 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoppler Correspondence: Non-Iterative Scan Matching With Doppler Velocity-Based Correspondence
Feb 17, 2025

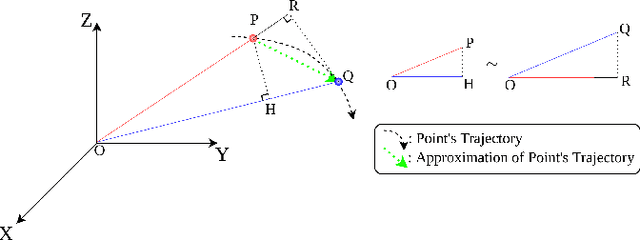

Achieving successful scan matching is essential for LiDAR odometry. However, in challenging environments with adverse weather conditions or repetitive geometric patterns, LiDAR odometry performance is degraded due to incorrect scan matching. Recently, the emergence of frequency-modulated continuous wave 4D LiDAR and 4D radar technologies has provided the potential to address these unfavorable conditions. The term 4D refers to point cloud data characterized by range, azimuth, and elevation along with Doppler velocity. Although 4D data is available, most scan matching methods for 4D LiDAR and 4D radar still establish correspondence by repeatedly identifying the closest points between consecutive scans, overlooking the Doppler information. This paper introduces, for the first time, a simple Doppler velocity-based correspondence -- Doppler Correspondence -- that is invariant to translation and small rotation of the sensor, with its geometric and kinematic foundations. Extensive experiments demonstrate that the proposed method enables the direct matching of consecutive point clouds without an iterative process, making it computationally efficient. Additionally, it provides a more robust correspondence estimation in environments with repetitive geometric patterns.
Kalman Filter-Based Distributed Gaussian Process for Unknown Scalar Field Estimation in Wireless Sensor Networks
Feb 09, 2025



In this letter, we propose an online scalar field estimation algorithm of unknown environments using a distributed Gaussian process (DGP) framework in wireless sensor networks (WSNs). While the kernel-based Gaussian process (GP) has been widely employed for estimating unknown scalar fields, its centralized nature is not well-suited for handling a large amount of data from WSNs. To overcome the limitations of the kernel-based GP, recent advancements in GP research focus on approximating kernel functions as products of E-dimensional nonlinear basis functions, which can handle large WSNs more efficiently in a distributed manner. However, this approach requires a large number of basis functions for accurate approximation, leading to increased computational and communication complexities. To address these complexity issues, the paper proposes a distributed GP framework by incorporating a Kalman filter scheme (termed as K-DGP), which scales linearly with the number of nonlinear basis functions. Moreover, we propose a new consensus protocol designed to handle the unique data transmission requirement residing in the proposed K-DGP framework. This protocol preserves the inherent elements in the form of a certain column in the nonlinear function matrix of the communicated message; it enables wireless sensors to cooperatively estimate the environment and reach the global consensus through distributed learning with faster convergence than the widely-used average consensus protocol. Simulation results demonstrate rapid consensus convergence and outstanding estimation accuracy achieved by the proposed K-DGP algorithm. The scalability and efficiency of the proposed approach are further demonstrated by online dynamic environment estimation using WSNs.
RAPID: Robust and Agile Planner Using Inverse Reinforcement Learning for Vision-Based Drone Navigation
Feb 04, 2025This paper introduces a learning-based visual planner for agile drone flight in cluttered environments. The proposed planner generates collision-free waypoints in milliseconds, enabling drones to perform agile maneuvers in complex environments without building separate perception, mapping, and planning modules. Learning-based methods, such as behavior cloning (BC) and reinforcement learning (RL), demonstrate promising performance in visual navigation but still face inherent limitations. BC is susceptible to compounding errors due to limited expert imitation, while RL struggles with reward function design and sample inefficiency. To address these limitations, this paper proposes an inverse reinforcement learning (IRL)-based framework for high-speed visual navigation. By leveraging IRL, it is possible to reduce the number of interactions with simulation environments and improve capability to deal with high-dimensional spaces while preserving the robustness of RL policies. A motion primitive-based path planning algorithm collects an expert dataset with privileged map data from diverse environments, ensuring comprehensive scenario coverage. By leveraging both the acquired expert and learner dataset gathered from the agent's interactions with the simulation environments, a robust reward function and policy are learned across diverse states. While the proposed method is trained in a simulation environment only, it can be directly applied to real-world scenarios without additional training or tuning. The performance of the proposed method is validated in both simulation and real-world environments, including forests and various structures. The trained policy achieves an average speed of 7 m/s and a maximum speed of 8.8 m/s in real flight experiments. To the best of our knowledge, this is the first work to successfully apply an IRL framework for high-speed visual navigation of drones.