 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Memorization Behavior of LLMs in Generative Recommendation: Observations, Implications, and Training Strategies
Jun 17, 2026Generative recommendation (GR) has emerged as a promising direction for recommender systems. Recently, large language models (LLMs) have been increasingly adopted for GR, as their rich pretrained knowledge is expected to help them generalize beyond common user behavior patterns that traditional memorization-oriented baselines can capture. However, existing LLM-based GR works largely ignore LLMs' well-known tendency to memorize, which, if present in LLMs fine-tuned for GR, would restrict their utilization of pretrained knowledge. In this work, we investigate this concern by examining one-hop memorization, where a model recommends items that are direct successors of items in the training data. We show that LLMs do this more than non-LLM-based GR models-in fact, the vast majority of their gains over GR baselines are actually on users whose target items can be predicted through one-hop memorization. We intuit that improving performance on the remaining users requires LLMs to learn richer item-item relations beyond one-hop transitions. To achieve this, we propose IIRG, a novel training strategy that teaches LLMs to capture: (1) collaborative relations derived from item co-occurrences across multiple hops in user sequences, and (2) semantic relations among items with similar themes, both of which can serve as useful recommendation signals. We show that IIRG significantly improves over LLMs trained solely with standard next-item prediction, with especially large gains for users whose test items are not covered by train-time one-hop transitions.
Effective Dataset Distillation for Spatio-Temporal Forecasting with Bi-dimensional Compression
Mar 11, 2026Spatio-temporal time series are widely used in real-world applications, including traffic prediction and weather forecasting. They are sequences of observations over extensive periods and multiple locations, naturally represented as multidimensional data. Forecasting is a central task in spatio-temporal analysis, and numerous deep learning methods have been developed to address it. However, as dataset sizes and model complexities continue to grow in practice, training deep learning models has become increasingly time- and resource-intensive. A promising solution to this challenge is dataset distillation, which synthesizes compact datasets that can effectively replace the original data for model training. Although successful in various domains, including time series analysis, existing dataset distillation methods compress only one dimension, making them less suitable for spatio-temporal datasets, where both spatial and temporal dimensions jointly contribute to the large data volume. To address this limitation, we propose STemDist, the first dataset distillation method specialized for spatio-temporal time series forecasting. A key idea of our solution is to compress both temporal and spatial dimensions in a balanced manner, reducing training time and memory. We further reduce the distillation cost by performing distillation at the cluster level rather than the individual location level, and we complement this coarse-grained approach with a subset-based granular distillation technique that enhances forecasting performance. On five real-world datasets, we show empirically that, compared to both general and time-series dataset distillation methods, datasets distilled by our STemDist method enable model training (1) faster (up to 6X) (2) more memory-efficient (up to 8X), and (3) more effective (with up to 12% lower prediction error).
Personalized Parameter-Efficient Fine-Tuning of Foundation Models for Multimodal Recommendation
Feb 10, 2026In recent years, substantial research has integrated multimodal item metadata into recommender systems, often by using pre-trained multimodal foundation models to encode such data. Since these models are not originally trained for recommendation tasks, recent works efficiently adapt them via parameter-efficient fine-tuning (PEFT). However, even with PEFT, item embeddings from multimodal foundation models remain user-blind: item embeddings are not conditioned on user interests, despite the fact that users with diverse interests attend to different item aspects. To address this limitation, we propose PerPEFT, a personalized PEFT strategy for multimodal recommendation. Specifically, PerPEFT groups users by interest and assigns a distinct PEFT module to each group, enabling each module to capture the fine-grained item aspects most predictive of that group`s purchase decisions. We further introduce a specialized training technique that strengthens this user-group conditioning. Notably, PerPEFT is PEFT-agnostic and can be paired with any PEFT method applicable to multimodal foundation models. Through extensive experiments, we show that (1) PerPEFT outperforms the strongest baseline by up to 15.3% (NDCG@20) and (2) delivers consistent gains across diverse PEFT variants. It is noteworthy that, even with personalization, PEFT remains lightweight, adding only 1.3% of the parameter count of the foundation model. We provide our code and datasets at https://github.com/kswoo97/PerPEFT.
ReFuGe: Feature Generation for Prediction Tasks on Relational Databases with LLM Agents
Jan 25, 2026Relational databases (RDBs) play a crucial role in many real-world web applications, supporting data management across multiple interconnected tables. Beyond typical retrieval-oriented tasks, prediction tasks on RDBs have recently gained attention. In this work, we address this problem by generating informative relational features that enhance predictive performance. However, generating such features is challenging: it requires reasoning over complex schemas and exploring a combinatorially large feature space, all without explicit supervision. To address these challenges, we propose ReFuGe, an agentic framework that leverages specialized large language model agents: (1) a schema selection agent identifies the tables and columns relevant to the task, (2) a feature generation agent produces diverse candidate features from the selected schema, and (3) a feature filtering agent evaluates and retains promising features through reasoning-based and validation-based filtering. It operates within an iterative feedback loop until performance converges. Experiments on RDB benchmarks demonstrate that ReFuGe substantially improves performance on various RDB prediction tasks. Our code and datasets are available at https://github.com/K-Kyungho/REFUGE.
Feature-Centric Unsupervised Node Representation Learning Without Homophily Assumption
Dec 17, 2025Unsupervised node representation learning aims to obtain meaningful node embeddings without relying on node labels. To achieve this, graph convolution, which aggregates information from neighboring nodes, is commonly employed to encode node features and graph topology. However, excessive reliance on graph convolution can be suboptimal-especially in non-homophilic graphs-since it may yield unduly similar embeddings for nodes that differ in their features or topological properties. As a result, adjusting the degree of graph convolution usage has been actively explored in supervised learning settings, whereas such approaches remain underexplored in unsupervised scenarios. To tackle this, we propose FUEL, which adaptively learns the adequate degree of graph convolution usage by aiming to enhance intra-class similarity and inter-class separability in the embedding space. Since classes are unknown, FUEL leverages node features to identify node clusters and treats these clusters as proxies for classes. Through extensive experiments using 15 baseline methods and 14 benchmark datasets, we demonstrate the effectiveness of FUEL in downstream tasks, achieving state-of-the-art performance across graphs with diverse levels of homophily.
ItemRAG: Item-Based Retrieval-Augmented Generation for LLM-Based Recommendation
Nov 19, 2025Recently, large language models (LLMs) have been widely used as recommender systems, owing to their strong reasoning capability and their effectiveness in handling cold-start items. To better adapt LLMs for recommendation, retrieval-augmented generation (RAG) has been incorporated. Most existing RAG methods are user-based, retrieving purchase patterns of users similar to the target user and providing them to the LLM. In this work, we propose ItemRAG, an item-based RAG method for LLM-based recommendation that retrieves relevant items (rather than users) from item-item co-purchase histories. ItemRAG helps LLMs capture co-purchase patterns among items, which are beneficial for recommendations. Especially, our retrieval strategy incorporates semantically similar items to better handle cold-start items and uses co-purchase frequencies to improve the relevance of the retrieved items. Through extensive experiments, we demonstrate that ItemRAG consistently (1) improves the zero-shot LLM-based recommender by up to 43% in Hit-Ratio-1 and (2) outperforms user-based RAG baselines under both standard and cold-start item recommendation settings.
A Self-Supervised Mixture-of-Experts Framework for Multi-behavior Recommendation
Aug 28, 2025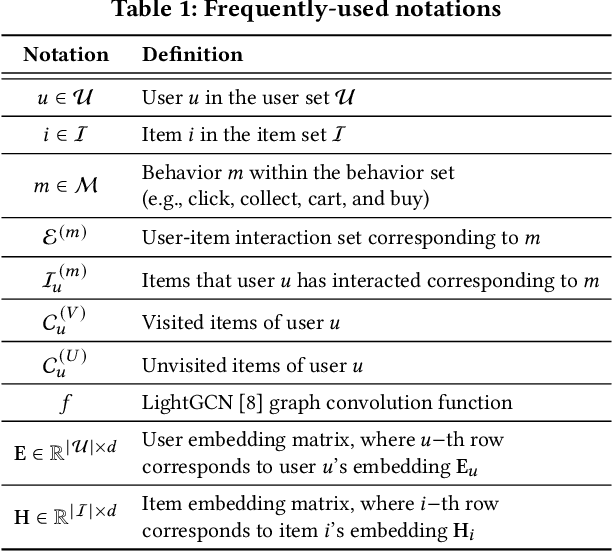
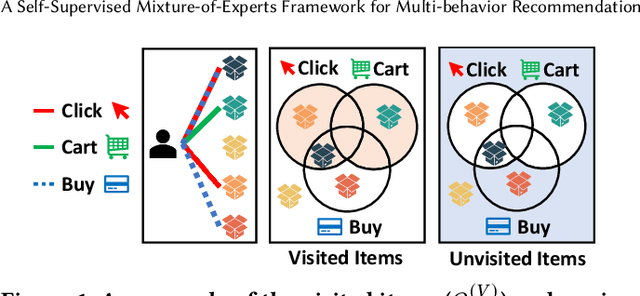
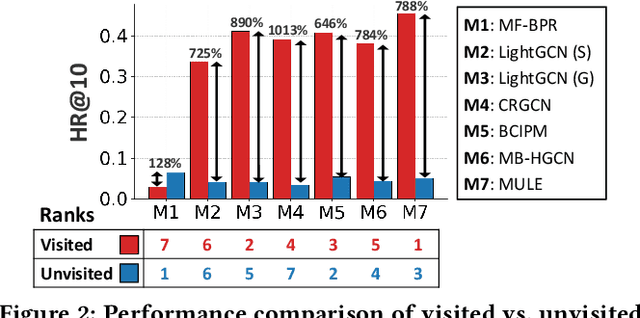
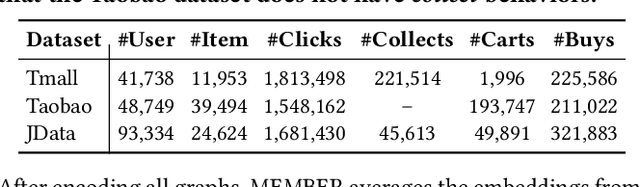
In e-commerce, where users face a vast array of possible item choices, recommender systems are vital for helping them discover suitable items they might otherwise overlook. While many recommender systems primarily rely on a user's purchase history, recent multi-behavior recommender systems incorporate various auxiliary user behaviors, such as item clicks and cart additions, to enhance recommendations. Despite their overall performance gains, their effectiveness varies considerably between visited items (i.e., those a user has interacted with through auxiliary behaviors) and unvisited items (i.e., those with which the user has had no such interactions). Specifically, our analysis reveals that (1) existing multi-behavior recommender systems exhibit a significant gap in recommendation quality between the two item types (visited and unvisited items) and (2) achieving strong performance on both types with a single model architecture remains challenging. To tackle these issues, we propose a novel multi-behavior recommender system, MEMBER. It employs a mixture-of-experts framework, with experts designed to recommend the two item types, respectively. Each expert is trained using a self-supervised method specialized for its design goal. In our comprehensive experiments, we show the effectiveness of MEMBER across both item types, achieving up to 65.46% performance gain over the best competitor in terms of Hit Ratio@20.
'Hello, World!': Making GNNs Talk with LLMs
May 27, 2025While graph neural networks (GNNs) have shown remarkable performance across diverse graph-related tasks, their high-dimensional hidden representations render them black boxes. In this work, we propose Graph Lingual Network (GLN), a GNN built on large language models (LLMs), with hidden representations in the form of human-readable text. Through careful prompt design, GLN incorporates not only the message passing module of GNNs but also advanced GNN techniques, including graph attention and initial residual connection. The comprehensibility of GLN's hidden representations enables an intuitive analysis of how node representations change (1) across layers and (2) under advanced GNN techniques, shedding light on the inner workings of GNNs. Furthermore, we demonstrate that GLN achieves strong zero-shot performance on node classification and link prediction, outperforming existing LLM-based baseline methods.
KGMEL: Knowledge Graph-Enhanced Multimodal Entity Linking
Apr 21, 2025


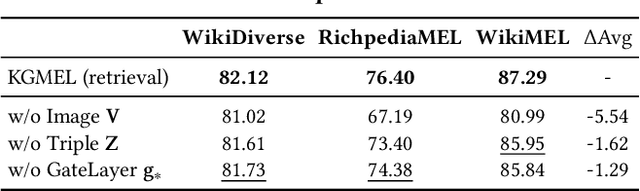
Entity linking (EL) aligns textual mentions with their corresponding entities in a knowledge base, facilitating various applications such as semantic search and question answering. Recent advances in multimodal entity linking (MEL) have shown that combining text and images can reduce ambiguity and improve alignment accuracy. However, most existing MEL methods overlook the rich structural information available in the form of knowledge-graph (KG) triples. In this paper, we propose KGMEL, a novel framework that leverages KG triples to enhance MEL. Specifically, it operates in three stages: (1) Generation: Produces high-quality triples for each mention by employing vision-language models based on its text and images. (2) Retrieval: Learns joint mention-entity representations, via contrastive learning, that integrate text, images, and (generated or KG) triples to retrieve candidate entities for each mention. (3) Reranking: Refines the KG triples of the candidate entities and employs large language models to identify the best-matching entity for the mention. Extensive experiments on benchmark datasets demonstrate that KGMEL outperforms existing methods. Our code and datasets are available at: https://github.com/juyeonnn/KGMEL.
Emergence of psychopathological computations in large language models
Apr 10, 2025Can large language models (LLMs) implement computations of psychopathology? An effective approach to the question hinges on addressing two factors. First, for conceptual validity, we require a general and computational account of psychopathology that is applicable to computational entities without biological embodiment or subjective experience. Second, mechanisms underlying LLM behaviors need to be studied for better methodological validity. Thus, we establish a computational-theoretical framework to provide an account of psychopathology applicable to LLMs. To ground the theory for empirical analysis, we also propose a novel mechanistic interpretability method alongside a tailored empirical analytic framework. Based on the frameworks, we conduct experiments demonstrating three key claims: first, that distinct dysfunctional and problematic representational states are implemented in LLMs; second, that their activations can spread and self-sustain to trap LLMs; and third, that dynamic, cyclic structural causal models encoded in the LLMs underpin these patterns. In concert, the empirical results corroborate our hypothesis that network-theoretic computations of psychopathology have already emerged in LLMs. This suggests that certain LLM behaviors mirroring psychopathology may not be a superficial mimicry but a feature of their internal processing. Thus, our work alludes to the possibility of AI systems with psychopathological behaviors in the near future.