 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoppler Correspondence: Non-Iterative Scan Matching With Doppler Velocity-Based Correspondence
Feb 17, 2025

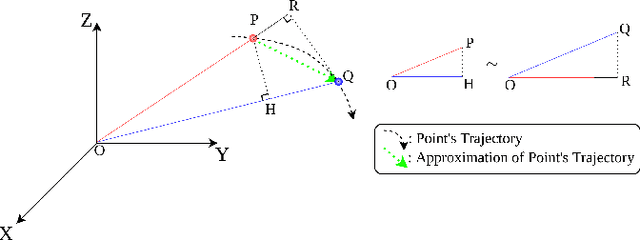

Achieving successful scan matching is essential for LiDAR odometry. However, in challenging environments with adverse weather conditions or repetitive geometric patterns, LiDAR odometry performance is degraded due to incorrect scan matching. Recently, the emergence of frequency-modulated continuous wave 4D LiDAR and 4D radar technologies has provided the potential to address these unfavorable conditions. The term 4D refers to point cloud data characterized by range, azimuth, and elevation along with Doppler velocity. Although 4D data is available, most scan matching methods for 4D LiDAR and 4D radar still establish correspondence by repeatedly identifying the closest points between consecutive scans, overlooking the Doppler information. This paper introduces, for the first time, a simple Doppler velocity-based correspondence -- Doppler Correspondence -- that is invariant to translation and small rotation of the sensor, with its geometric and kinematic foundations. Extensive experiments demonstrate that the proposed method enables the direct matching of consecutive point clouds without an iterative process, making it computationally efficient. Additionally, it provides a more robust correspondence estimation in environments with repetitive geometric patterns.
RAPID: Robust and Agile Planner Using Inverse Reinforcement Learning for Vision-Based Drone Navigation
Feb 04, 2025This paper introduces a learning-based visual planner for agile drone flight in cluttered environments. The proposed planner generates collision-free waypoints in milliseconds, enabling drones to perform agile maneuvers in complex environments without building separate perception, mapping, and planning modules. Learning-based methods, such as behavior cloning (BC) and reinforcement learning (RL), demonstrate promising performance in visual navigation but still face inherent limitations. BC is susceptible to compounding errors due to limited expert imitation, while RL struggles with reward function design and sample inefficiency. To address these limitations, this paper proposes an inverse reinforcement learning (IRL)-based framework for high-speed visual navigation. By leveraging IRL, it is possible to reduce the number of interactions with simulation environments and improve capability to deal with high-dimensional spaces while preserving the robustness of RL policies. A motion primitive-based path planning algorithm collects an expert dataset with privileged map data from diverse environments, ensuring comprehensive scenario coverage. By leveraging both the acquired expert and learner dataset gathered from the agent's interactions with the simulation environments, a robust reward function and policy are learned across diverse states. While the proposed method is trained in a simulation environment only, it can be directly applied to real-world scenarios without additional training or tuning. The performance of the proposed method is validated in both simulation and real-world environments, including forests and various structures. The trained policy achieves an average speed of 7 m/s and a maximum speed of 8.8 m/s in real flight experiments. To the best of our knowledge, this is the first work to successfully apply an IRL framework for high-speed visual navigation of drones.
LoL-PIM: Long-Context LLM Decoding with Scalable DRAM-PIM System
Dec 28, 2024



The expansion of large language models (LLMs) with hundreds of billions of parameters presents significant challenges to computational resources, particularly data movement and memory bandwidth. Long-context LLMs, which process sequences of tens of thousands of tokens, further increase the demand on the memory system as the complexity in attention layers and key-value cache sizes is proportional to the context length. Processing-in-Memory (PIM) maximizes memory bandwidth by moving compute to the data and can address the memory bandwidth challenges; however, PIM is not necessarily scalable to accelerate long-context LLM because of limited per-module memory capacity and the inflexibility of fixed-functional unit PIM architecture and static memory management. In this work, we propose LoL-PIM which is a multi-node PIM architecture that accelerates long context LLM through hardware-software co-design. In particular, we propose how pipeline parallelism can be exploited across a multi-PIM module while a direct PIM access (DPA) controller (or DMA for PIM) is proposed that enables dynamic PIM memory management and results in efficient PIM utilization across a diverse range of context length. We developed an MLIR-based compiler for LoL-PIM extending a commercial PIM-based compiler where the software modifications were implemented and evaluated, while the hardware changes were modeled in the simulator. Our evaluations demonstrate that LoL-PIM significantly improves throughput and reduces latency for long-context LLM inference, outperforming both multi-GPU and GPU-PIM systems (up to 8.54x and 16.0x speedup, respectively), thereby enabling more efficient deployment of LLMs in real-world applications.