 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKFinEval-Pilot: A Comprehensive Benchmark Suite for Korean Financial Language Understanding
Apr 17, 2025We introduce KFinEval-Pilot, a benchmark suite specifically designed to evaluate large language models (LLMs) in the Korean financial domain. Addressing the limitations of existing English-centric benchmarks, KFinEval-Pilot comprises over 1,000 curated questions across three critical areas: financial knowledge, legal reasoning, and financial toxicity. The benchmark is constructed through a semi-automated pipeline that combines GPT-4-generated prompts with expert validation to ensure domain relevance and factual accuracy. We evaluate a range of representative LLMs and observe notable performance differences across models, with trade-offs between task accuracy and output safety across different model families. These results highlight persistent challenges in applying LLMs to high-stakes financial applications, particularly in reasoning and safety. Grounded in real-world financial use cases and aligned with the Korean regulatory and linguistic context, KFinEval-Pilot serves as an early diagnostic tool for developing safer and more reliable financial AI systems.
Multi-Modal Grounded Planning and Efficient Replanning For Learning Embodied Agents with A Few Examples
Dec 23, 2024Learning a perception and reasoning module for robotic assistants to plan steps to perform complex tasks based on natural language instructions often requires large free-form language annotations, especially for short high-level instructions. To reduce the cost of annotation, large language models (LLMs) are used as a planner with few data. However, when elaborating the steps, even the state-of-the-art planner that uses LLMs mostly relies on linguistic common sense, often neglecting the status of the environment at command reception, resulting in inappropriate plans. To generate plans grounded in the environment, we propose FLARE (Few-shot Language with environmental Adaptive Replanning Embodied agent), which improves task planning using both language command and environmental perception. As language instructions often contain ambiguities or incorrect expressions, we additionally propose to correct the mistakes using visual cues from the agent. The proposed scheme allows us to use a few language pairs thanks to the visual cues and outperforms state-of-the-art approaches. Our code is available at https://github.com/snumprlab/flare.
ReALFRED: An Embodied Instruction Following Benchmark in Photo-Realistic Environments
Jul 26, 2024

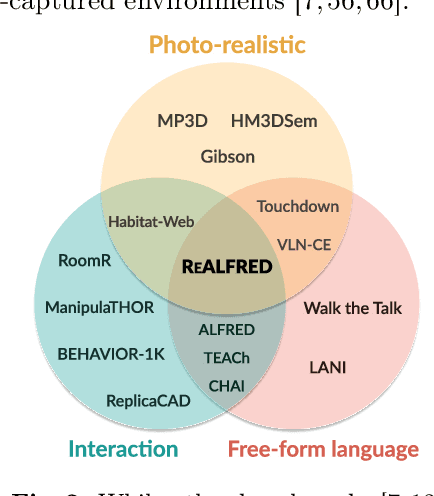

Simulated virtual environments have been widely used to learn robotic agents that perform daily household tasks. These environments encourage research progress by far, but often provide limited object interactability, visual appearance different from real-world environments, or relatively smaller environment sizes. This prevents the learned models in the virtual scenes from being readily deployable. To bridge the gap between these learning environments and deploying (i.e., real) environments, we propose the ReALFRED benchmark that employs real-world scenes, objects, and room layouts to learn agents to complete household tasks by understanding free-form language instructions and interacting with objects in large, multi-room and 3D-captured scenes. Specifically, we extend the ALFRED benchmark with updates for larger environmental spaces with smaller visual domain gaps. With ReALFRED, we analyze previously crafted methods for the ALFRED benchmark and observe that they consistently yield lower performance in all metrics, encouraging the community to develop methods in more realistic environments. Our code and data are publicly available.