 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Grounded Planning and Efficient Replanning For Learning Embodied Agents with A Few Examples
Dec 23, 2024Learning a perception and reasoning module for robotic assistants to plan steps to perform complex tasks based on natural language instructions often requires large free-form language annotations, especially for short high-level instructions. To reduce the cost of annotation, large language models (LLMs) are used as a planner with few data. However, when elaborating the steps, even the state-of-the-art planner that uses LLMs mostly relies on linguistic common sense, often neglecting the status of the environment at command reception, resulting in inappropriate plans. To generate plans grounded in the environment, we propose FLARE (Few-shot Language with environmental Adaptive Replanning Embodied agent), which improves task planning using both language command and environmental perception. As language instructions often contain ambiguities or incorrect expressions, we additionally propose to correct the mistakes using visual cues from the agent. The proposed scheme allows us to use a few language pairs thanks to the visual cues and outperforms state-of-the-art approaches. Our code is available at https://github.com/snumprlab/flare.
ReALFRED: An Embodied Instruction Following Benchmark in Photo-Realistic Environments
Jul 26, 2024

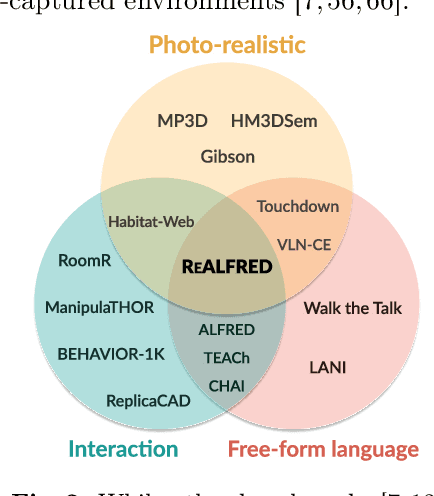

Simulated virtual environments have been widely used to learn robotic agents that perform daily household tasks. These environments encourage research progress by far, but often provide limited object interactability, visual appearance different from real-world environments, or relatively smaller environment sizes. This prevents the learned models in the virtual scenes from being readily deployable. To bridge the gap between these learning environments and deploying (i.e., real) environments, we propose the ReALFRED benchmark that employs real-world scenes, objects, and room layouts to learn agents to complete household tasks by understanding free-form language instructions and interacting with objects in large, multi-room and 3D-captured scenes. Specifically, we extend the ALFRED benchmark with updates for larger environmental spaces with smaller visual domain gaps. With ReALFRED, we analyze previously crafted methods for the ALFRED benchmark and observe that they consistently yield lower performance in all metrics, encouraging the community to develop methods in more realistic environments. Our code and data are publicly available.
Online Continual Learning For Interactive Instruction Following Agents
Mar 13, 2024In learning an embodied agent executing daily tasks via language directives, the literature largely assumes that the agent learns all training data at the beginning. We argue that such a learning scenario is less realistic since a robotic agent is supposed to learn the world continuously as it explores and perceives it. To take a step towards a more realistic embodied agent learning scenario, we propose two continual learning setups for embodied agents; learning new behaviors (Behavior Incremental Learning, Behavior-IL) and new environments (Environment Incremental Learning, Environment-IL) For the tasks, previous 'data prior' based continual learning methods maintain logits for the past tasks. However, the stored information is often insufficiently learned information and requires task boundary information, which might not always be available. Here, we propose to update them based on confidence scores without task boundary information during training (i.e., task-free) in a moving average fashion, named Confidence-Aware Moving Average (CAMA). In the proposed Behavior-IL and Environment-IL setups, our simple CAMA outperforms prior state of the art in our empirical validations by noticeable margins. The project page including codes is https://github.com/snumprlab/cl-alfred.
Context-Aware Planning and Environment-Aware Memory for Instruction Following Embodied Agents
Aug 22, 2023
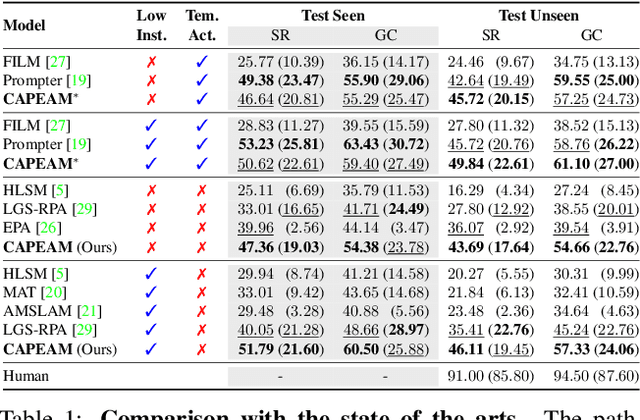

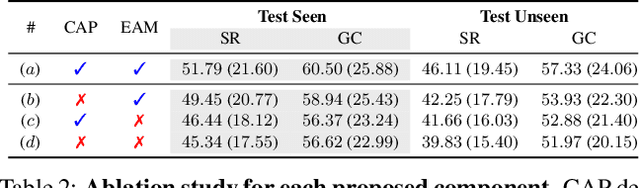
Accomplishing household tasks requires to plan step-by-step actions considering the consequences of previous actions. However, the state-of-the-art embodied agents often make mistakes in navigating the environment and interacting with proper objects due to imperfect learning by imitating experts or algorithmic planners without such knowledge. To improve both visual navigation and object interaction, we propose to consider the consequence of taken actions by CAPEAM (Context-Aware Planning and Environment-Aware Memory) that incorporates semantic context (e.g., appropriate objects to interact with) in a sequence of actions, and the changed spatial arrangement and states of interacted objects (e.g., location that the object has been moved to) in inferring the subsequent actions. We empirically show that the agent with the proposed CAPEAM achieves state-of-the-art performance in various metrics using a challenging interactive instruction following benchmark in both seen and unseen environments by large margins (up to +10.70% in unseen env.).
Multi-Level Compositional Reasoning for Interactive Instruction Following
Aug 18, 2023Robotic agents performing domestic chores by natural language directives are required to master the complex job of navigating environment and interacting with objects in the environments. The tasks given to the agents are often composite thus are challenging as completing them require to reason about multiple subtasks, e.g., bring a cup of coffee. To address the challenge, we propose to divide and conquer it by breaking the task into multiple subgoals and attend to them individually for better navigation and interaction. We call it Multi-level Compositional Reasoning Agent (MCR-Agent). Specifically, we learn a three-level action policy. At the highest level, we infer a sequence of human-interpretable subgoals to be executed based on language instructions by a high-level policy composition controller. At the middle level, we discriminatively control the agent's navigation by a master policy by alternating between a navigation policy and various independent interaction policies. Finally, at the lowest level, we infer manipulation actions with the corresponding object masks using the appropriate interaction policy. Our approach not only generates human interpretable subgoals but also achieves 2.03% absolute gain to comparable state of the arts in the efficiency metric (PLWSR in unseen set) without using rule-based planning or a semantic spatial memory.
MOCA: A Modular Object-Centric Approach for Interactive Instruction Following
Dec 06, 2020



Performing simple household tasks based on language directives is very natural to humans, yet it remains an open challenge for an AI agent. Recently, an `interactive instruction following' task has been proposed to foster research in reasoning over long instruction sequences that requires object interactions in a simulated environment. It involves solving open problems in vision, language and navigation literature at each step. To address this multifaceted problem, we propose a modular architecture that decouples the task into visual perception and action policy, and name it as MOCA, a Modular Object-Centric Approach. We evaluate our method on the ALFRED benchmark and empirically validate that it outperforms prior arts by significant margins in all metrics with good generalization performance (high success rate in unseen environments). Our code is available at https://github.com/gistvision/moca.