 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCALE: Self-uncertainty Conditioned Adaptive Looking and Execution for Vision-Language-Action Models
Feb 04, 2026Vision-Language-Action (VLA) models have emerged as a promising paradigm for general-purpose robotic control, with test-time scaling (TTS) gaining attention to enhance robustness beyond training. However, existing TTS methods for VLAs require additional training, verifiers, and multiple forward passes, making them impractical for deployment. Moreover, they intervene only at action decoding while keeping visual representations fixed-insufficient under perceptual ambiguity, where reconsidering how to perceive is as important as deciding what to do. To address these limitations, we propose SCALE, a simple inference strategy that jointly modulates visual perception and action based on 'self-uncertainty', inspired by uncertainty-driven exploration in Active Inference theory-requiring no additional training, no verifier, and only a single forward pass. SCALE broadens exploration in both perception and action under high uncertainty, while focusing on exploitation when confident-enabling adaptive execution across varying conditions. Experiments on simulated and real-world benchmarks demonstrate that SCALE improves state-of-the-art VLAs and outperforms existing TTS methods while maintaining single-pass efficiency.
Just Say the Name: Online Continual Learning with Category Names Only via Data Generation
Mar 16, 2024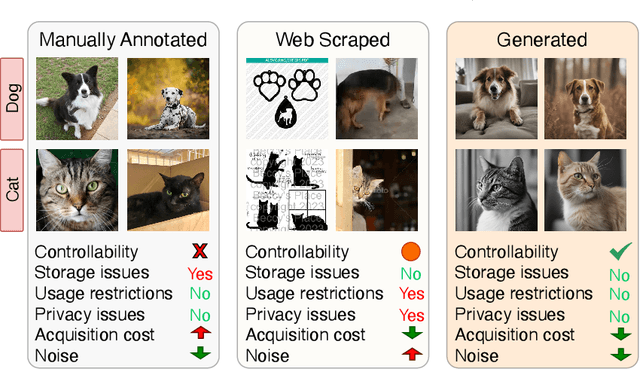



In real-world scenarios, extensive manual annotation for continual learning is impractical due to prohibitive costs. Although prior arts, influenced by large-scale webly supervised training, suggest leveraging web-scraped data in continual learning, this poses challenges such as data imbalance, usage restrictions, and privacy concerns. Addressing the risks of continual webly supervised training, we present an online continual learning framework - Generative Name only Continual Learning (G-NoCL). The proposed G-NoCL uses a set of generators G along with the learner. When encountering new concepts (i.e., classes), G-NoCL employs the novel sample complexity-guided data ensembling technique DIverSity and COmplexity enhancing ensemBlER (DISCOBER) to optimally sample training data from generated data. Through extensive experimentation, we demonstrate superior performance of DISCOBER in G-NoCL online CL benchmarks, covering both In-Distribution (ID) and Out-of-Distribution (OOD) generalization evaluations, compared to naive generator-ensembling, web-supervised, and manually annotated data.