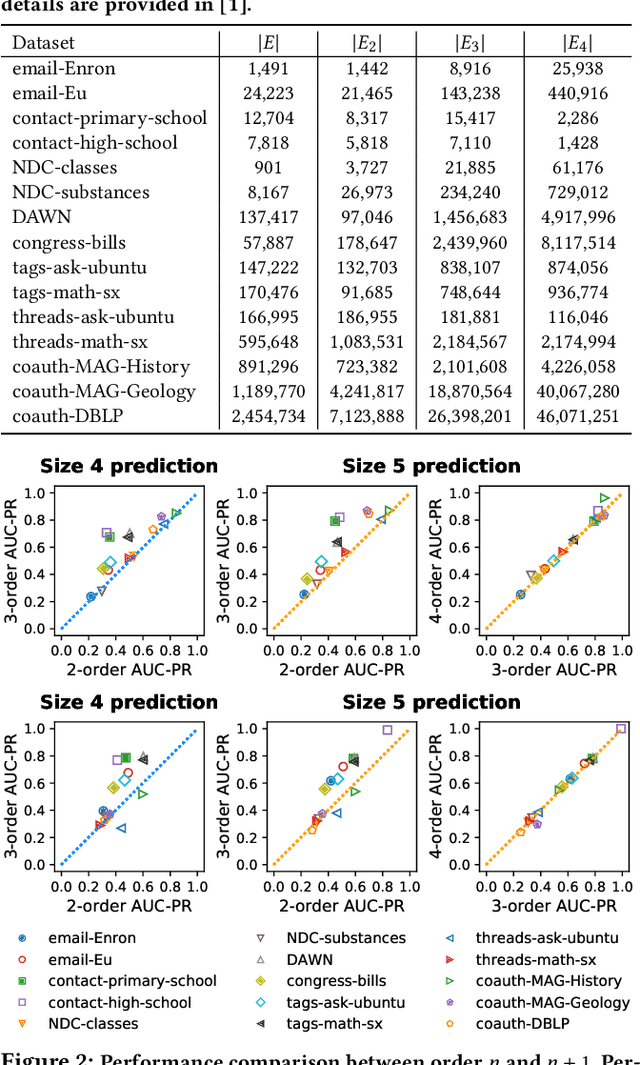

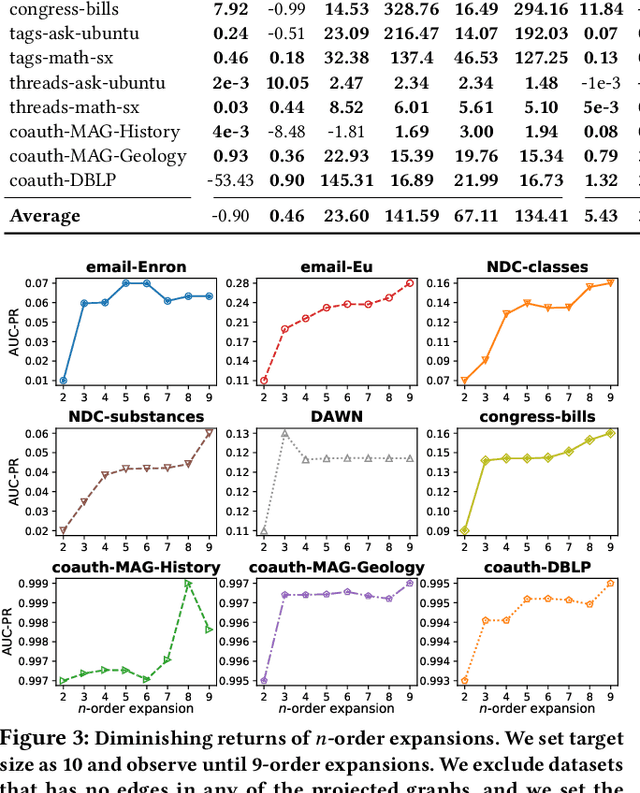
Hypergraphs provide a natural way of representing group relations, whose complexity motivates an extensive array of prior work to adopt some form of abstraction and simplification of higher-order interactions. However, the following question has yet to be addressed: How much abstraction of group interactions is sufficient in solving a hypergraph task, and how different such results become across datasets? This question, if properly answered, provides a useful engineering guideline on how to trade off between complexity and accuracy of solving a downstream task. To this end, we propose a method of incrementally representing group interactions using a notion of n-projected graph whose accumulation contains information on up to n-way interactions, and quantify the accuracy of solving a task as n grows for various datasets. As a downstream task, we consider hyperedge prediction, an extension of link prediction, which is a canonical task for evaluating graph models. Through experiments on 15 real-world datasets, we draw the following messages: (a) Diminishing returns: small n is enough to achieve accuracy comparable with near-perfect approximations, (b) Troubleshooter: as the task becomes more challenging, larger n brings more benefit, and (c) Irreducibility: datasets whose pairwise interactions do not tell much about higher-order interactions lose much accuracy when reduced to pairwise abstractions.
Solving Continual Combinatorial Selection via Deep Reinforcement Learning
Sep 09, 2019

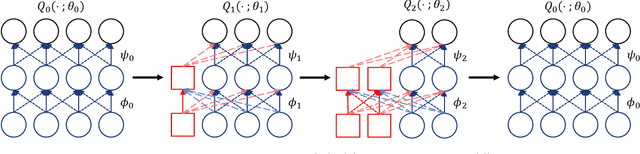
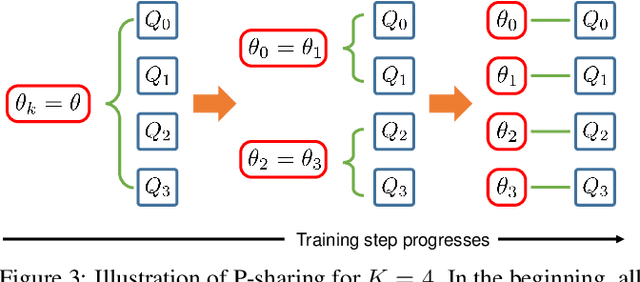
We consider the Markov Decision Process (MDP) of selecting a subset of items at each step, termed the Select-MDP (S-MDP). The large state and action spaces of S-MDPs make them intractable to solve with typical reinforcement learning (RL) algorithms especially when the number of items is huge. In this paper, we present a deep RL algorithm to solve this issue by adopting the following key ideas. First, we convert the original S-MDP into an Iterative Select-MDP (IS-MDP), which is equivalent to the S-MDP in terms of optimal actions. IS-MDP decomposes a joint action of selecting K items simultaneously into K iterative selections resulting in the decrease of actions at the expense of an exponential increase of states. Second, we overcome this state space explo-sion by exploiting a special symmetry in IS-MDPs with novel weight shared Q-networks, which prov-ably maintain sufficient expressive power. Various experiments demonstrate that our approach works well even when the item space is large and that it scales to environments with item spaces different from those used in training.
* Accepted to IJCAI 2019,14 pages,8 figures