 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJust Say the Name: Online Continual Learning with Category Names Only via Data Generation
Paper and Code
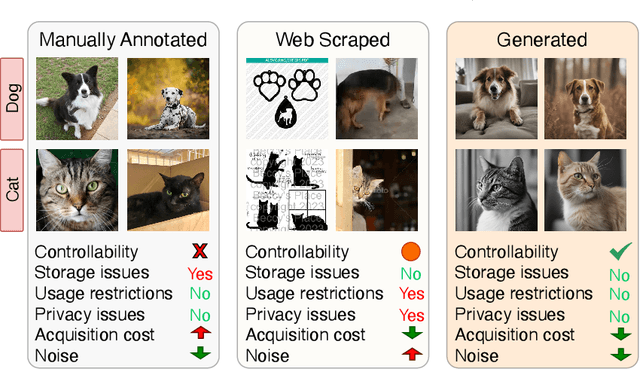



In real-world scenarios, extensive manual annotation for continual learning is impractical due to prohibitive costs. Although prior arts, influenced by large-scale webly supervised training, suggest leveraging web-scraped data in continual learning, this poses challenges such as data imbalance, usage restrictions, and privacy concerns. Addressing the risks of continual webly supervised training, we present an online continual learning framework - Generative Name only Continual Learning (G-NoCL). The proposed G-NoCL uses a set of generators G along with the learner. When encountering new concepts (i.e., classes), G-NoCL employs the novel sample complexity-guided data ensembling technique DIverSity and COmplexity enhancing ensemBlER (DISCOBER) to optimally sample training data from generated data. Through extensive experimentation, we demonstrate superior performance of DISCOBER in G-NoCL online CL benchmarks, covering both In-Distribution (ID) and Out-of-Distribution (OOD) generalization evaluations, compared to naive generator-ensembling, web-supervised, and manually annotated data.