 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Backstepping Control of Omnidirectional Tiltrotors Incorporating Servo-Rotor Dynamics for Robustness against Sudden Disturbances
Oct 02, 2025This work presents a geometric backstepping controller for a variable-tilt omnidirectional multirotor that explicitly accounts for both servo and rotor dynamics. Considering actuator dynamics is essential for more effective and reliable operation, particularly during aggressive flight maneuvers or recovery from sudden disturbances. While prior studies have investigated actuator-aware control for conventional and fixed-tilt multirotors, these approaches rely on linear relationships between actuator input and wrench, which cannot capture the nonlinearities induced by variable tilt angles. In this work, we exploit the cascade structure between the rigid-body dynamics of the multirotor and its nonlinear actuator dynamics to design the proposed backstepping controller and establish exponential stability of the overall system. Furthermore, we reveal parametric uncertainty in the actuator model through experiments, and we demonstrate that the proposed controller remains robust against such uncertainty. The controller was compared against a baseline that does not account for actuator dynamics across three experimental scenarios: fast translational tracking, rapid rotational tracking, and recovery from sudden disturbance. The proposed method consistently achieved better tracking performance, and notably, while the baseline diverged and crashed during the fastest translational trajectory tracking and the recovery experiment, the proposed controller maintained stability and successfully completed the tasks, thereby demonstrating its effectiveness.
Optimizing Indoor Farm Monitoring Efficiency Using UAV: Yield Estimation in a GNSS-Denied Cherry Tomato Greenhouse
May 02, 2025


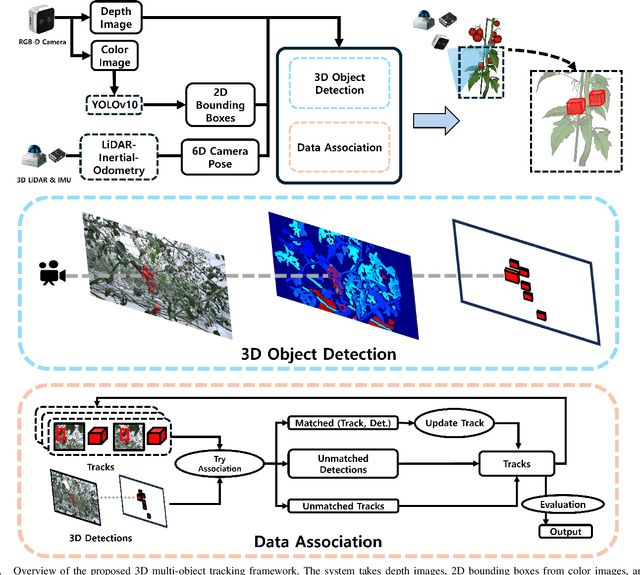
As the agricultural workforce declines and labor costs rise, robotic yield estimation has become increasingly important. While unmanned ground vehicles (UGVs) are commonly used for indoor farm monitoring, their deployment in greenhouses is often constrained by infrastructure limitations, sensor placement challenges, and operational inefficiencies. To address these issues, we develop a lightweight unmanned aerial vehicle (UAV) equipped with an RGB-D camera, a 3D LiDAR, and an IMU sensor. The UAV employs a LiDAR-inertial odometry algorithm for precise navigation in GNSS-denied environments and utilizes a 3D multi-object tracking algorithm to estimate the count and weight of cherry tomatoes. We evaluate the system using two dataset: one from a harvesting row and another from a growing row. In the harvesting-row dataset, the proposed system achieves 94.4\% counting accuracy and 87.5\% weight estimation accuracy within a 13.2-meter flight completed in 10.5 seconds. For the growing-row dataset, which consists of occluded unripened fruits, we qualitatively analyze tracking performance and highlight future research directions for improving perception in greenhouse with strong occlusions. Our findings demonstrate the potential of UAVs for efficient robotic yield estimation in commercial greenhouses.
KFinEval-Pilot: A Comprehensive Benchmark Suite for Korean Financial Language Understanding
Apr 17, 2025We introduce KFinEval-Pilot, a benchmark suite specifically designed to evaluate large language models (LLMs) in the Korean financial domain. Addressing the limitations of existing English-centric benchmarks, KFinEval-Pilot comprises over 1,000 curated questions across three critical areas: financial knowledge, legal reasoning, and financial toxicity. The benchmark is constructed through a semi-automated pipeline that combines GPT-4-generated prompts with expert validation to ensure domain relevance and factual accuracy. We evaluate a range of representative LLMs and observe notable performance differences across models, with trade-offs between task accuracy and output safety across different model families. These results highlight persistent challenges in applying LLMs to high-stakes financial applications, particularly in reasoning and safety. Grounded in real-world financial use cases and aligned with the Korean regulatory and linguistic context, KFinEval-Pilot serves as an early diagnostic tool for developing safer and more reliable financial AI systems.
Doppler Correspondence: Non-Iterative Scan Matching With Doppler Velocity-Based Correspondence
Feb 17, 2025Achieving successful scan matching is essential for LiDAR odometry. However, in challenging environments with adverse weather conditions or repetitive geometric patterns, LiDAR odometry performance is degraded due to incorrect scan matching. Recently, the emergence of frequency-modulated continuous wave 4D LiDAR and 4D radar technologies has provided the potential to address these unfavorable conditions. The term 4D refers to point cloud data characterized by range, azimuth, and elevation along with Doppler velocity. Although 4D data is available, most scan matching methods for 4D LiDAR and 4D radar still establish correspondence by repeatedly identifying the closest points between consecutive scans, overlooking the Doppler information. This paper introduces, for the first time, a simple Doppler velocity-based correspondence -- Doppler Correspondence -- that is invariant to translation and small rotation of the sensor, with its geometric and kinematic foundations. Extensive experiments demonstrate that the proposed method enables the direct matching of consecutive point clouds without an iterative process, making it computationally efficient. Additionally, it provides a more robust correspondence estimation in environments with repetitive geometric patterns.
RAPID: Robust and Agile Planner Using Inverse Reinforcement Learning for Vision-Based Drone Navigation
Feb 04, 2025This paper introduces a learning-based visual planner for agile drone flight in cluttered environments. The proposed planner generates collision-free waypoints in milliseconds, enabling drones to perform agile maneuvers in complex environments without building separate perception, mapping, and planning modules. Learning-based methods, such as behavior cloning (BC) and reinforcement learning (RL), demonstrate promising performance in visual navigation but still face inherent limitations. BC is susceptible to compounding errors due to limited expert imitation, while RL struggles with reward function design and sample inefficiency. To address these limitations, this paper proposes an inverse reinforcement learning (IRL)-based framework for high-speed visual navigation. By leveraging IRL, it is possible to reduce the number of interactions with simulation environments and improve capability to deal with high-dimensional spaces while preserving the robustness of RL policies. A motion primitive-based path planning algorithm collects an expert dataset with privileged map data from diverse environments, ensuring comprehensive scenario coverage. By leveraging both the acquired expert and learner dataset gathered from the agent's interactions with the simulation environments, a robust reward function and policy are learned across diverse states. While the proposed method is trained in a simulation environment only, it can be directly applied to real-world scenarios without additional training or tuning. The performance of the proposed method is validated in both simulation and real-world environments, including forests and various structures. The trained policy achieves an average speed of 7 m/s and a maximum speed of 8.8 m/s in real flight experiments. To the best of our knowledge, this is the first work to successfully apply an IRL framework for high-speed visual navigation of drones.
MORDA: A Synthetic Dataset to Facilitate Adaptation of Object Detectors to Unseen Real-target Domain While Preserving Performance on Real-source Domain
Jan 09, 2025



Deep neural network (DNN) based perception models are indispensable in the development of autonomous vehicles (AVs). However, their reliance on large-scale, high-quality data is broadly recognized as a burdensome necessity due to the substantial cost of data acquisition and labeling. Further, the issue is not a one-time concern, as AVs might need a new dataset if they are to be deployed to another region (real-target domain) that the in-hand dataset within the real-source domain cannot incorporate. To mitigate this burden, we propose leveraging synthetic environments as an auxiliary domain where the characteristics of real domains are reproduced. This approach could enable indirect experience about the real-target domain in a time- and cost-effective manner. As a practical demonstration of our methodology, nuScenes and South Korea are employed to represent real-source and real-target domains, respectively. That means we construct digital twins for several regions of South Korea, and the data-acquisition framework of nuScenes is reproduced. Blending the aforementioned components within a simulator allows us to obtain a synthetic-fusion domain in which we forge our novel driving dataset, MORDA: Mixture Of Real-domain characteristics for synthetic-data-assisted Domain Adaptation. To verify the value of synthetic features that MORDA provides in learning about driving environments of South Korea, 2D/3D detectors are trained solely on a combination of nuScenes and MORDA. Afterward, their performance is evaluated on the unforeseen real-world dataset (AI-Hub) collected in South Korea. Our experiments present that MORDA can significantly improve mean Average Precision (mAP) on AI-Hub dataset while that on nuScenes is retained or slightly enhanced.
Meta-Controller: Few-Shot Imitation of Unseen Embodiments and Tasks in Continuous Control
Dec 10, 2024



Generalizing across robot embodiments and tasks is crucial for adaptive robotic systems. Modular policy learning approaches adapt to new embodiments but are limited to specific tasks, while few-shot imitation learning (IL) approaches often focus on a single embodiment. In this paper, we introduce a few-shot behavior cloning framework to simultaneously generalize to unseen embodiments and tasks using a few (\emph{e.g.,} five) reward-free demonstrations. Our framework leverages a joint-level input-output representation to unify the state and action spaces of heterogeneous embodiments and employs a novel structure-motion state encoder that is parameterized to capture both shared knowledge across all embodiments and embodiment-specific knowledge. A matching-based policy network then predicts actions from a few demonstrations, producing an adaptive policy that is robust to over-fitting. Evaluated in the DeepMind Control suite, our framework termed \modelname{} demonstrates superior few-shot generalization to unseen embodiments and tasks over modular policy learning and few-shot IL approaches. Codes are available at \href{https://github.com/SeongwoongCho/meta-controller}{https://github.com/SeongwoongCho/meta-controller}.
Dual Exposure Stereo for Extended Dynamic Range 3D Imaging
Dec 03, 2024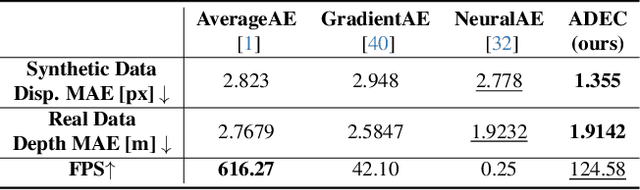
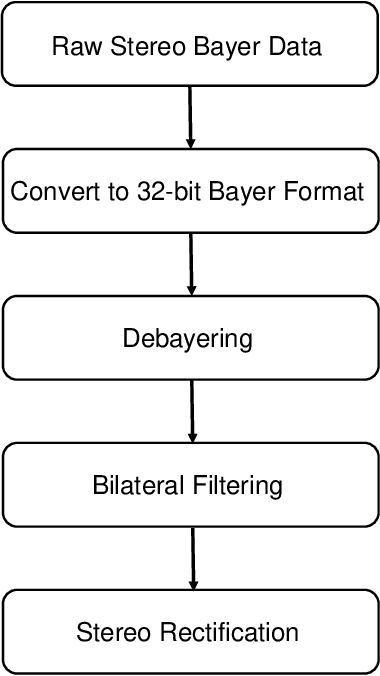

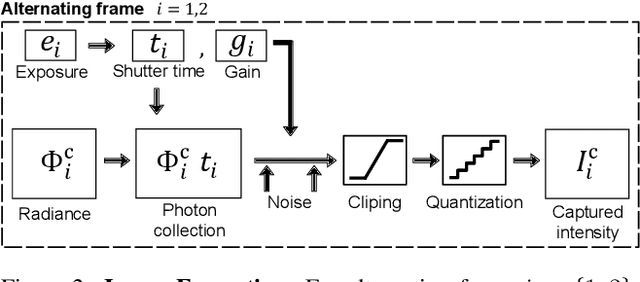
Achieving robust stereo 3D imaging under diverse illumination conditions is an important however challenging task, due to the limited dynamic ranges (DRs) of cameras, which are significantly smaller than real world DR. As a result, the accuracy of existing stereo depth estimation methods is often compromised by under- or over-exposed images. Here, we introduce dual-exposure stereo for extended dynamic range 3D imaging. We develop automatic dual-exposure control method that adjusts the dual exposures, diverging them when the scene DR exceeds the camera DR, thereby providing information about broader DR. From the captured dual-exposure stereo images, we estimate depth using motion-aware dual-exposure stereo network. To validate our method, we develop a robot-vision system, collect stereo video datasets, and generate a synthetic dataset. Our method outperforms other exposure control methods.
Do Captioning Metrics Reflect Music Semantic Alignment?
Nov 18, 2024Music captioning has emerged as a promising task, fueled by the advent of advanced language generation models. However, the evaluation of music captioning relies heavily on traditional metrics such as BLEU, METEOR, and ROUGE which were developed for other domains, without proper justification for their use in this new field. We present cases where traditional metrics are vulnerable to syntactic changes, and show they do not correlate well with human judgments. By addressing these issues, we aim to emphasize the need for a critical reevaluation of how music captions are assessed.
NVS-Adapter: Plug-and-Play Novel View Synthesis from a Single Image
Dec 12, 2023
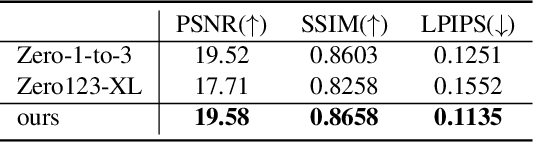
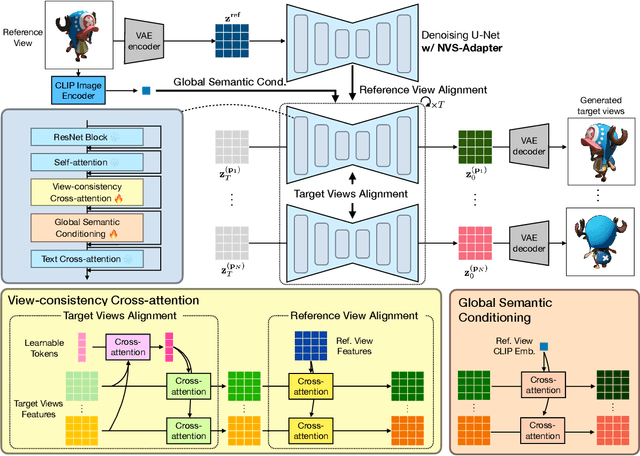
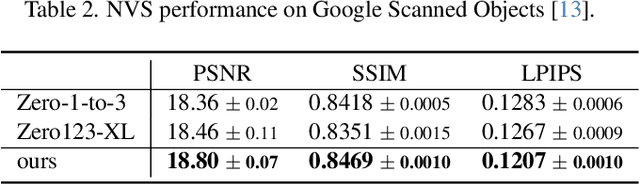
Transfer learning of large-scale Text-to-Image (T2I) models has recently shown impressive potential for Novel View Synthesis (NVS) of diverse objects from a single image. While previous methods typically train large models on multi-view datasets for NVS, fine-tuning the whole parameters of T2I models not only demands a high cost but also reduces the generalization capacity of T2I models in generating diverse images in a new domain. In this study, we propose an effective method, dubbed NVS-Adapter, which is a plug-and-play module for a T2I model, to synthesize novel multi-views of visual objects while fully exploiting the generalization capacity of T2I models. NVS-Adapter consists of two main components; view-consistency cross-attention learns the visual correspondences to align the local details of view features, and global semantic conditioning aligns the semantic structure of generated views with the reference view. Experimental results demonstrate that the NVS-Adapter can effectively synthesize geometrically consistent multi-views and also achieve high performance on benchmarks without full fine-tuning of T2I models. The code and data are publicly available in ~\href{https://postech-cvlab.github.io/nvsadapter/}{https://postech-cvlab.github.io/nvsadapter/}.