 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Continual Combinatorial Selection via Deep Reinforcement Learning
Paper and Code
Sep 09, 2019

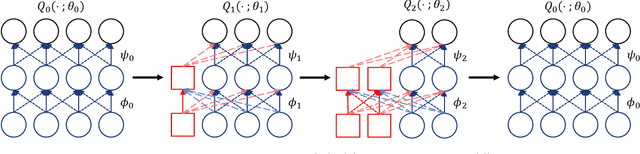
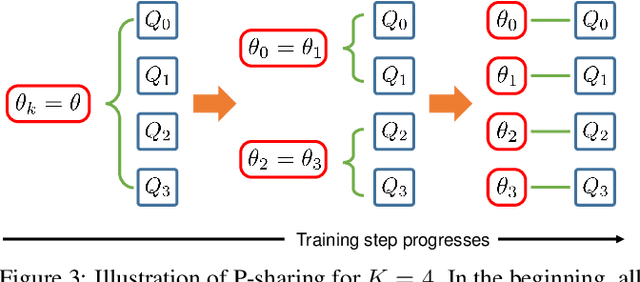
We consider the Markov Decision Process (MDP) of selecting a subset of items at each step, termed the Select-MDP (S-MDP). The large state and action spaces of S-MDPs make them intractable to solve with typical reinforcement learning (RL) algorithms especially when the number of items is huge. In this paper, we present a deep RL algorithm to solve this issue by adopting the following key ideas. First, we convert the original S-MDP into an Iterative Select-MDP (IS-MDP), which is equivalent to the S-MDP in terms of optimal actions. IS-MDP decomposes a joint action of selecting K items simultaneously into K iterative selections resulting in the decrease of actions at the expense of an exponential increase of states. Second, we overcome this state space explo-sion by exploiting a special symmetry in IS-MDPs with novel weight shared Q-networks, which prov-ably maintain sufficient expressive power. Various experiments demonstrate that our approach works well even when the item space is large and that it scales to environments with item spaces different from those used in training.