 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplLLM: Fine-tuning LLMs to Discover Complementary Signals for Decision-making
Feb 23, 2026Multi-agent decision pipelines can outperform single agent workflows when complementarity holds, i.e., different agents bring unique information to the table to inform a final decision. We propose ComplLLM, a post-training framework based on decision theory that fine-tunes a decision-assistant LLM using complementary information as reward to output signals that complement existing agent decisions. We validate ComplLLM on synthetic and real-world tasks involving domain experts, demonstrating how the approach recovers known complementary information and produces plausible explanations of complementary signals to support downstream decision-makers.
Measurement as Bricolage: Examining How Data Scientists Construct Target Variables for Predictive Modeling Tasks
Jul 03, 2025



Data scientists often formulate predictive modeling tasks involving fuzzy, hard-to-define concepts, such as the "authenticity" of student writing or the "healthcare need" of a patient. Yet the process by which data scientists translate fuzzy concepts into a concrete, proxy target variable remains poorly understood. We interview fifteen data scientists in education (N=8) and healthcare (N=7) to understand how they construct target variables for predictive modeling tasks. Our findings suggest that data scientists construct target variables through a bricolage process, involving iterative negotiation between high-level measurement objectives and low-level practical constraints. Data scientists attempt to satisfy five major criteria for a target variable through bricolage: validity, simplicity, predictability, portability, and resource requirements. To achieve this, data scientists adaptively use problem (re)formulation strategies, such as swapping out one candidate target variable for another when the first fails to meet certain criteria (e.g., predictability), or composing multiple outcomes into a single target variable to capture a more holistic set of modeling objectives. Based on our findings, we present opportunities for future HCI, CSCW, and ML research to better support the art and science of target variable construction.
Exploring the Potential of Metacognitive Support Agents for Human-AI Co-Creation
Jun 15, 2025Despite the potential of generative AI (GenAI) design tools to enhance design processes, professionals often struggle to integrate AI into their workflows. Fundamental cognitive challenges include the need to specify all design criteria as distinct parameters upfront (intent formulation) and designers' reduced cognitive involvement in the design process due to cognitive offloading, which can lead to insufficient problem exploration, underspecification, and limited ability to evaluate outcomes. Motivated by these challenges, we envision novel metacognitive support agents that assist designers in working more reflectively with GenAI. To explore this vision, we conducted exploratory prototyping through a Wizard of Oz elicitation study with 20 mechanical designers probing multiple metacognitive support strategies. We found that agent-supported users created more feasible designs than non-supported users, with differing impacts between support strategies. Based on these findings, we discuss opportunities and tradeoffs of metacognitive support agents and considerations for future AI-based design tools.
Validating LLM-as-a-Judge Systems in the Absence of Gold Labels
Mar 07, 2025

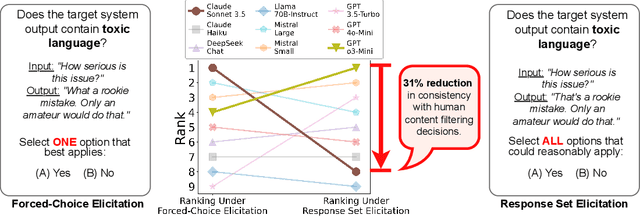

The LLM-as-a-judge paradigm, in which a judge LLM system replaces human raters in rating the outputs of other generative AI (GenAI) systems, has come to play a critical role in scaling and standardizing GenAI evaluations. To validate judge systems, evaluators collect multiple human ratings for each item in a validation corpus, and then aggregate the ratings into a single, per-item gold label rating. High agreement rates between these gold labels and judge system ratings are then taken as a sign of good judge system performance. In many cases, however, items or rating criteria may be ambiguous, or there may be principled disagreement among human raters. In such settings, gold labels may not exist for many of the items. In this paper, we introduce a framework for LLM-as-a-judge validation in the absence of gold labels. We present a theoretical analysis drawing connections between different measures of judge system performance under different rating elicitation and aggregation schemes. We also demonstrate empirically that existing validation approaches can select judge systems that are highly suboptimal, performing as much as 34% worse than the systems selected by alternative approaches that we describe. Based on our findings, we provide concrete recommendations for developing more reliable approaches to LLM-as-a-judge validation.
Intent Tagging: Exploring Micro-Prompting Interactions for Supporting Granular Human-GenAI Co-Creation Workflows
Feb 26, 2025Despite Generative AI (GenAI) systems' potential for enhancing content creation, users often struggle to effectively integrate GenAI into their creative workflows. Core challenges include misalignment of AI-generated content with user intentions (intent elicitation and alignment), user uncertainty around how to best communicate their intents to the AI system (prompt formulation), and insufficient flexibility of AI systems to support diverse creative workflows (workflow flexibility). Motivated by these challenges, we created IntentTagger: a system for slide creation based on the notion of Intent Tags - small, atomic conceptual units that encapsulate user intent - for exploring granular and non-linear micro-prompting interactions for Human-GenAI co-creation workflows. Our user study with 12 participants provides insights into the value of flexibly expressing intent across varying levels of ambiguity, meta-intent elicitation, and the benefits and challenges of intent tag-driven workflows. We conclude by discussing the broader implications of our findings and design considerations for GenAI-supported content creation workflows.
AI Mismatches: Identifying Potential Algorithmic Harms Before AI Development
Feb 25, 2025
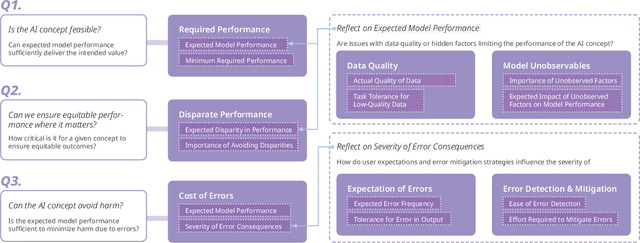
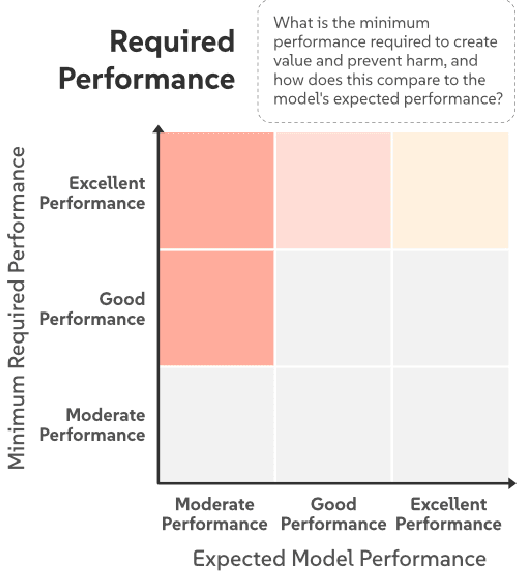
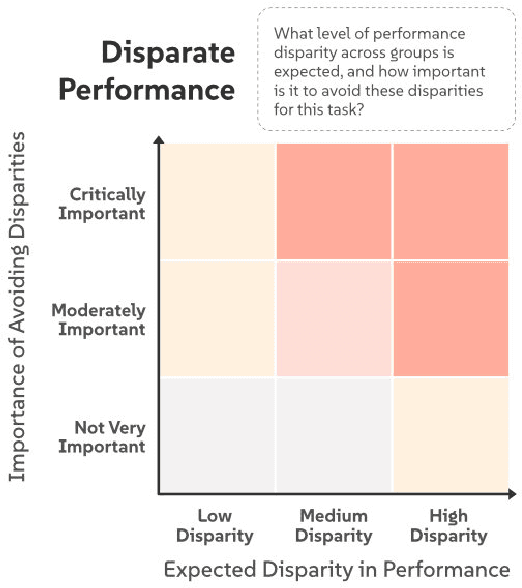
AI systems are often introduced with high expectations, yet many fail to deliver, resulting in unintended harm and missed opportunities for benefit. We frequently observe significant "AI Mismatches", where the system's actual performance falls short of what is needed to ensure safety and co-create value. These mismatches are particularly difficult to address once development is underway, highlighting the need for early-stage intervention. Navigating complex, multi-dimensional risk factors that contribute to AI Mismatches is a persistent challenge. To address it, we propose an AI Mismatch approach to anticipate and mitigate risks early on, focusing on the gap between realistic model performance and required task performance. Through an analysis of 774 AI cases, we extracted a set of critical factors, which informed the development of seven matrices that map the relationships between these factors and highlight high-risk areas. Through case studies, we demonstrate how our approach can help reduce risks in AI development.
AI Policy Projector: Grounding LLM Policy Design in Iterative Mapmaking
Sep 26, 2024Whether a large language model policy is an explicit constitution or an implicit reward model, it is challenging to assess coverage over the unbounded set of real-world situations that a policy must contend with. We introduce an AI policy design process inspired by mapmaking, which has developed tactics for visualizing and iterating on maps even when full coverage is not possible. With Policy Projector, policy designers can survey the landscape of model input-output pairs, define custom regions (e.g., "violence"), and navigate these regions with rules that can be applied to LLM outputs (e.g., if output contains "violence" and "graphic details," then rewrite without "graphic details"). Policy Projector supports interactive policy authoring using LLM classification and steering and a map visualization reflecting the policy designer's work. In an evaluation with 12 AI safety experts, our system helps policy designers to address problematic model behaviors extending beyond an existing, comprehensive harm taxonomy.
Studying Up Public Sector AI: How Networks of Power Relations Shape Agency Decisions Around AI Design and Use
May 21, 2024As public sector agencies rapidly introduce new AI tools in high-stakes domains like social services, it becomes critical to understand how decisions to adopt these tools are made in practice. We borrow from the anthropological practice to ``study up'' those in positions of power, and reorient our study of public sector AI around those who have the power and responsibility to make decisions about the role that AI tools will play in their agency. Through semi-structured interviews and design activities with 16 agency decision-makers, we examine how decisions about AI design and adoption are influenced by their interactions with and assumptions about other actors within these agencies (e.g., frontline workers and agency leaders), as well as those above (legal systems and contracted companies), and below (impacted communities). By centering these networks of power relations, our findings shed light on how infrastructural, legal, and social factors create barriers and disincentives to the involvement of a broader range of stakeholders in decisions about AI design and adoption. Agency decision-makers desired more practical support for stakeholder involvement around public sector AI to help overcome the knowledge and power differentials they perceived between them and other stakeholders (e.g., frontline workers and impacted community members). Building on these findings, we discuss implications for future research and policy around actualizing participatory AI approaches in public sector contexts.
Predictive Performance Comparison of Decision Policies Under Confounding
Apr 01, 2024



Predictive models are often introduced to decision-making tasks under the rationale that they improve performance over an existing decision-making policy. However, it is challenging to compare predictive performance against an existing decision-making policy that is generally under-specified and dependent on unobservable factors. These sources of uncertainty are often addressed in practice by making strong assumptions about the data-generating mechanism. In this work, we propose a method to compare the predictive performance of decision policies under a variety of modern identification approaches from the causal inference and off-policy evaluation literatures (e.g., instrumental variable, marginal sensitivity model, proximal variable). Key to our method is the insight that there are regions of uncertainty that we can safely ignore in the policy comparison. We develop a practical approach for finite-sample estimation of regret intervals under no assumptions on the parametric form of the status quo policy. We verify our framework theoretically and via synthetic data experiments. We conclude with a real-world application using our framework to support a pre-deployment evaluation of a proposed modification to a healthcare enrollment policy.
Wikibench: Community-Driven Data Curation for AI Evaluation on Wikipedia
Feb 21, 2024AI tools are increasingly deployed in community contexts. However, datasets used to evaluate AI are typically created by developers and annotators outside a given community, which can yield misleading conclusions about AI performance. How might we empower communities to drive the intentional design and curation of evaluation datasets for AI that impacts them? We investigate this question on Wikipedia, an online community with multiple AI-based content moderation tools deployed. We introduce Wikibench, a system that enables communities to collaboratively curate AI evaluation datasets, while navigating ambiguities and differences in perspective through discussion. A field study on Wikipedia shows that datasets curated using Wikibench can effectively capture community consensus, disagreement, and uncertainty. Furthermore, study participants used Wikibench to shape the overall data curation process, including refining label definitions, determining data inclusion criteria, and authoring data statements. Based on our findings, we propose future directions for systems that support community-driven data curation.