 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergence of psychopathological computations in large language models
Apr 10, 2025Can large language models (LLMs) implement computations of psychopathology? An effective approach to the question hinges on addressing two factors. First, for conceptual validity, we require a general and computational account of psychopathology that is applicable to computational entities without biological embodiment or subjective experience. Second, mechanisms underlying LLM behaviors need to be studied for better methodological validity. Thus, we establish a computational-theoretical framework to provide an account of psychopathology applicable to LLMs. To ground the theory for empirical analysis, we also propose a novel mechanistic interpretability method alongside a tailored empirical analytic framework. Based on the frameworks, we conduct experiments demonstrating three key claims: first, that distinct dysfunctional and problematic representational states are implemented in LLMs; second, that their activations can spread and self-sustain to trap LLMs; and third, that dynamic, cyclic structural causal models encoded in the LLMs underpin these patterns. In concert, the empirical results corroborate our hypothesis that network-theoretic computations of psychopathology have already emerged in LLMs. This suggests that certain LLM behaviors mirroring psychopathology may not be a superficial mimicry but a feature of their internal processing. Thus, our work alludes to the possibility of AI systems with psychopathological behaviors in the near future.
Context-Aware Planning and Environment-Aware Memory for Instruction Following Embodied Agents
Aug 22, 2023

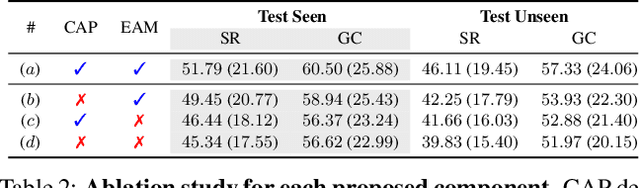
Accomplishing household tasks requires to plan step-by-step actions considering the consequences of previous actions. However, the state-of-the-art embodied agents often make mistakes in navigating the environment and interacting with proper objects due to imperfect learning by imitating experts or algorithmic planners without such knowledge. To improve both visual navigation and object interaction, we propose to consider the consequence of taken actions by CAPEAM (Context-Aware Planning and Environment-Aware Memory) that incorporates semantic context (e.g., appropriate objects to interact with) in a sequence of actions, and the changed spatial arrangement and states of interacted objects (e.g., location that the object has been moved to) in inferring the subsequent actions. We empirically show that the agent with the proposed CAPEAM achieves state-of-the-art performance in various metrics using a challenging interactive instruction following benchmark in both seen and unseen environments by large margins (up to +10.70% in unseen env.).