 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBudgeted Online Continual Learning by Adaptive Layer Freezing and Frequency-based Sampling
Oct 19, 2024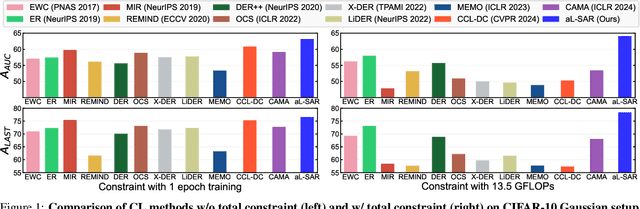
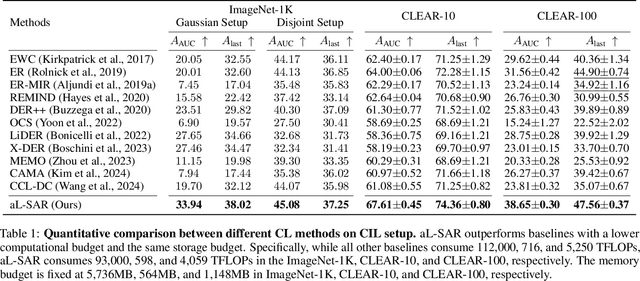
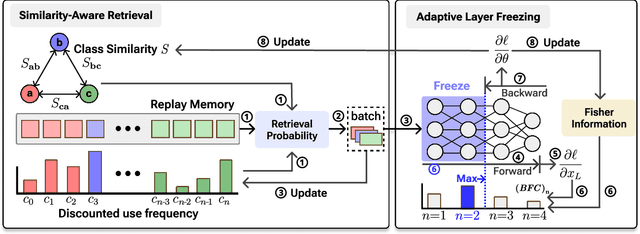
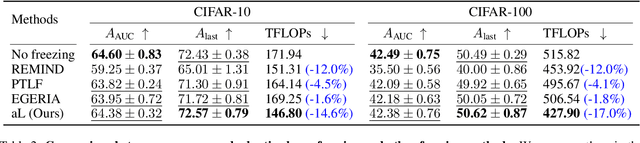
The majority of online continual learning (CL) advocates single-epoch training and imposes restrictions on the size of replay memory. However, single-epoch training would incur a different amount of computations per CL algorithm, and the additional storage cost to store logit or model in addition to replay memory is largely ignored in calculating the storage budget. Arguing different computational and storage budgets hinder fair comparison among CL algorithms in practice, we propose to use floating point operations (FLOPs) and total memory size in Byte as a metric for computational and memory budgets, respectively, to compare and develop CL algorithms in the same 'total resource budget.' To improve a CL method in a limited total budget, we propose adaptive layer freezing that does not update the layers for less informative batches to reduce computational costs with a negligible loss of accuracy. In addition, we propose a memory retrieval method that allows the model to learn the same amount of knowledge as using random retrieval in fewer iterations. Empirical validations on the CIFAR-10/100, CLEAR-10/100, and ImageNet-1K datasets demonstrate that the proposed approach outperforms the state-of-the-art methods within the same total budget
Learning Equi-angular Representations for Online Continual Learning
Apr 02, 2024



Online continual learning suffers from an underfitted solution due to insufficient training for prompt model update (e.g., single-epoch training). To address the challenge, we propose an efficient online continual learning method using the neural collapse phenomenon. In particular, we induce neural collapse to form a simplex equiangular tight frame (ETF) structure in the representation space so that the continuously learned model with a single epoch can better fit to the streamed data by proposing preparatory data training and residual correction in the representation space. With an extensive set of empirical validations using CIFAR-10/100, TinyImageNet, ImageNet-200, and ImageNet-1K, we show that our proposed method outperforms state-of-the-art methods by a noticeable margin in various online continual learning scenarios such as disjoint and Gaussian scheduled continuous (i.e., boundary-free) data setups.
Just Say the Name: Online Continual Learning with Category Names Only via Data Generation
Mar 16, 2024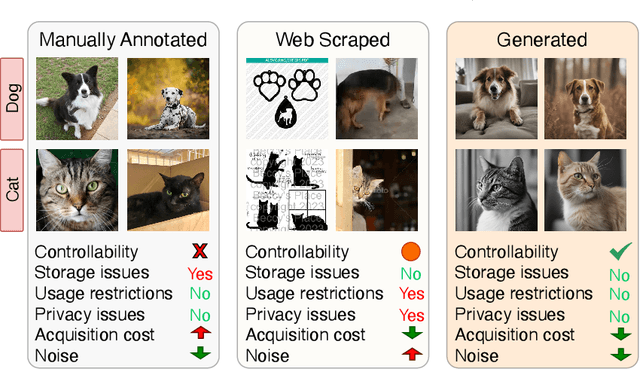



In real-world scenarios, extensive manual annotation for continual learning is impractical due to prohibitive costs. Although prior arts, influenced by large-scale webly supervised training, suggest leveraging web-scraped data in continual learning, this poses challenges such as data imbalance, usage restrictions, and privacy concerns. Addressing the risks of continual webly supervised training, we present an online continual learning framework - Generative Name only Continual Learning (G-NoCL). The proposed G-NoCL uses a set of generators G along with the learner. When encountering new concepts (i.e., classes), G-NoCL employs the novel sample complexity-guided data ensembling technique DIverSity and COmplexity enhancing ensemBlER (DISCOBER) to optimally sample training data from generated data. Through extensive experimentation, we demonstrate superior performance of DISCOBER in G-NoCL online CL benchmarks, covering both In-Distribution (ID) and Out-of-Distribution (OOD) generalization evaluations, compared to naive generator-ensembling, web-supervised, and manually annotated data.
Online Continual Learning For Interactive Instruction Following Agents
Mar 13, 2024In learning an embodied agent executing daily tasks via language directives, the literature largely assumes that the agent learns all training data at the beginning. We argue that such a learning scenario is less realistic since a robotic agent is supposed to learn the world continuously as it explores and perceives it. To take a step towards a more realistic embodied agent learning scenario, we propose two continual learning setups for embodied agents; learning new behaviors (Behavior Incremental Learning, Behavior-IL) and new environments (Environment Incremental Learning, Environment-IL) For the tasks, previous 'data prior' based continual learning methods maintain logits for the past tasks. However, the stored information is often insufficiently learned information and requires task boundary information, which might not always be available. Here, we propose to update them based on confidence scores without task boundary information during training (i.e., task-free) in a moving average fashion, named Confidence-Aware Moving Average (CAMA). In the proposed Behavior-IL and Environment-IL setups, our simple CAMA outperforms prior state of the art in our empirical validations by noticeable margins. The project page including codes is https://github.com/snumprlab/cl-alfred.