 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasurement as Bricolage: Examining How Data Scientists Construct Target Variables for Predictive Modeling Tasks
Jul 03, 2025



Data scientists often formulate predictive modeling tasks involving fuzzy, hard-to-define concepts, such as the "authenticity" of student writing or the "healthcare need" of a patient. Yet the process by which data scientists translate fuzzy concepts into a concrete, proxy target variable remains poorly understood. We interview fifteen data scientists in education (N=8) and healthcare (N=7) to understand how they construct target variables for predictive modeling tasks. Our findings suggest that data scientists construct target variables through a bricolage process, involving iterative negotiation between high-level measurement objectives and low-level practical constraints. Data scientists attempt to satisfy five major criteria for a target variable through bricolage: validity, simplicity, predictability, portability, and resource requirements. To achieve this, data scientists adaptively use problem (re)formulation strategies, such as swapping out one candidate target variable for another when the first fails to meet certain criteria (e.g., predictability), or composing multiple outcomes into a single target variable to capture a more holistic set of modeling objectives. Based on our findings, we present opportunities for future HCI, CSCW, and ML research to better support the art and science of target variable construction.
Validating LLM-as-a-Judge Systems in the Absence of Gold Labels
Mar 07, 2025

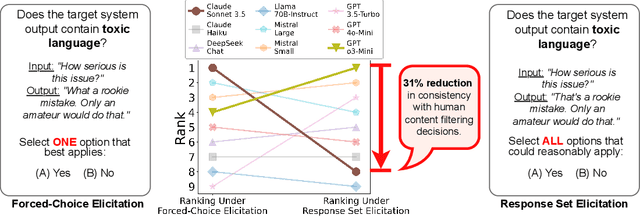

The LLM-as-a-judge paradigm, in which a judge LLM system replaces human raters in rating the outputs of other generative AI (GenAI) systems, has come to play a critical role in scaling and standardizing GenAI evaluations. To validate judge systems, evaluators collect multiple human ratings for each item in a validation corpus, and then aggregate the ratings into a single, per-item gold label rating. High agreement rates between these gold labels and judge system ratings are then taken as a sign of good judge system performance. In many cases, however, items or rating criteria may be ambiguous, or there may be principled disagreement among human raters. In such settings, gold labels may not exist for many of the items. In this paper, we introduce a framework for LLM-as-a-judge validation in the absence of gold labels. We present a theoretical analysis drawing connections between different measures of judge system performance under different rating elicitation and aggregation schemes. We also demonstrate empirically that existing validation approaches can select judge systems that are highly suboptimal, performing as much as 34% worse than the systems selected by alternative approaches that we describe. Based on our findings, we provide concrete recommendations for developing more reliable approaches to LLM-as-a-judge validation.
A Framework for Evaluating LLMs Under Task Indeterminacy
Nov 21, 2024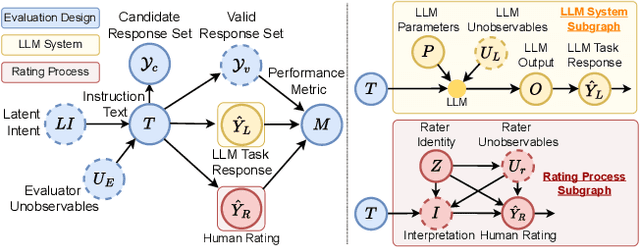
Large language model (LLM) evaluations often assume there is a single correct response -- a gold label -- for each item in the evaluation corpus. However, some tasks can be ambiguous -- i.e., they provide insufficient information to identify a unique interpretation -- or vague -- i.e., they do not clearly indicate where to draw the line when making a determination. Both ambiguity and vagueness can cause task indeterminacy -- the condition where some items in the evaluation corpus have more than one correct response. In this paper, we develop a framework for evaluating LLMs under task indeterminacy. Our framework disentangles the relationships between task specification, human ratings, and LLM responses in the LLM evaluation pipeline. Using our framework, we conduct a synthetic experiment showing that evaluations that use the "gold label" assumption underestimate the true performance. We also provide a method for estimating an error-adjusted performance interval given partial knowledge about indeterminate items in the evaluation corpus. We conclude by outlining implications of our work for the research community.
Predictive Performance Comparison of Decision Policies Under Confounding
Apr 01, 2024



Predictive models are often introduced to decision-making tasks under the rationale that they improve performance over an existing decision-making policy. However, it is challenging to compare predictive performance against an existing decision-making policy that is generally under-specified and dependent on unobservable factors. These sources of uncertainty are often addressed in practice by making strong assumptions about the data-generating mechanism. In this work, we propose a method to compare the predictive performance of decision policies under a variety of modern identification approaches from the causal inference and off-policy evaluation literatures (e.g., instrumental variable, marginal sensitivity model, proximal variable). Key to our method is the insight that there are regions of uncertainty that we can safely ignore in the policy comparison. We develop a practical approach for finite-sample estimation of regret intervals under no assumptions on the parametric form of the status quo policy. We verify our framework theoretically and via synthetic data experiments. We conclude with a real-world application using our framework to support a pre-deployment evaluation of a proposed modification to a healthcare enrollment policy.
Training Towards Critical Use: Learning to Situate AI Predictions Relative to Human Knowledge
Aug 30, 2023



A growing body of research has explored how to support humans in making better use of AI-based decision support, including via training and onboarding. Existing research has focused on decision-making tasks where it is possible to evaluate "appropriate reliance" by comparing each decision against a ground truth label that cleanly maps to both the AI's predictive target and the human decision-maker's goals. However, this assumption does not hold in many real-world settings where AI tools are deployed today (e.g., social work, criminal justice, and healthcare). In this paper, we introduce a process-oriented notion of appropriate reliance called critical use that centers the human's ability to situate AI predictions against knowledge that is uniquely available to them but unavailable to the AI model. To explore how training can support critical use, we conduct a randomized online experiment in a complex social decision-making setting: child maltreatment screening. We find that, by providing participants with accelerated, low-stakes opportunities to practice AI-assisted decision-making in this setting, novices came to exhibit patterns of disagreement with AI that resemble those of experienced workers. A qualitative examination of participants' explanations for their AI-assisted decisions revealed that they drew upon qualitative case narratives, to which the AI model did not have access, to learn when (not) to rely on AI predictions. Our findings open new questions for the study and design of training for real-world AI-assisted decision-making.
Counterfactual Prediction Under Outcome Measurement Error
Feb 22, 2023Across domains such as medicine, employment, and criminal justice, predictive models often target labels that imperfectly reflect the outcomes of interest to experts and policymakers. For example, clinical risk assessments deployed to inform physician decision-making often predict measures of healthcare utilization (e.g., costs, hospitalization) as a proxy for patient medical need. These proxies can be subject to outcome measurement error when they systematically differ from the target outcome they are intended to measure. However, prior modeling efforts to characterize and mitigate outcome measurement error overlook the fact that the decision being informed by a model often serves as a risk-mitigating intervention that impacts the target outcome of interest and its recorded proxy. Thus, in these settings, addressing measurement error requires counterfactual modeling of treatment effects on outcomes. In this work, we study intersectional threats to model reliability introduced by outcome measurement error, treatment effects, and selection bias from historical decision-making policies. We develop an unbiased risk minimization method which, given knowledge of proxy measurement error properties, corrects for the combined effects of these challenges. We also develop a method for estimating treatment-dependent measurement error parameters when these are unknown in advance. We demonstrate the utility of our approach theoretically and via experiments on real-world data from randomized controlled trials conducted in healthcare and employment domains. As importantly, we demonstrate that models correcting for outcome measurement error or treatment effects alone suffer from considerable reliability limitations. Our work underscores the importance of considering intersectional threats to model validity during the design and evaluation of predictive models for decision support.
Ground Truth: A Causal Framework for Proxy Labels in Human-Algorithm Decision-Making
Feb 22, 2023
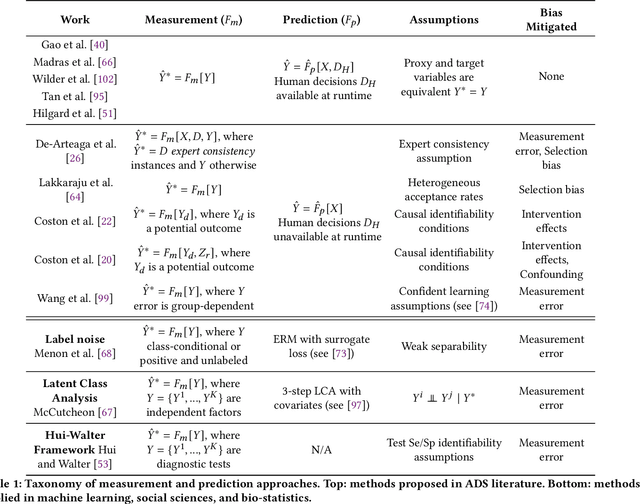
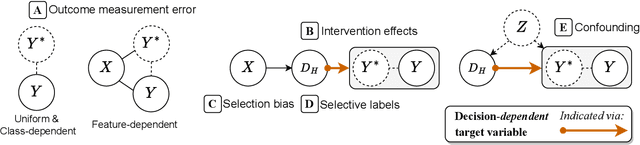
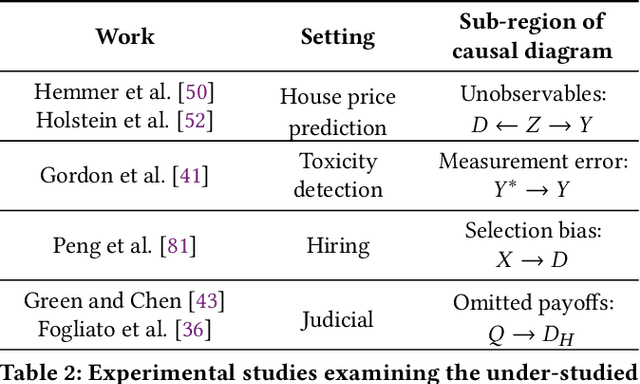
A growing literature on human-AI decision-making investigates strategies for combining human judgment with statistical models to improve decision-making. Research in this area often evaluates proposed improvements to models, interfaces, or workflows by demonstrating improved predictive performance on "ground truth" labels. However, this practice overlooks a key difference between human judgments and model predictions. Whereas humans reason about broader phenomena of interest in a decision -- including latent constructs that are not directly observable, such as disease status, the "toxicity" of online comments, or future "job performance" -- predictive models target proxy labels that are readily available in existing datasets. Predictive models' reliance on simplistic proxies makes them vulnerable to various sources of statistical bias. In this paper, we identify five sources of target variable bias that can impact the validity of proxy labels in human-AI decision-making tasks. We develop a causal framework to disentangle the relationship between each bias and clarify which are of concern in specific human-AI decision-making tasks. We demonstrate how our framework can be used to articulate implicit assumptions made in prior modeling work, and we recommend evaluation strategies for verifying whether these assumptions hold in practice. We then leverage our framework to re-examine the designs of prior human subjects experiments that investigate human-AI decision-making, finding that only a small fraction of studies examine factors related to target variable bias. We conclude by discussing opportunities to better address target variable bias in future research.
Decentralized Robot Learning for Personalization and Privacy
Jan 14, 2022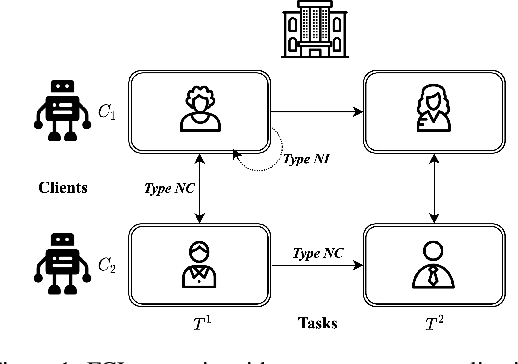


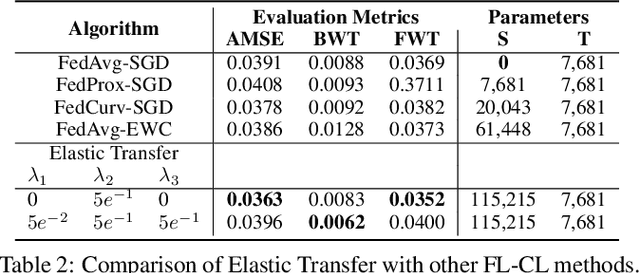
From learning assistance to companionship, social robots promise to enhance many aspects of daily life. However, social robots have not seen widespread adoption, in part because (1) they do not adapt their behavior to new users, and (2) they do not provide sufficient privacy protections. Centralized learning, whereby robots develop skills by gathering data on a server, contributes to these limitations by preventing online learning of new experiences and requiring storage of privacy-sensitive data. In this work, we propose a decentralized learning alternative that improves the privacy and personalization of social robots. We combine two machine learning approaches, Federated Learning and Continual Learning, to capture interaction dynamics distributed physically across robots and temporally across repeated robot encounters. We define a set of criteria that should be balanced in decentralized robot learning scenarios. We also develop a new algorithm -- Elastic Transfer -- that leverages importance-based regularization to preserve relevant parameters across robots and interactions with multiple humans. We show that decentralized learning is a viable alternative to centralized learning in a proof-of-concept Socially-Aware Navigation domain, and demonstrate how Elastic Transfer improves several of the proposed criteria.
Toward Affective XAI: Facial Affect Analysis for Understanding Explainable Human-AI Interactions
Jun 16, 2021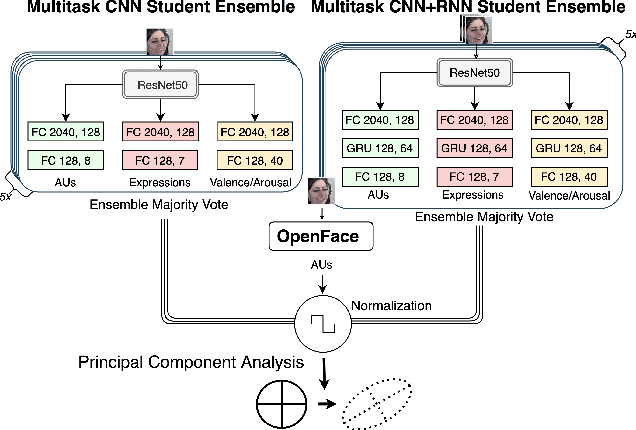
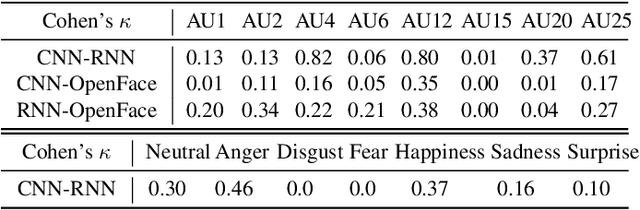
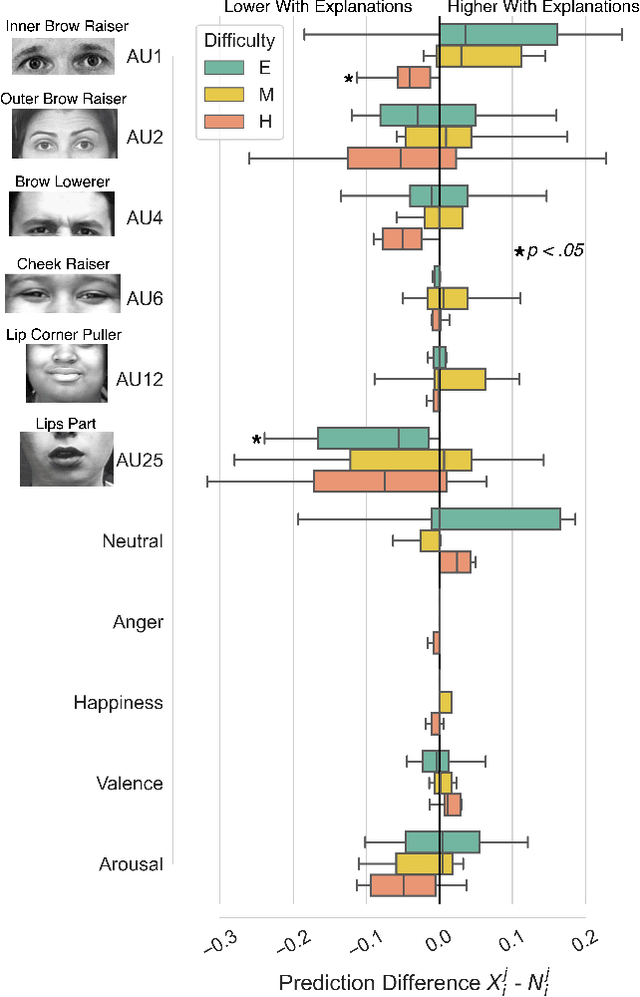
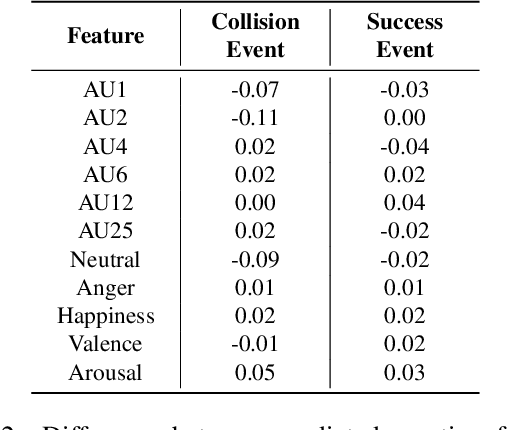
As machine learning approaches are increasingly used to augment human decision-making, eXplainable Artificial Intelligence (XAI) research has explored methods for communicating system behavior to humans. However, these approaches often fail to account for the emotional responses of humans as they interact with explanations. Facial affect analysis, which examines human facial expressions of emotions, is one promising lens for understanding how users engage with explanations. Therefore, in this work, we aim to (1) identify which facial affect features are pronounced when people interact with XAI interfaces, and (2) develop a multitask feature embedding for linking facial affect signals with participants' use of explanations. Our analyses and results show that the occurrence and values of facial AU1 and AU4, and Arousal are heightened when participants fail to use explanations effectively. This suggests that facial affect analysis should be incorporated into XAI to personalize explanations to individuals' interaction styles and to adapt explanations based on the difficulty of the task performed.