 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Point Cloud Geometry as a Statistical Manifold: Theory and Practice
May 11, 2026Point clouds are a fundamental representation for robotic perception tasks such as localization, mapping, and object pose estimation. However, LiDAR-acquired point clouds are inherently sparse and non-uniform, providing incomplete observations of the underlying scene geometry. This makes reliable geometric reasoning challenging and degrades downstream perception performance. Existing approaches attempt to compensate for these limitations by estimating local geometry, but often rely on hand-crafted statistics or end-to-end supervised learning, which can suffer from limited scalability or require large amounts of accurately labeled data. To address these challenges, we explicitly model point cloud geometry under a principled mathematical formulation. We represent local geometry as a statistical manifold induced by a family of Gaussian distributions, where each point is associated with a Gaussian capturing its local geometric structure. Based on this formulation, we introduce Point-to-Ellipsoid (POLI), a deep neural estimator that predicts per-point Gaussian geometry. POLI learns a mapping from point cloud observations to their underlying geometry in a self-supervised manner, removing the need for labeled data while preserving strong geometric inductive biases. The resulting representation integrates seamlessly into existing robotic perception pipelines without architectural modifications. Extensive experiments show that POLI enables accurate and robust geometry estimation and consistently improves performance across diverse robotic perception tasks.
LLaViDA: A Large Language Vision Driving Assistant for Explicit Reasoning and Enhanced Trajectory Planning
Dec 20, 2025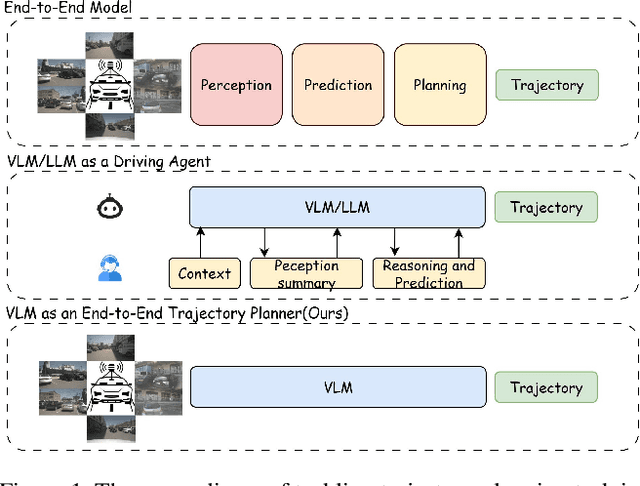
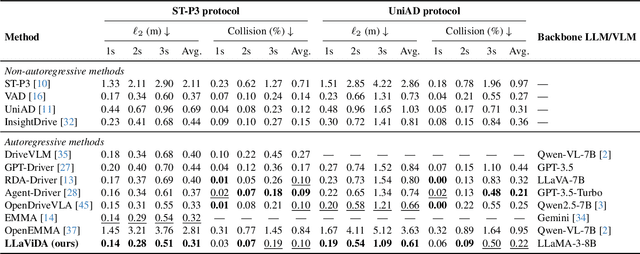
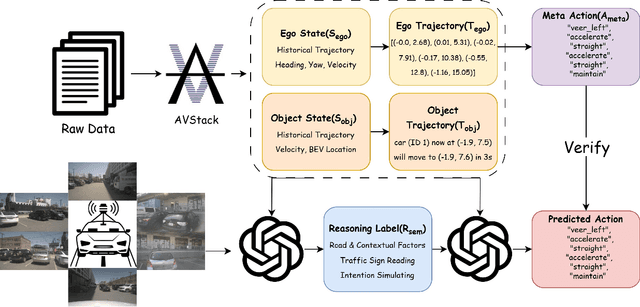
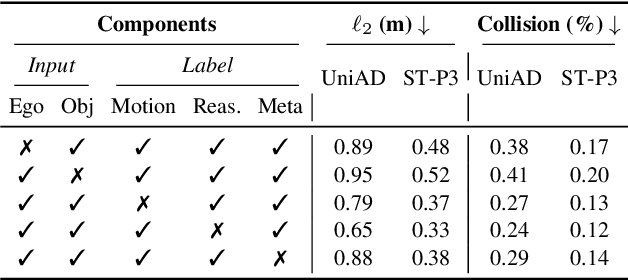
Trajectory planning is a fundamental yet challenging component of autonomous driving. End-to-end planners frequently falter under adverse weather, unpredictable human behavior, or complex road layouts, primarily because they lack strong generalization or few-shot capabilities beyond their training data. We propose LLaViDA, a Large Language Vision Driving Assistant that leverages a Vision-Language Model (VLM) for object motion prediction, semantic grounding, and chain-of-thought reasoning for trajectory planning in autonomous driving. A two-stage training pipeline--supervised fine-tuning followed by Trajectory Preference Optimization (TPO)--enhances scene understanding and trajectory planning by injecting regression-based supervision, produces a powerful "VLM Trajectory Planner for Autonomous Driving." On the NuScenes benchmark, LLaViDA surpasses state-of-the-art end-to-end and other recent VLM/LLM-based baselines in open-loop trajectory planning task, achieving an average L2 trajectory error of 0.31 m and a collision rate of 0.10% on the NuScenes test set. The code for this paper is available at GitHub.
Doppler Correspondence: Non-Iterative Scan Matching With Doppler Velocity-Based Correspondence
Feb 17, 2025

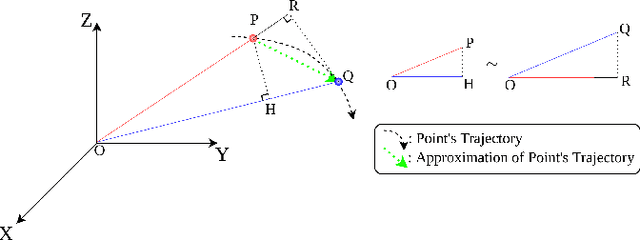

Achieving successful scan matching is essential for LiDAR odometry. However, in challenging environments with adverse weather conditions or repetitive geometric patterns, LiDAR odometry performance is degraded due to incorrect scan matching. Recently, the emergence of frequency-modulated continuous wave 4D LiDAR and 4D radar technologies has provided the potential to address these unfavorable conditions. The term 4D refers to point cloud data characterized by range, azimuth, and elevation along with Doppler velocity. Although 4D data is available, most scan matching methods for 4D LiDAR and 4D radar still establish correspondence by repeatedly identifying the closest points between consecutive scans, overlooking the Doppler information. This paper introduces, for the first time, a simple Doppler velocity-based correspondence -- Doppler Correspondence -- that is invariant to translation and small rotation of the sensor, with its geometric and kinematic foundations. Extensive experiments demonstrate that the proposed method enables the direct matching of consecutive point clouds without an iterative process, making it computationally efficient. Additionally, it provides a more robust correspondence estimation in environments with repetitive geometric patterns.
An Investigation of FP8 Across Accelerators for LLM Inference
Feb 03, 2025



The introduction of 8-bit floating-point (FP8) computation units in modern AI accelerators has generated significant interest in FP8-based large language model (LLM) inference. Unlike 16-bit floating-point formats, FP8 in deep learning requires a shared scaling factor. Additionally, while E4M3 and E5M2 are well-defined at the individual value level, their scaling and accumulation methods remain unspecified and vary across hardware and software implementations. As a result, FP8 behaves more like a quantization format than a standard numeric representation. In this work, we provide the first comprehensive analysis of FP8 computation and acceleration on two AI accelerators: the NVIDIA H100 and Intel Gaudi 2. Our findings highlight that the Gaudi 2, by leveraging FP8, achieves higher throughput-to-power efficiency during LLM inference, offering valuable insights into the practical implications of FP8 adoption for datacenter-scale LLM serving.
Wikibench: Community-Driven Data Curation for AI Evaluation on Wikipedia
Feb 21, 2024AI tools are increasingly deployed in community contexts. However, datasets used to evaluate AI are typically created by developers and annotators outside a given community, which can yield misleading conclusions about AI performance. How might we empower communities to drive the intentional design and curation of evaluation datasets for AI that impacts them? We investigate this question on Wikipedia, an online community with multiple AI-based content moderation tools deployed. We introduce Wikibench, a system that enables communities to collaboratively curate AI evaluation datasets, while navigating ambiguities and differences in perspective through discussion. A field study on Wikipedia shows that datasets curated using Wikibench can effectively capture community consensus, disagreement, and uncertainty. Furthermore, study participants used Wikibench to shape the overall data curation process, including refining label definitions, determining data inclusion criteria, and authoring data statements. Based on our findings, we propose future directions for systems that support community-driven data curation.
Denoising Heat-inspired Diffusion with Insulators for Collision Free Motion Planning
Oct 19, 2023



Diffusion models have risen as a powerful tool in robotics due to their flexibility and multi-modality. While some of these methods effectively address complex problems, they often depend heavily on inference-time obstacle detection and require additional equipment. Addressing these challenges, we present a method that, during inference time, simultaneously generates only reachable goals and plans motions that avoid obstacles, all from a single visual input. Central to our approach is the novel use of a collision-avoiding diffusion kernel for training. Through evaluations against behavior-cloning and classical diffusion models, our framework has proven its robustness. It is particularly effective in multi-modal environments, navigating toward goals and avoiding unreachable ones blocked by obstacles, while ensuring collision avoidance.
Diffusion-EDFs: Bi-equivariant Denoising Generative Modeling on SE(3) for Visual Robotic Manipulation
Sep 07, 2023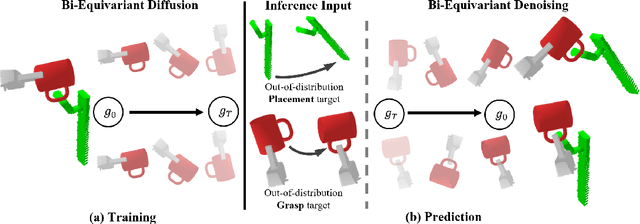



Recent studies have verified that equivariant methods can significantly improve the data efficiency, generalizability, and robustness in robot learning. Meanwhile, denoising diffusion-based generative modeling has recently gained significant attention as a promising approach for robotic manipulation learning from demonstrations with stochastic behaviors. In this paper, we present Diffusion-EDFs, a novel approach that incorporates spatial roto-translation equivariance, i.e., SE(3)-equivariance to diffusion generative modeling. By integrating SE(3)-equivariance into our model architectures, we demonstrate that our proposed method exhibits remarkable data efficiency, requiring only 5 to 10 task demonstrations for effective end-to-end training. Furthermore, our approach showcases superior generalizability compared to previous diffusion-based manipulation methods.